JS学习笔记-21-正则表达式 入门到精通
文章目录
- 一、知识储备:字符串的基本操作
- 1.1 search()
- 1.2 subString()
- 1.3 charAt()
- 1.4 split()
- 1.5 练习题 找出所有的数字
- 二、正则表达式
- 2.1 什么是正则表达式?
- 2.2 语法
- 2.2.1 JS风格语法:
- 2.2.2 perl风格语法:
- 2.3 search 返回匹配的下标
- 2.3.1 忽略大小写
- 2.4 找出第一个数字的下标
- 2.5 match 全部提取
- 2.5.1 匹配所有的数字,与不匹配所有的数字
- 2.6 replace 替换
- 2.6.1 实例:敏感词过滤
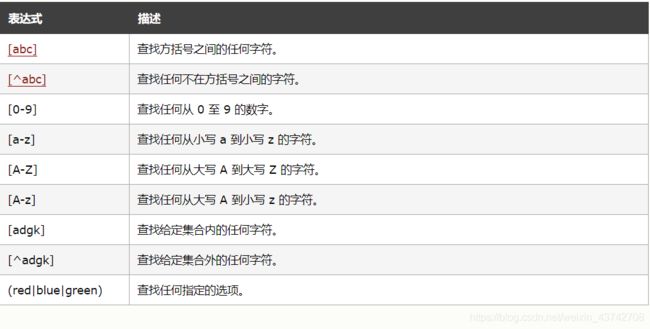
- 三、方括号
- 3.1 查找方括号之间的字符
- 3.2 ^ 匹配不在方括号内的字符
- 3.3 匹配任意字符
- 3.4 实例:偷小说
- 四、元字符(转义字符)
- 4.1 转义字符一览表
- 4.2 常用的转义字符
- 五、量词
- 5.1 量词一览表
- 5.2 基本用法
- 5.2.1 正好出现n次
- 5.2.2 正则表达式 匹配qq号;
- 5.2.3 最少n次,最多不限
- 5.2.4 ? 正则表达式 匹配固定电话的区号
- 5.2.5 *号 可以有,可以没有,也可以无限多(不推介使用)
- 六、正则表达式 匹配邮箱
- 6.1 test() 方法以及问题
引言:正则表达式与我们的字符串操作是密不可分的,因此我们在学习正则表达式之前,先来学习一下几个基本的字符串操作。
一、知识储备:字符串的基本操作
1.1 search()
语法:string.search(searchvalue)
search() 方法用于检索字符串中指定的子字符串,返回该子字符串首次出现的位置
或检索与正则表达式相匹配的子字符串。
如果没有找到任何匹配的子串,则返回 -1。
var str = 'abcdef';
alert(str.search('b'));//1
alert(str.search('e'));//4
alert(str.search('u'));//-1
1.2 subString()
语法:string.substring(from, to)
substring() 方法用于提取字符串中介于两个指定下标之间的字符。
substring() 方法返回的子串包括 开始 处的字符,但不包括结束 处的字符。
如果省略第二个参数,则从第一个参数匹配到末尾
var str = 'abcdef';
alert(str.substring(2,5));//cde
alert(str.substring(1));//bcdef
1.3 charAt()
语法:string.charAt(index)
charAt() 方法可返回指定位置的字符。
第一个字符位置为 0, 第二个字符位置为 1,以此类推.
var str = 'abcdef';
alert(str.charAt(0));//a
alert(str.charAt(3));//d
1.4 split()
语法:string.split(separator,limit)

定义: split() 方法用于把一个字符串分割成字符串数组。
提示: 如果把空字符串 ("") 用作 separator,那么 stringObject 中的每个字符之间都会被分割。
注意: split() 方法不改变原始字符串, 返回值是一个数组 。
var str = '12-56-aaa-89-va';
var arr = str.split('-');
var arr2 = str.split('');
alert(arr);// 12,56,aaa,89,va
alert(arr2);// 1,2,-,5,6,-,a,a,a,-,8,9,-,v,a
1.5 练习题 找出所有的数字
找出下列字符串当中的数字:
var str = '12abc34 edge89 321 +-=== fdef5t 465';
解决方法:
<script>
var str = '12abc34 edge89 321 +-=== fdef5t 465';
var tmp='';
var arr=[];
for(var i=0;i<str.length;i++){
if(str.charAt(i)>='0' && str.charAt(i)<='9'){
tmp += str.charAt(i);
//arr.push(str.charAt(i))//这样是取单独的一个数字
}else{
if(tmp){
arr.push(tmp);
tmp='';
}
}
}
if(tmp){
arr.push(tmp)
tmp='';
}
console.log(arr);//(6) ["12", "34", "89", "321", "5", "465"]
</script>
可以发现我们的代码比较的冗长,而且还挺麻烦。
现在就是该我们正则表达式出场的时候了!
使用下面的正则即可实现同样的功能,并且我们的代码极大的缩短了长度。
<script>
var str = '12abc34 edge89 321 +-=== fdef5t 465';
alert(str.match(/\d+/g));//12,34,89,321,5,465
</script>
接下来我们开始进入 正则表达式的坟墓吧!
二、正则表达式
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。
搜索模式可用于文本搜索和文本替换。
2.1 什么是正则表达式?
正则表达式是由一个字符序列形成的搜索模式。
当你在文本中搜索数据时,你可以用搜索模式来描述你要查询的内容。
正则表达式可以是一个简单的字符,或一个更复杂的模式。
正则表达式可用于所有文本搜索和文本替换的操作。
2.2 语法
正则表达式分为两种语法:
- JS风格语法
- perl风格语法
参考链接 :修饰符、方括号、量词等参考链接
2.2.1 JS风格语法:
创建 RegExp 对象的语法:
var re = new RegExp(pattern, attributes);
参数:
pattern: 是一个字符串,指定了正则表达式的模式或其他正则表达式。
attributes: 是一个可选的字符串,包含属性 “g”、“i” 和 “m”,分别用于指定全局匹配、区分大小写的匹配和多行匹配。
//下面这个列子的含义就是一个a,就是a本身
var re = new RegExp('a');
var str = 'abcdef';
alert(str.search(re));//0
2.2.2 perl风格语法:
/正则表达式主体/修饰符(可选)
var patt = /runoob/i
实例解析:
/runoob/i 是一个正则表达式。
runoob 是一个正则表达式主体 (用于检索)。
i 是一个修饰符 (搜索不区分大小写)。
2.3 search 返回匹配的下标
search() 方法使用正则表达式
使用正则表达式搜索 “Runoob” 字符串,且不区分大小写:
var str = "Visit Runoob!";
var n = str.search(/Runoob/i);//6
2.3.1 忽略大小写
//i 忽略大小写
//JS风格写法:
// var re = new RegExp('q','i');
//perl风格方法:
var re = /q/i;
var str = 'AbCdEfGhIJkLmoP Q rS Tu';
alert(str.search(re));//16
2.4 找出第一个数字的下标
知识点:\d 查找数字 \D 查找非数字字符
var str ='AbcDef1321 4454fs 321sf5';
var re = /\d/;
alert(str.search(re));//6
2.5 match 全部提取
作用:把所有匹配的东西,全部提取出来
g:全局匹配
+:匹配任何包含至少一个 n 的字符串(匹配若干个)。
2.5.1 匹配所有的数字,与不匹配所有的数字
var str ='AbcDef1321 4454fs 321sf5';
var re1 = /\d/;
var re2 = /\d+/;
var re3 = /\d/g;
var re4 = /\d+/g;
var re5=/\d\d/;
var re6=/\d\d/g;
alert(str.match(re1)); // 1
alert(str.match(re2)); // 1321
alert(str.match(re3)); // 1,3,2,1,4,4,5,4,3,2,1,5
alert(str.match(re4)); // 1321,4454,321,5
alert(str.match(re5)); // 13
alert(str.match(re6)); // 13,21,44,54,32
var re1 = /\D/;
var re2 = /\D+/;
var re3 = /\D/g;
var re4 = /\D+/g;
alert(str.match(re1));
alert(str.match(re2));
alert(str.match(re3));
alert(str.match(re4));
2.6 replace 替换
假如我们现在有一个字符串,想把里边的所有a都替换成0,那么原始方法:
var str = 'abc aaa dow';
alert(str.replace('a','0'));//0bc aaa dow
我们发现只能替换第一个,这个时候就需要我们的正则出场了!
var str = 'abc aaa dow';
var re = /a/g;
alert(str.replace(re,'0'));//0bc 000 dow
可以发现非常的方便!
2.6.1 实例:敏感词过滤
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>敏感词过滤title>
<script>
window.onload=function(){
var text1 = document.getElementById('txt1');
var text2 = document.getElementById('txt2');
var btn = document.getElementById('btn');
btn.onclick=function(){
var re = /北京|淘宝|百度/g;
text2.value=text1.value.replace(re,'*');
}
}
script>
head>
<body>
<textarea id="txt1" cols="30" rows="10">textarea>
<input type="button" value="过滤" id="btn">
<textarea id="txt2" cols="30" rows="10">textarea>
body>
html>
效果:
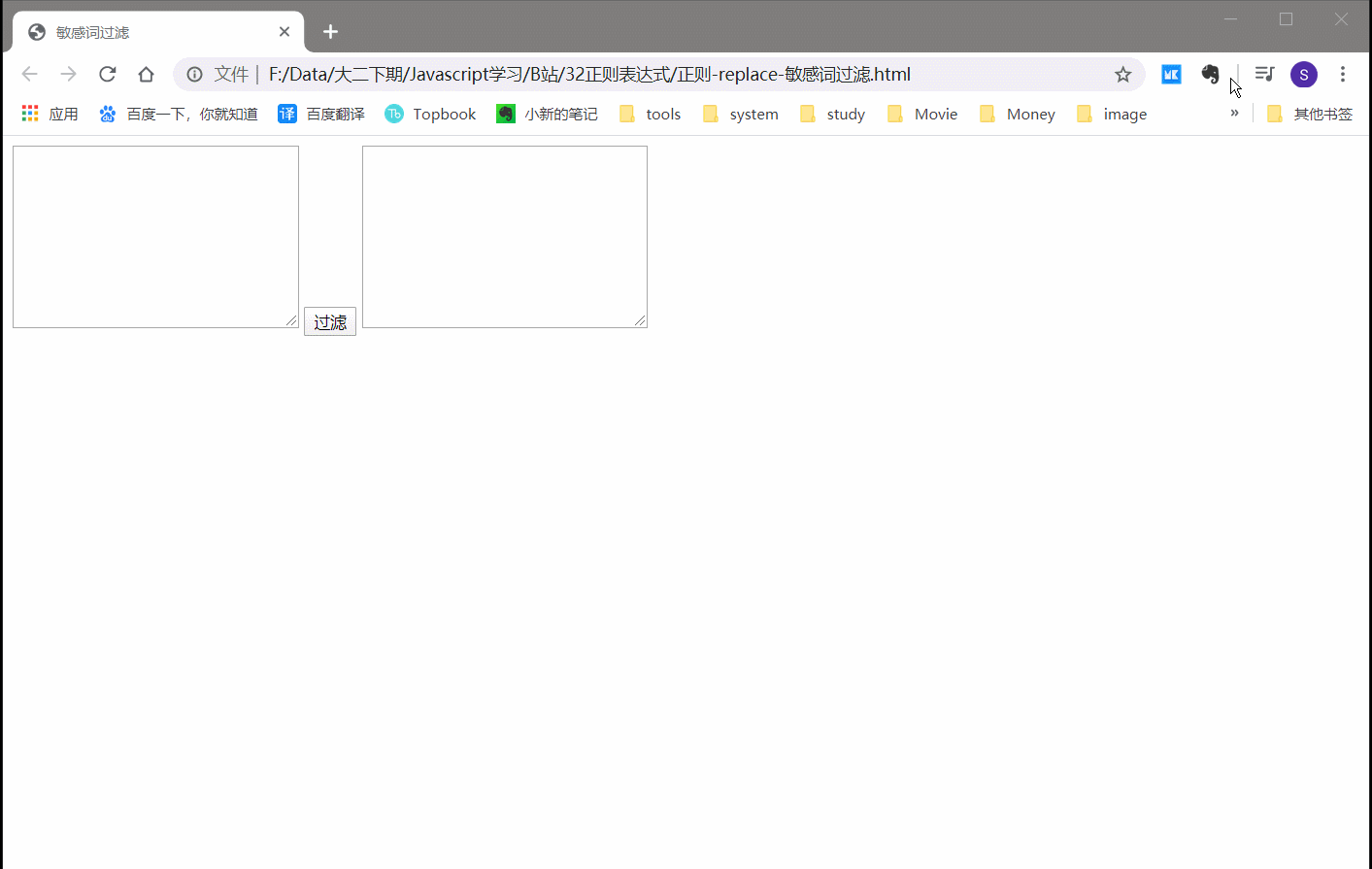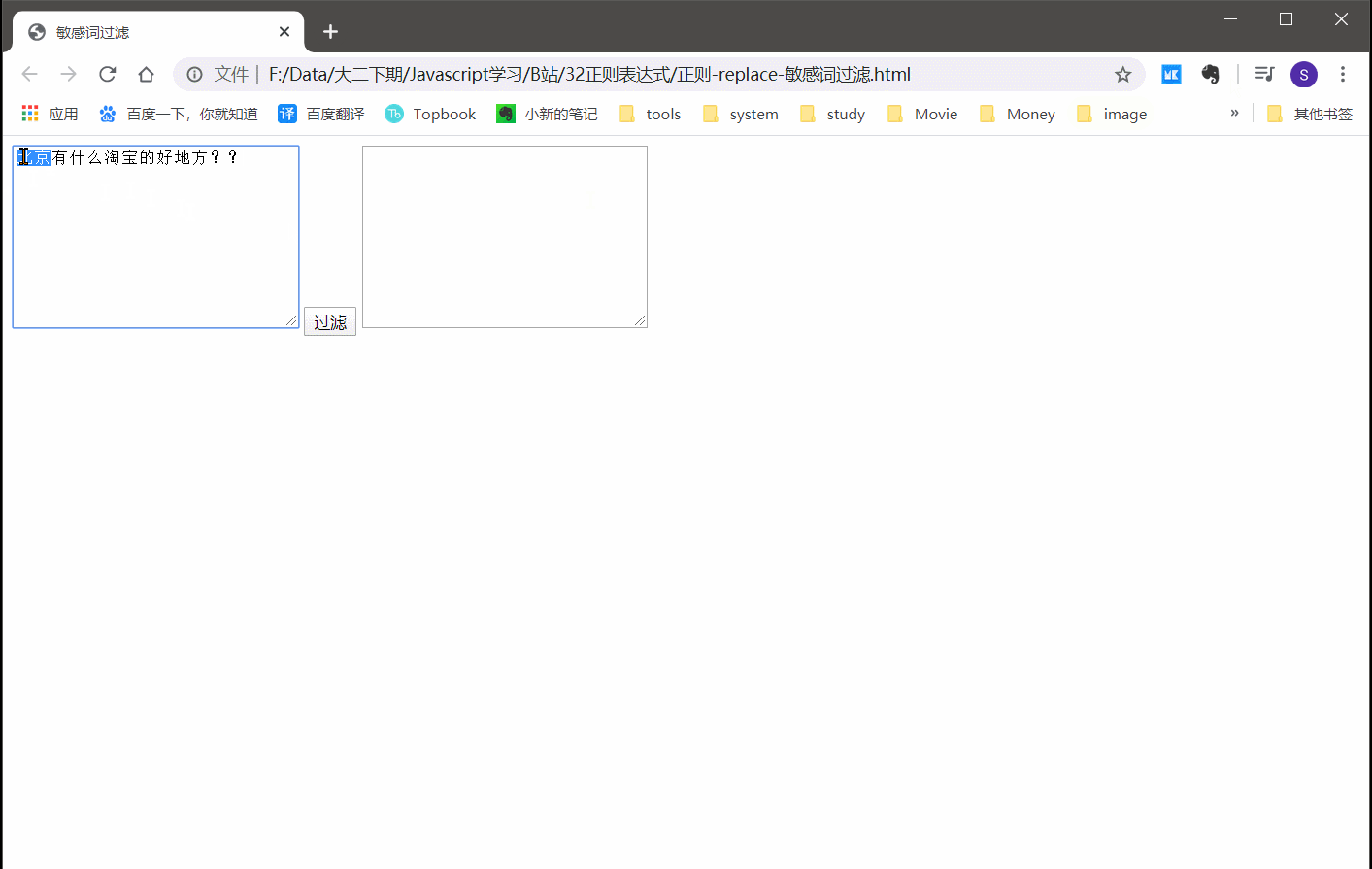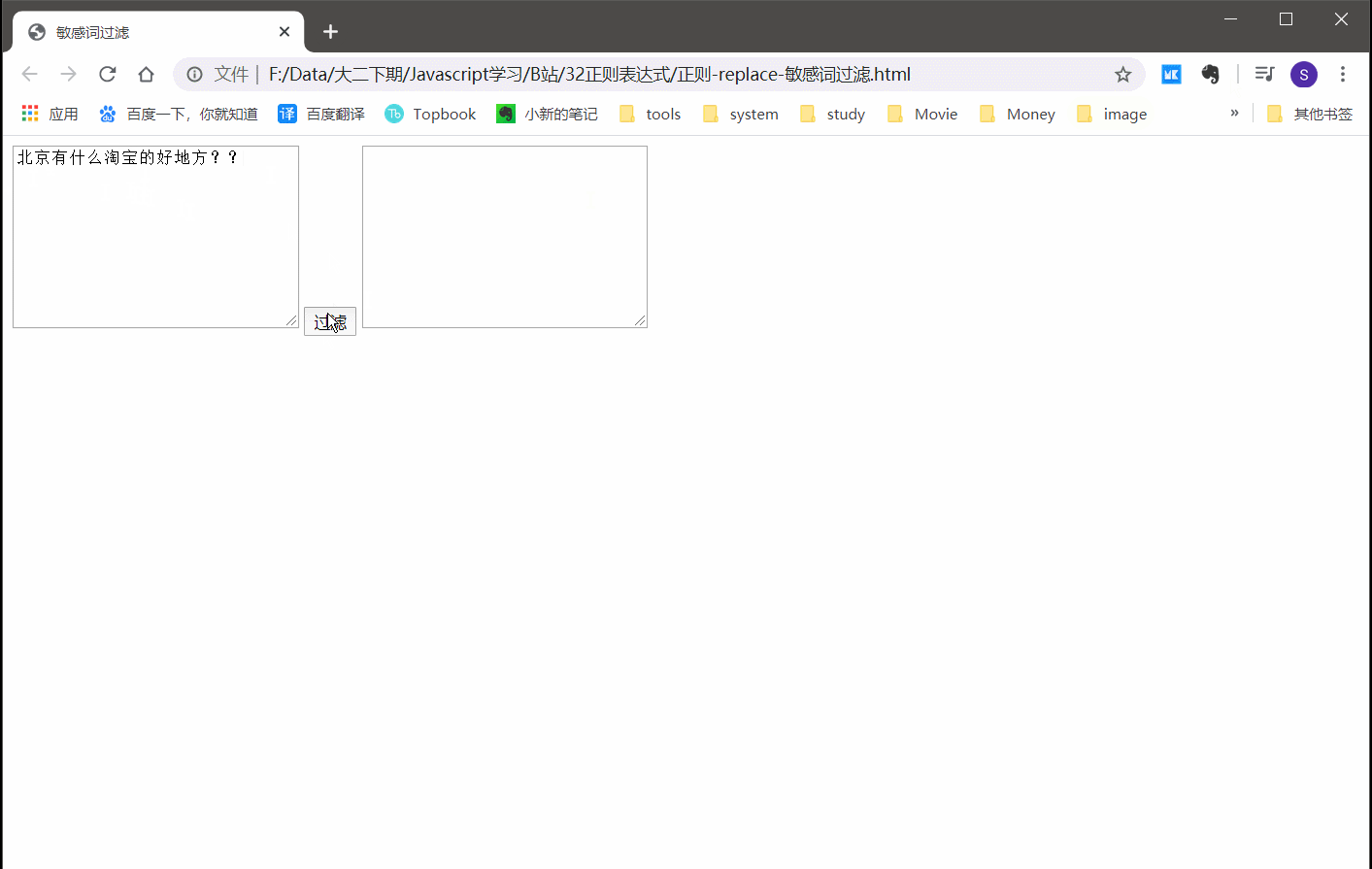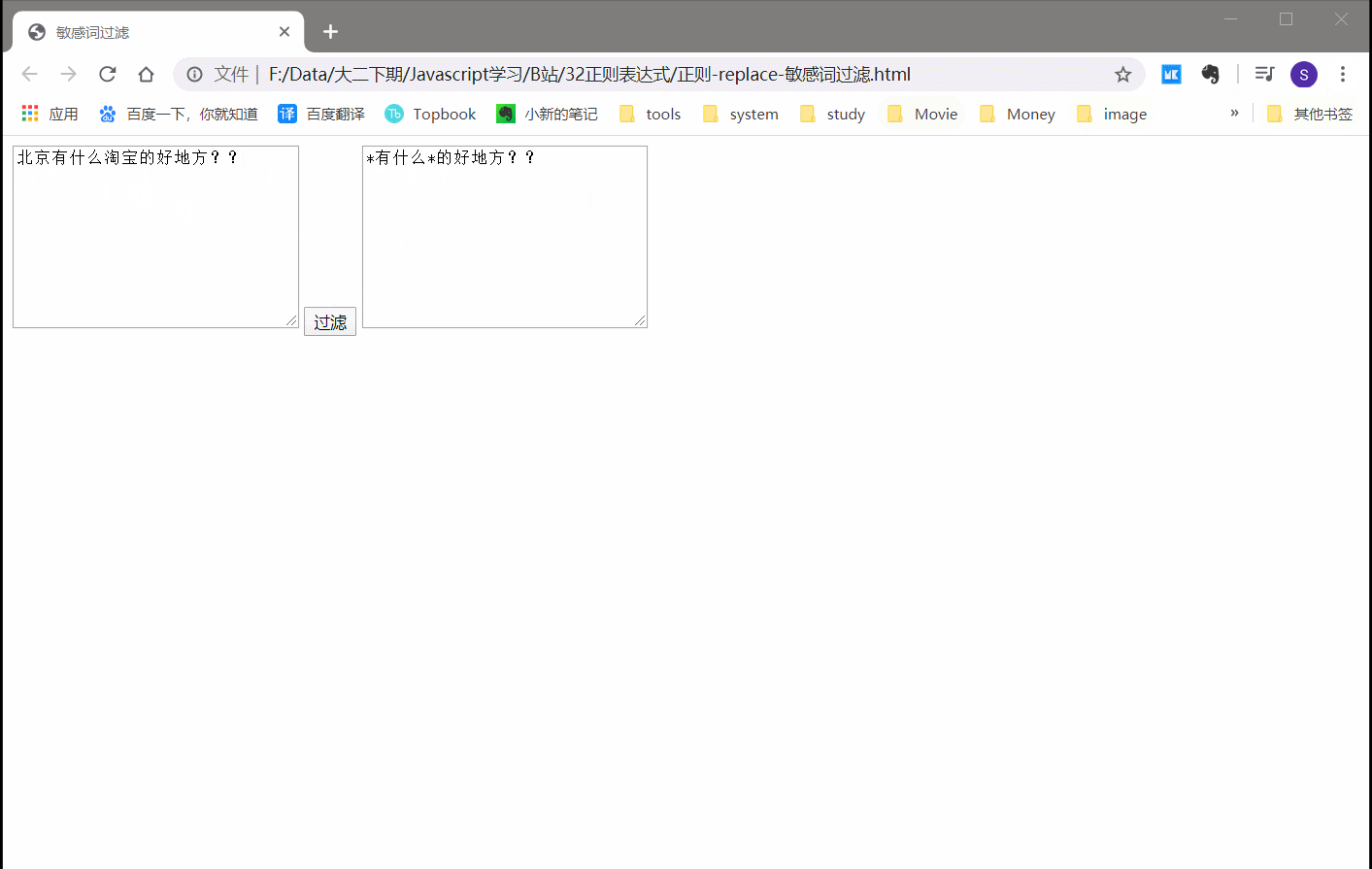
效果还是挺不错的!
三、方括号
[abc]pc:可以匹配 apc bpc cpc
3.1 查找方括号之间的字符
var str = 'apc bpc cpc dpc cpd cpp bapcd';
var re = /[abc]pc/g;
alert(str.match(re));//apc,bpc,cpc,apc
查找方括号范围之间的字符:
var str = 'apc Bpc Cpc dpc cpd cpp bapcd';
var re = /[a-z]pc/gi;
alert(str.match(re));//apc,Bpc,Cpc,dpc,apc
找出所有的数字:
之前我们写过一个列子 (2.5.1) ,现在我们可以使用方括号来该写那个例子,效果是一模一样的。
var str ='AbcDef1321 4454fs 321sf5';
var re = /[0-9]+/g;
alert(str.match(re));//1321,4454,321,5
3.2 ^ 匹配不在方括号内的字符
var str ='AbcDef1321 4454fs 321sf5';
var re = /[^0-9]+/g;
alert(str.match(re));//AbcDef, ,fs ,sf
当然,还可以组合起来用:
var str ='AbcDef1321 4454fs +-*/ 321sf5';
var re = /[^0-9a-z]+/gi;
alert(str.match(re));// , +-*/
3.3 匹配任意字符
var str ='AbcDef1321 4454fs +-*/ 321sf5';
var re = /./g;
alert(str.match(re));//A,b,c,D,e,f,1,3,2,1, ,4,4,5,4,f,s, ,+,-,*,/, ,3,2,1,s,f,5
3.4 实例:偷小说
获取小说网站的文本,屏蔽掉例如 P br hr 等等标签
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>过滤HTMl标签</title>
<script>
window.onload=function(){
var txt1 = document.getElementById('txt1');
var txt2=document.getElementById('txt2');
var btn =document.getElementById('btn');
btn.onclick=function(){
//只能过滤 <> 标签里边带有字母的标签
// var re = /<[a-z]+>/gi;
//除了不能过滤空的<>标签,其他都可以过滤
var re = /<[^<>]+>/g;
txt2.value=txt1.value.replace(re,'');
};
}
</script>
</head>
<body>
<textarea id="txt1" cols="50" rows="30"></textarea>
<input type="button" value="转换" id="btn">
<textarea id="txt2" cols="50" rows="30"></textarea>
</body>
</html>
效果:
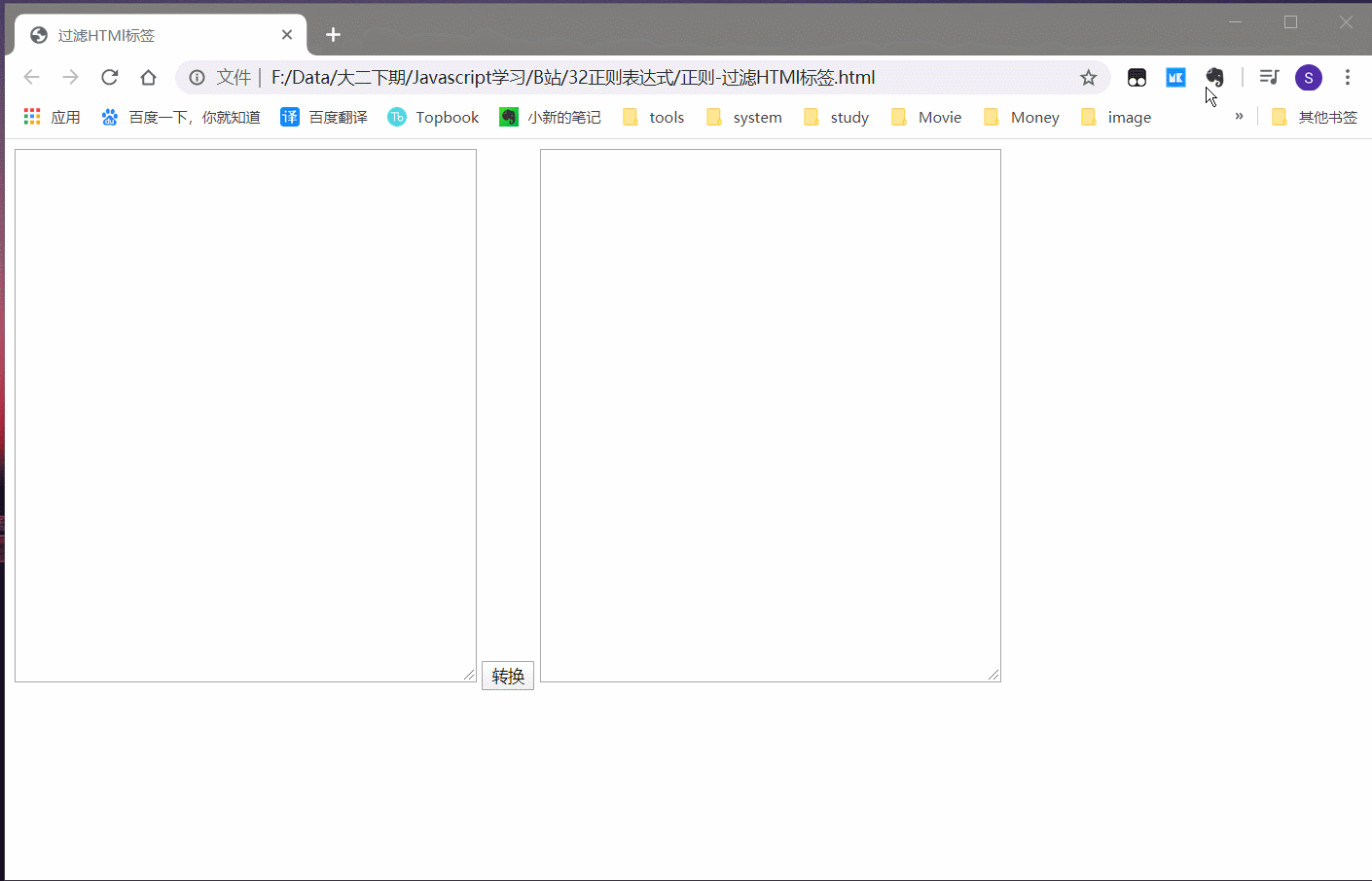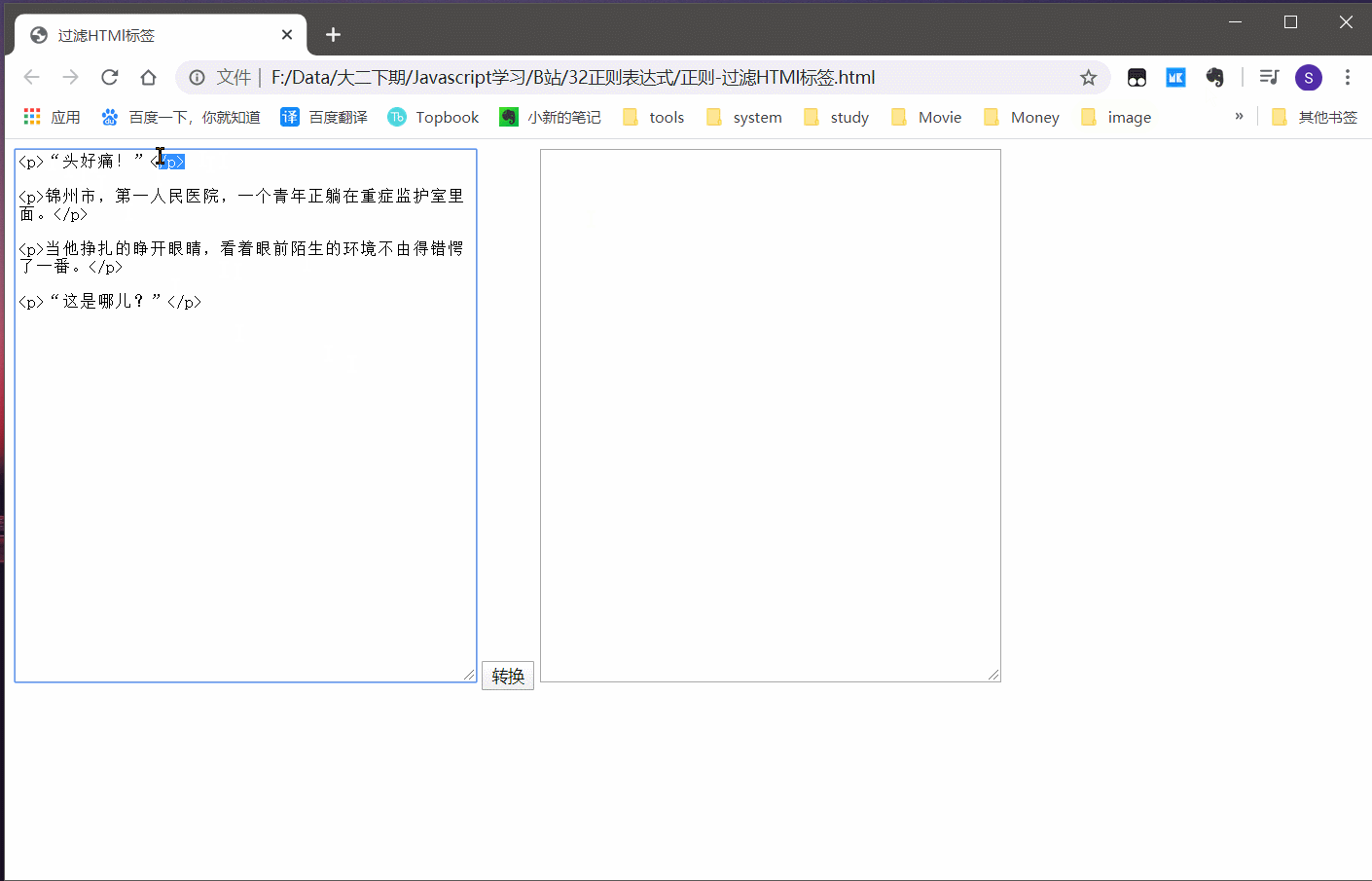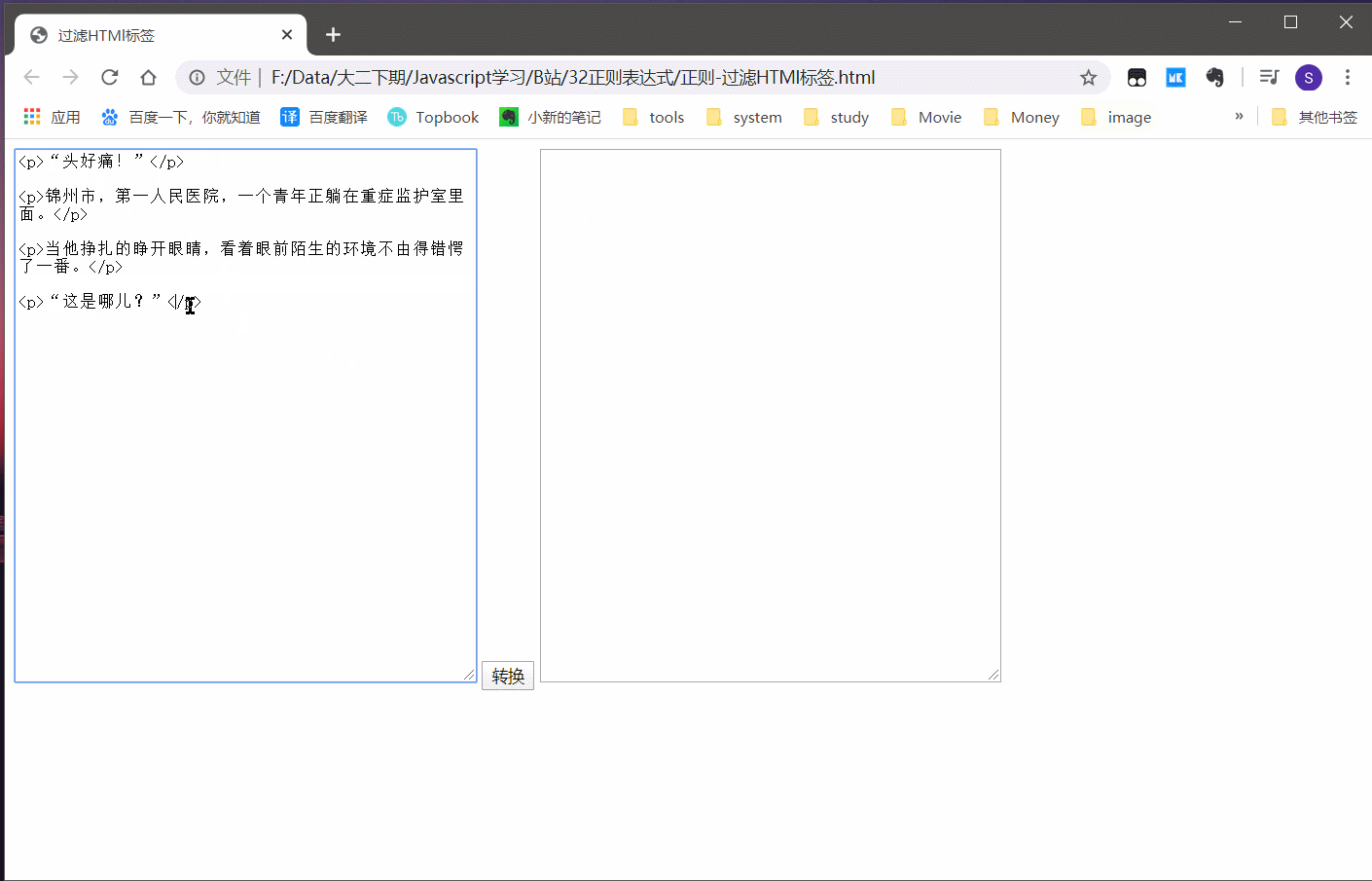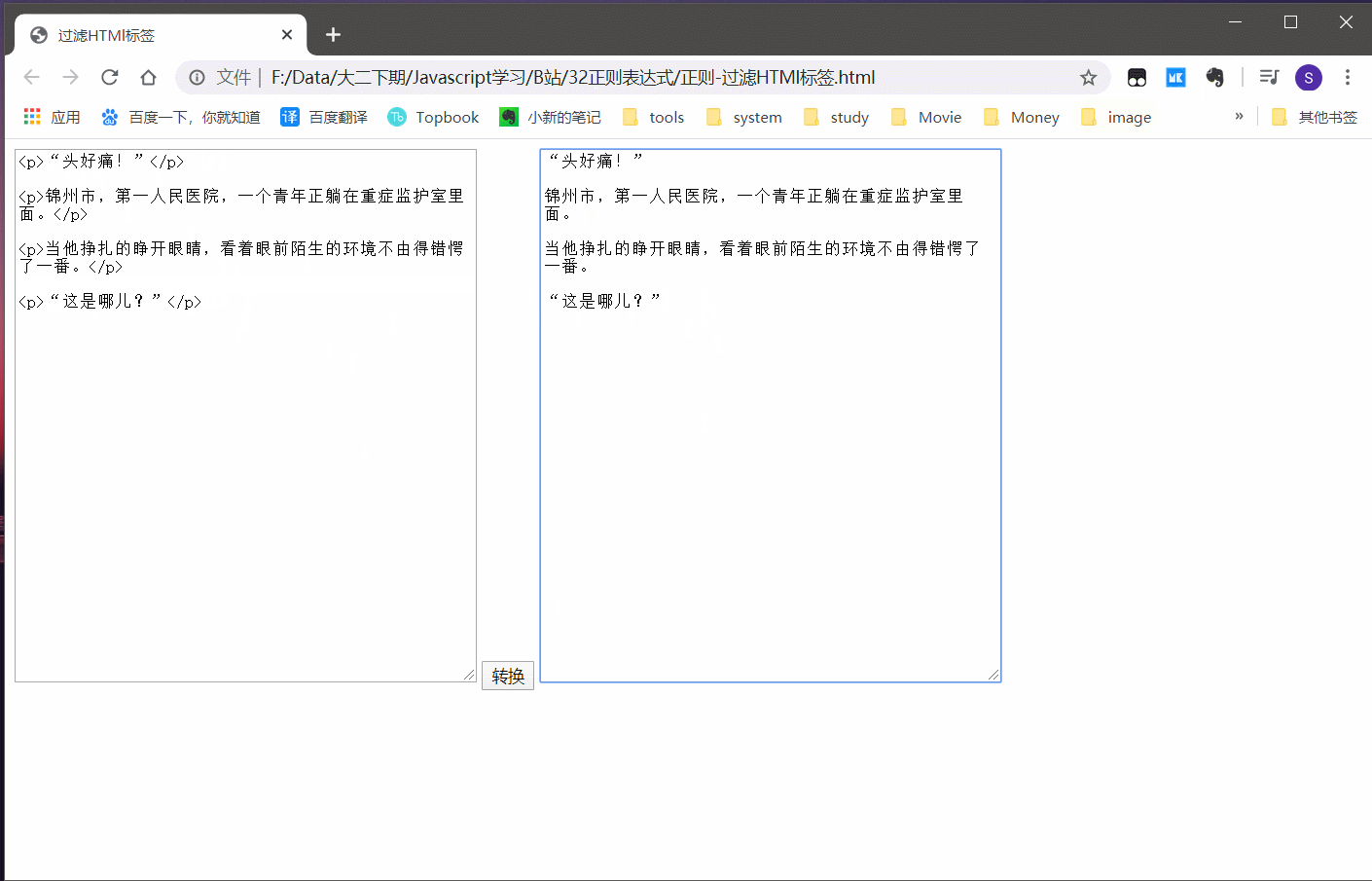
可以发现功能还是基本实现了的。
四、元字符(转义字符)
元字符(Metacharacter)是拥有特殊含义的字符:
4.1 转义字符一览表

4.2 常用的转义字符
\d意为匹配 数字 等同于 [0-9]
\w意为匹配 英文、数字、下划线 等同于 [a-z0-9_]
\s匹配空白字符 space tab 等
\D等同于[^0-9]
\w等同于 [^a-z0-9_]
\s匹配非空白字符串
五、量词
量词 说的简单一点就是 个数

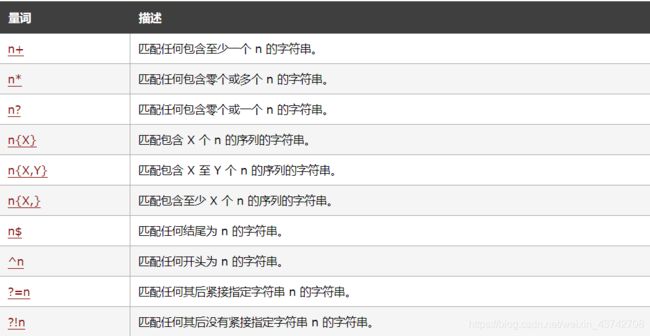
5.1 量词一览表
5.2 基本用法
5.2.1 正好出现n次
{n}正好出现n次
我们可以用它来匹配一下手机号,普通的手机号码都是11位的,这里我们呢就可以这么写:
let re = /\d{11}/;
但是我们这么写是有问题的,因为:01234567891 这样是不是也可以啊,但是实际生活中不能有0开头的电话号码,所以要改进一下:
let re=/[1-9]\d{10}/;
这样就可以啦,第一位只能是1-9 然后,后边再随便跟上10位数字。
5.2.2 正则表达式 匹配qq号;
例如:
{n,m}最少出现n次,最多出现m次;
let re =/[1-9]\d{4,11}/;
但是,请注意这样写是有问题的,由于正则表达式的贪婪性:只要有部分满足,那么就都满足
12345abcedef 这个字符串,上边的正则也能通过。
所以我们要改进一下:
let re =/s[1-9]\d{4,11}$/;
这样就可以啦,意为从这个字符串的开头到结尾只能出现正则里边规定的东西
5.2.3 最少n次,最多不限
{n,}最少出现n次,最多不限;
这里呢,也就顺便提一下,那个+号 等价于{1,}
5.2.4 ? 正则表达式 匹配固定电话的区号
?最少0次,最多一次
?等价于 [0,1];
固定电话的区号,可以这么写:
例如:0830-7050138
let re = /s(0\d{3}-)?[1-9]\d{7}$/;
- ? 也就是可以有(只能有一次),可以没有
- () 括号在这里的意思和JS里边一样,就是分组,把里边的东西分一组
- - 在这里的意思就是普通的字符串 - 类似于 一个a这样的
- ^ 符号不出现在 [] 里边的时候,代表 行首
- $ 符号代表 行尾
5.2.5 *号 可以有,可以没有,也可以无限多(不推介使用)
*相当于 [0,]
六、正则表达式 匹配邮箱
我们先来分析一下,邮箱的格式就是下边这类规则构成的:
一串英文、数字、下划线 @ 一串英文、数字 . 一串英文
\w+ 就是英文、数字、下划线
@ 就是@
[a-z0-9] 英文、数字
\. 转义成.
[a-z]+
那么我们整合一下,完整代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>校验邮箱</title>
<script>
window.onload=function(){
var text = document.querySelector('#text');
var btn = document.querySelector('#btn');
btn.onclick=function(){
// \w+ @ [a-z0-9]+ \. [a-z]+
let re=/\w+@[a-z0-9]+\.[a-z]+/i;
if(re.test(text.value)){
alert('合法的邮箱!');
}else{
alert('你丫写错了!');
}
};
}
</script>
</head>
<body>
<input type="text" id="text">
<input type="button" id="btn" value="检验">
</body>
</html>
6.1 test() 方法以及问题
上边我们那么写的话,会出问题,问题在于tset
tes方法:
test() 方法用于检测一个字符串是否匹配某个模式.
如果字符串中 有匹配的值 返回 true ,否则返回 false。
也就是说test检验的正则表达式当中只要有一部分满足要求就返回 true,这可不行,对吧,这会出大问题。
那么怎么解决呢?
解决方法其实也很简单:
我们先来了解两个知识点
- ^ 符号不出现在 [] 里边的时候,代表 行首
- $ 符号代表 行尾
我们把这两个符号加在正则表达式的两边即可!
把这两个符号加在行首与行尾的作用是什么呢,
意思是说: 从这个字符串的开头到结尾只能出现正则里边规定的东西
let re=/^\w+@[a-z0-9]+\.[a-z]+$/i;
本文到这里就结束了,文章当中如果有什么不对的地方,请留言或者私信,笔者会第一时间修改。
如果您觉的还不错的话,请点赞支持一下笔者,毕竟创作不易。