Spark2.x在Idea中运行在远程集群中并进行调试
方法1
把自己的电脑作为Driver端,直接把jar包提交到集群,此时Spark的Master与Worker会一直和本机的Driver端保持连接,调试比较方便。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SparkTest")
//设置Master_IP
.setMaster("spark://1.185.74.124:7077")
//提交的jar包在你本机上的位置
.setJars(List("C:\\Users\\Administrator\\IdeaProjects\\Spark2.1.0\\out\\artifacts\\Spark2_1_0_jar\\Spark2.1.0.jar"))
//设置driver端的ip,这里是你本机的ip
.setIfMissing("spark.driver.host", "172.18.18.114")
val sc = new SparkContext(sparkConf)
println("SparkTest...")
sc.stop
}效果图:

方法2
1.导入依赖的包和源码
在下载spark中到的导入spark的相关依赖了包和其源码.zip
2.使用官方求Pi的例子
import org.apache.spark.{SparkConf, SparkContext}
object FirstDemo {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi")
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = Math.random * 2 - 1
val y = Math.random * 2 - 1
if (x * x + y * y < 1) 1 else 0
}.reduce(_ + _)
println("*****Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}3.导出项目jar包
确认之后->build->build artifacts->rebuild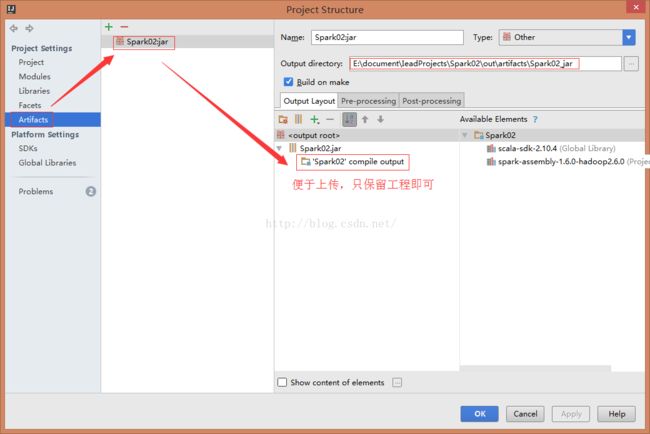
4.启动集群
先修改配置文件,再启动集群可能会导致master无法正常启动,下次想取消远程调试,可以把配置文件再改回来
[root@master sbin]# jps
30212 SecondaryNameNode
32437 -- main class information unavailable
30028 NameNode所以请先启动集群
[root@master sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /hadoop/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave01: starting org.apache.spark.deploy.worker.Worker, logging to /hadoop/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave01.out5.修改配置文件spark-class
spark-class在SPARK_HOME/bin下
done < <("$RUNNER" -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@")
修改成
done < <("$RUNNER" -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main $JAVA_OPTS "$@")
$JAVA_OPTS 为我们添加的参数,下面在命令行中为其声明(建议写到配置文件中)
export JAVA_OPTS="$JAVA_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005
6.提交Spark,开启端口监听
上传之前生成的jar包到master节点,在命令行中执行
spark-submit --master spark://master:7077 --class FirstDemo Spark02.jar
出现如下结果,表示master正在监听5005端口
[root@master ~]# spark-submit --master spark://master:7077 --class FirstDemo Spark02.jar
Listening for transport dt_socket at address: 50057.Idea配置远程

添加Remote组件,填写master的ip的监听端口

8.启动调试
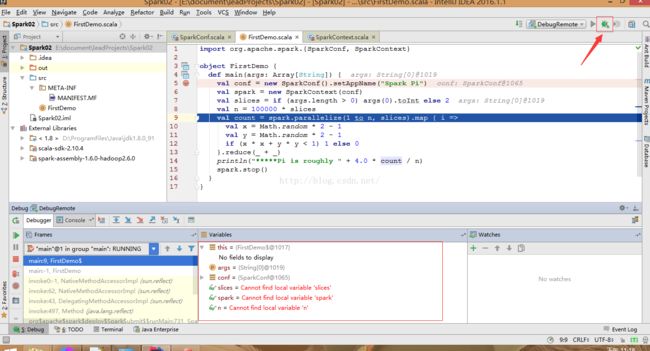
JAVA_OPTS参数说明:
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005
参数说明:
-Xdebug 启用调试特性
-Xrunjdwp 启用JDWP实现,包含若干子选项:
transport=dt_socket JPDA front-end和back-end之间的传输方法。dt_socket表示使用套接字传输。
address=5005 JVM在5005端口上监听请求,这个设定为一个不冲突的端口即可。
server=y y表示启动的JVM是被调试者。如果为n,则表示启动的JVM是调试器。
suspend=y y表示启动的JVM会暂停等待,直到调试器连接上才继续执行。suspend=n,则JVM不会暂停等待。