Elasticsearch笔记(十六) routing refresh version 参数详解
Elasticsearch Index API 参数详解
- 1. index
- 1.1 index作为名词
- 1.2 index作为动词
- 2. index的格式
- 2.1 PUT和POST区别
- 2.1.1 区别一
- 2.1.2 区别二
- 2.2 _create作用
- 3. index的参数
- 3.1 routing
- 3.1.1 根据文档ID查找
- 3.1.2 自定义路由
- 3.2 timeout
- 3.3 refresh
- 3.3 version
- 3.4 version_type
- 3.5 if_seq_no & if_primary_term
1. index
1.1 index作为名词
index就像MySQL中表名,可以给index设置很多字段,并指定字段的类型(字符,数字,日期等)。之前老版本ES还可设置不同type,现在已去掉。
1.2 index作为动词
- 作为动词,index就是往ES中写入的数据,类似MySQL的insert和update。
- index操作把JSON文档写入ES,然后该JSON文档可被检索了。
- 如果该文档已经存在(id相同),会修改该文档,然后version版本号+1。
2. index的格式
- PUT /
/_doc/<_id> - POST /
/_doc/ - PUT /
/_create/<_id> - POST /
/_create/<_id>
上面4个是index操作的格式,
填index的名称 - <_id> 填文档的ID
- _docs是默认type名称。
- _create是指定是新建文档操作。
PUT和POST的实例代码看我博客Elasticsearch笔记(一) Query DSL入门
2.1 PUT和POST区别
前面2个操作如下,可以看出PUT带了<_id>,而POST没有。
- PUT /
/_doc/<_id> - POST /
/_doc/
2.1.1 区别一
- 当想使用我们自己指定的ID时,需要用PUT。
- 当想让ES给我们自动生成文档ID时,得用POST。
2.1.2 区别二
如果指定ID的文档已经存在时,PUT和POST有如下区别:
- PUT是跟新整个文档,它先根据ID删除文档,然后再写入新文档。
- POST是局部跟新文档,原来没有的字段会新增,已有的字段会修改。
2.2 _create作用
- PUT /
/_create/<_id> - POST /
/_create/<_id>
上面的_create指定该操作是新建文档,如果参数<_id>的文档已经存在,则会返回操作失败。
3. index的参数
3.1 routing
在生产环境,一个index是被分为多个各分片的,路由机制和分片机制密切相关。
举例有一个index,它被分3个分片,每个分片各有一个副本。如下图
- 主分片P0,P1,P2
- 副分片R0,R1,R2
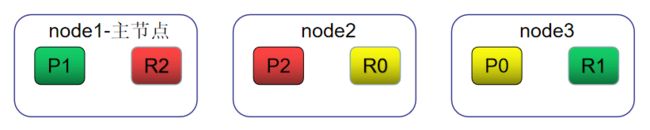
在index数据不指定routing时,ES默认用文档的ID来作为路由计算值,计算公式如下:
shard = hash(routing) % number_of_primary_shards
number_of_primary_shards是主分片数,这里就是3。对文档ID进行hash,再除以3,得到的余数肯定是0,1,2之间的数,对应主分片P0,P1,P2。这样起到了负载均衡的效果,使得每个分片里文档的数量理想情况下是几乎一样的。
举例ID=”abc“,shard = hash(“abc”) % 3 = 2,则把文档存到分片P2上。
3.1.1 根据文档ID查找
举例ID=”abc“,shard = hash(“abc”) % 3 = 2,则把这次查询发往分片P2上,因为插入时,ID=“abc”的数据就存在分片2上。这样就解释了index一旦创建好,主分片参数number_of_primary_shards是不能修改的,如果后期修改了它,查询时计算出的分片号和存入时分片号就不一致了。
3.1.2 自定义路由
如果不是根据文档ID查找,而是根据别的查询条件找,那默认是把请求发给所有的分片上,然后把每个分片的查询结果在协调节点上聚合,然后再给客户端最终结果。想想如果分片数很多,这样是很消耗系统系能的。
如果我们存数据时指定了路由routing参数,查询数据时也指定相同的routing参数,这样就会发给那一个分片,这样提高了查询效率,不用给每个分片发请求了。
PUT /pigg/_doc/100?routing=dept1
{
"name": "winter",
"dept": "dept1"
}
PUT /pigg/_doc/101?routing=dept1
{
"name": "dong",
"dept": "dept1"
}
查询时指定routing
GET /pigg/_search?routing=dept1
{
"query": {
"term": {
"dept.keyword": {
"value": "dept1"
}
}
}
}
注意使用routing时,这个和业务数据是相关联的,一定要考虑到业务数据的特性。
例如routing=dept1的有10万条,routing=dept2的数据只有1千条,那么10万条数据在一个分片上,1千条数据在另一个分片上,这样导致了数据倾斜。
3.2 timeout
当index操作时,可能主分片不可用,例如此时主分片正在恢复中,或在重定向。这个时候index操作就得等待主分片可用,默认这个等待时间是1分钟,当然也可以自定义。
等待主分片10秒
PUT /pigg/_doc/102?timeout=10s
{
"name": "dong2",
"dept": "dept1"
}
3.3 refresh
刚学ES时,都知道ES是一个近实时系统,写入的数据要约1秒后才能查询到。
refresh可以设置3种值,指定刷新行为。
ES的JavaAPI里定义了refresh的枚举如下:
public static enum RefreshPolicy implements Writeable {
NONE("false"),
IMMEDIATE("true"),
WAIT_UNTIL("wait_for");
//省略别的代码
}
它有false,true,wait_for三个值,ES默认是false。
(1)refresh = false
index后,不进行相关刷新操作,等待一定时间(约1秒),修改的数据可被查询到,ES默认这个。
(2)refresh = true
- index后,立即刷新相关的主碎片和副本碎片(不是整个索引),以便可以立即搜索到修改后的文档。这样看着挺好,但是有不足的,否则ES也不会默认1S后可查询了。
- 如果频率的执行refresh=true的操作,会生成很多小的段文件,这也会给后期段文件的合并增加处理时间,因而会影响搜索效率,这样就得不偿失。
- 这个要谨慎考虑设置为true。
(3)refresh = wait_for
wait_for顾名思义,就是等待请求所做的更改被刷新可见。
对于在生产环境中,一般还是使用默认的配置refresh = false,很少有理由去设置refresh为别的,在技术选型时用ES了,也就得考虑到ES只是近实时,不是完全实时的。
3.3 version
每个文档都有一个版本号version,新增后version=1,以后每次修改,version自动加1,也可以指定version,比如让它从1一下子变成10这样。
#先新增一个ID=100的文档
PUT /pigg/_doc/100
{
"name": "三爷"
}
#返回结果如下,注意这个版本号_version=1
{
"_index" : "pigg",
"_type" : "_doc",
"_id" : "100",
"_version" : 1,//注意这个版本号
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
但我们要修改文档前,我们已经知道当前version=1,如果文档被别人修改过,那version肯定大于1。
当我们要修改时,带上version参数(值是我们认定的更新前,当前文档的version值),如果我们指定的与ES里文档相等,则能成功,否则报异常。
#指定跟新前文档现有version=1
PUT /pigg/_doc/100?version=1
{
"name": "三爷2"
}
#因为中间没有别人操作过id=100的文档,所以修改成功,version变成2
{
"_index" : "pigg",
"_type" : "_doc",
"_id" : "100",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
3.4 version_type
在指定version参数时,我们还可以指定version_type参数。它有3种类型:
| version_type | 说明 |
|---|---|
| internal | 指定的version == 当前文档的version |
| external or external_gt | 指定的version > 当前文档的version |
| external_gte | 指定的version >= 当前文档的version |
#指定了version_type=external,必须version>当前的version
PUT /pigg/_doc/100?version=10&version_type=external
{
"name": "三爷3"
}
#返回结果如下,version变成指定的10
{
"_index" : "pigg",
"_type" : "_doc",
"_id" : "100",
"_version" : 10,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
3.5 if_seq_no & if_primary_term
ES是乐观并发控制的,在ES6.7这个版本之前是用version+version_type,现在新版本的ES用if_seq_no & if_primary_term在做并发控制。
seq_no不是属于当个文档,它是属于整个index,这个和version不同,version是每个文档修改后都+1,每个文档的version相互不影响。
但是每个文档依旧有自己的seq_no值,更新一个文档时,还是用该文档的seq_no控制并发。
seq_no属于整个index,当index中任何文档修改或新增,seq_no都会+1。
例如id=1的文档创建后,seq_no=1,
那么id=2的文档创建后,seq_no=2,
再然后id=1的文档修改后,seq_no=3
再对id=2的文档修改,要并发控制,if_seq_no得=2
{
(1)创建文档获取_seq_no和_primary_term
PUT pigg/_doc/300
{
"name": "winter"
}
返回结果如下,注意看最后2个_seq_no和_primary_term
{
"_index" : "pigg",
"_type" : "_doc",
"_id" : "300",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 13,
"_primary_term" : 1
}
(2)修改时带上if_seq_no&if_primary_term
PUT pigg/_doc/300?if_seq_no=13&if_primary_term=1
{
"name": "winter1"
}
返回结果可见_seq_no加1了
{
"_index" : "pigg",
"_type" : "_doc",
"_id" : "300",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 14,//从13变成14了
"_primary_term" : 1
}
(3)模拟并发操作
再次执行相同的操作
PUT pigg/_doc/300?if_seq_no=13&if_primary_term=1
{
"name": "winter1"
}
返回报错,说seqNo已经是14了
{
"error" : {
"root_cause" : [
{
"type" : "version_conflict_engine_exception",
"reason" : "[300]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]",
"index_uuid" : "1EcXaVewTu2IFK_4OAGxIw",
"shard" : "0",
"index" : "pigg"
}
],
"type" : "version_conflict_engine_exception",
"reason" : "[300]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]",
"index_uuid" : "1EcXaVewTu2IFK_4OAGxIw",
"shard" : "0",
"index" : "pigg"
},
"status" : 409
}