MapReduce详解
1.基本介绍
1.1 MapReduce简介
MapReduce是一种编程模型,也就是说它实际上是一种概念,而Hadoop的MapReduce的框架是概念的具体实现。
它最早是由Google公司提出的,基于文件的分布式存储(GFS/HDFS)来实现对大规模数据的并行处理,并且Hadoop的作者就是从Google发的论文中受到了启发而写出目前最主流的大数据Hadoop框架。
1.2 基本概念
正如它的名字它有Map(映射)和Reduce(归约)两个主要过程。
我们可以把Map和Reduce理解为把一堆杂乱的数据按照某种特征归纳起来,然后处理得到结果,这样先对数据做特征提取,组成一定的数据格式后再让集群的机器做并行处理就会很迅速。
举个例子,现在年级主任让你统计你整个年级里卷子分数在60分以上的有多少人,如果自己一张张去数就很慢,你会把每个班的卷子分给班长,让班长算自己班的 (Map) ,然后将人数报给你(Reduce),这就是一个简单的MapReduce过程,先拆分再汇总。
2.原理
2.1 组成
前面我们提到MapReduce的是基于HDFS(也可以是别的分布式文件存储)实现的,所以它也有和HDFS一样的master-slave的主从设计
MapReduce的组成是由一个单独的 JobTracker(master) 和每个集群节点的一个 TaskTracker(slave) 共同组成,JobTracker的功能和其他框架的master节点差不多,指派,调度,监控,重新执行,而TaskTracker只负责执行JobTracker指派的任务。
2.1 总体流程
MapReduce的计算流程有六个步骤
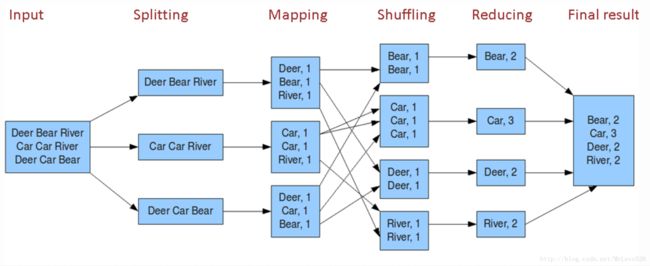
接下来对六个过程做解析
2.2 Input&&Split
这个阶段是提交作业,做一些MapReduce之前的准备工作。
- 程序通过runJob()方法新建一个JobClient实例
- 向JobTracker请求一个新的jobID,可以通过JobTracker的getNewJobId()获取
- 检查作业说明,输入路径不存在或者没有指定输出目录,作业将不会被提交,然后输入作业划分split
- 将运行作业所需要的资源(jar文件、配置文件等)复制到一个以作业ID命名的目录中
- 调用JobTracker的submitJob() 方法,告诉JobTracker作业准备提交
- JobTracker将提交作业放入内部队列中,交给作业调度器进行调度,并初始化
- 创建Map任务、Reduce任务:一个split对应一个map,Reduce的数量由JobConf的maper.reduce.tasks属性决定。
- TaskTracker执行一个简单的循环,定期发送心跳给JobTracker让其监测
可以看到Input Split阶段就是对作业做一个输入的检查、划分、并提交给具体的JobTracker。
对几个关键名次做解释。
Inputfiles
输入的原始数据,一般是存储在HDFS上,应用程序应该指明输入/输出路径,然后通过合适的接口实现map和reduce函数,跟其他配置共同组成作业配置。
InputFormat
为作业的输入细节规范。MapReduce的检查分割都是根据作业的InputFormat。
- 检查作业输入的正确性
- 把输入文件分割成多个逻辑InputSplit实例,一个对应一个Map任务。
- 根据RecordReader实现,这个RecordReader从逻辑InputSplit中获得输入记录。
InputSplits
InputSplit就是一个单独的Map任务需要处理的数据块。一般的InputSplit是字节输入,然后由RecordReader处理并转化成记录样式。
通常一个split就是一个block,这样的好处是使得Map任务可以在存储有当前数据的节点上运行本地的任务,而不需要通过http来跨节点任务调度。
Map任务开始前,会先获得文件在HDFS上的路径和block信息,然后根据splitSize对文件进行切分。
2.3 Mapper
前面已经切分好了InputSplit,接下来就是给每一个InputSplit产生一个map任务,而前面也说过一般来说一个split就是一个HDFS的block,block如果很小,那么map所占的内存不大,但是block很大的时候,就必须要有更多的内存来作为排序缓冲区 ,加速map的排序过程。
分配好map任务后就要执行,这时候需要程序员重写JobConfigurable.configure(JobConf) ,目的是完成Mapper的初始化工作。
接着调用OutputCollector.collect(WritableComparable,Writable) 可以收集map(WritableComparable,Writable,OutputCollector,Reporter) 输出的键值对,这个map函数也是开发者根据具体业务逻辑去实现的。应用程序可以使用Reporter报告进度。
2.4 Shuffling
map执行完后Map/Reudce会把一个特定key关联的所有的中间过程的值(value) 分组并排序,这个过程就是Shuffling。
分组排序之后,MapReduce就会把结果传给Reduce来产出最终的结构。分组的总数目和一个作业的reduce任务的数目是一样的,用户也可以通过自定义的Partitioner来控制具体的key分配给哪个Reducer。
内存缓冲区
MapReduce框架为InputSplit中的每个键值对调用一次map(WritableComparable,writable
,OutputConllector,Report)操作,调用一次map操作后就会得到一个新的 (key,value) 对。
但是,Map程序开始产生结果的时候并不是写到文件的,而是写到一个环形内存缓冲区 。每个map任务都有一个内存缓冲区,存储输出结果,默认是100MB。
如果map task的结果很多超过了100MB(或是我们的设定)的限制,所以需要在一定条件下将缓冲区的数据临时写入磁盘,然后重新利用缓冲区。这个写入磁盘的过程成为spill ,可译为溢写。这个过程会启动一个单独的线程而不影响map的执行。
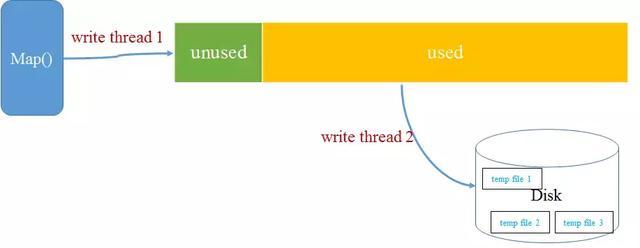
分区
在把map()输出数据写入内存缓冲区之前会先进行Partitioner操作也就是分区。
这个操作用于划分键值空间,MapReduce提供Partitioner接口,它的作用就是根据key、value或redue的数量来决定当前的这对输出数据应该交由哪个reduce task处理。具体的默认是对key hash后再以reduce task数量取模。
Partitioner操作得到的分区元数据也被存储在内存缓冲区中,当数据达到溢出的条件时,读取缓存中的数据和分区元数据,然后把属于同一分区的数据的合并到一起。对于每一个分区,都在内存中根据map输出的key进行排序,最后溢出的文件内是分区的,且分区内是有序的。
Combiner/压缩
这两个操作都是程序员去选择的,作用都是减少Map到Reduce端的数据量和传输时间
- Combiner也是一种reduce操作,但是是本地化的reduce操作,对map输出的中间文件做简单的合并重复key的操作,合并之后文件就会变小,这样就提高了传输效率
- MapReduce框架提供了压缩工具,这些工具可以为map的中间数据和作业最终输出数据提供支持,它可以压缩中间数据和应用输出来提高传输速度。
到这里map端的工作结束,reduce task不断的从JobTracker那里获取map task是否完成的信息,如果reduce task得到同志,Reducce就开始复制结果数据。
2.4 Reduce
Reduce也是第二个关键阶段,对数据做最后的整理合并。
前面提到过,reduce在执行之前会不断的拉去每个map任务的输出结果,然后对这些数据不断的做merge,最终生成一个作为reduce任务输入的输入文件。

由此得知Reduce有三个阶段,copy,merge,reduce
copy
在hadoop中,job的第一个map结束后,reduce就开始尝试从完成的map中获取结果数据,并且reduce会启动一个copy线程,通过HTTP方式来请求map对应的TaskTracker。map通常有多个,所以一个下载线程可以同时从多个map下载。
在copy的过程中,如果遇到了map的机器错误、网络中断的情况,下载就可能失败,这时候下载线程默认等待300s,如果超过了300s则放弃这次下载并尝试从另外的地方下载。
merge
这个跟map端的merge动作很类似,只不过数组中存放的是不同map端copy过来的数据。
copy来的数据先放入内存缓冲区,然后当使用内存达到一定的时候才刷入磁盘。而且这里的缓冲区大小比map端更灵活,基于JVM的heapsize设置的。
reducer
当reduce将所有的map上的数据下载完成后,就开始reduce计算阶段,那么这个reduce的函数也是需要我们去定义的,最后我们就得到了想要的计算结果。
3. 总结
3.1 MapReduce的优缺点
优点
- 易于编程
- 良好的扩展性
- 高容错性
- 适合PB级别以上的大数据的分布式离线批处理
缺点
- 难以实时计算(MapReduce处理的是存储在本地磁盘上的离线数据)
- 不能流式计算(MapReduce设计处理的数据源是静态的)
- 难以DAG计算MapReduce这些并行计算大都是基于非循环的数据流模型,也就是说,一次计算过程中,不同计算节点之间保持高度并行,这样的数据流模型使得那些需要反复使用一个特定数据集的迭代算法无法高效地运行。
3.2 总结
其实MapReduce的原理和思想还是挺容易理解的,就是一个分而治之再汇总的思想,学习起来也比较容易,而且是基于底层的HDFS的应用框架。
其次MapReduce的优缺点还是很明显的,也正是为了弥补它所不能应对的业务场景才有了后来的Spark框架,在Spark出现之前MapReduce一直是占据主导位置,几乎所有的云计算大数据都在使用它,但是人们对于实时计算,而对动态的处理能力的要求也使得MapReduce渐渐的力不从心,但是它仍然是目前主流的计算模型和框架,值得我们好好学习。