Redis如何设计解决springcache的缺陷
关于spring cache的缺陷:例如有一个缓存存放 list
这里我们可以利用Redis的一些特性来解决这个缺陷。
假设我们在Redis中缓存了系统表数据,找出年龄大于25,且性别是男的用户。这时候我们可以这样做:
先定义几个常量字段:
static final String SYS_USER_TABLE = "SYS_USER_TABLE";
static final String SYS_USER_AGE_25 = "SYS_USER_AGE_25";
static final String SYS_USER_SEX_M = "SYS_USER_SEX_M";然后构造出这几个用户:
HashMap map = new HashMap();
String uid = UUID.randomUUID().toString();
User u1 = new User(uid, "小1", "M", 25);
map.put(uid,JSON.toJSONString(u1));
jedis.sadd(SYS_USER_AGE_25, uid);
jedis.sadd(SYS_USER_SEX_M, uid);
String uid2 = UUID.randomUUID().toString();
User u2 = new User(uid2, "小2", "M", 20);
map.put(uid2,JSON.toJSONString(u2));
jedis.sadd(SYS_USER_SEX_M, uid2);
String uid3 = UUID.randomUUID().toString();
User u3 = new User(uid3, "小3", "W", 25);
map.put(uid3,JSON.toJSONString(u3));
jedis.sadd(SYS_USER_AGE_25, uid3);
String uid4 = UUID.randomUUID().toString();
User u4 = new User(uid4, "小4", "W", 25);
map.put(uid4,JSON.toJSONString(u4));
jedis.sadd(SYS_USER_AGE_25, uid4);
jedis.hmset(SYS_USER_TABLE, map); 这几个字段就代表几个set,当user满足这个set的条件时候,就把user的id加入对应的set,而hmset就是存储用户的信息,以hash方式进行存储。

看一下存储的信息:
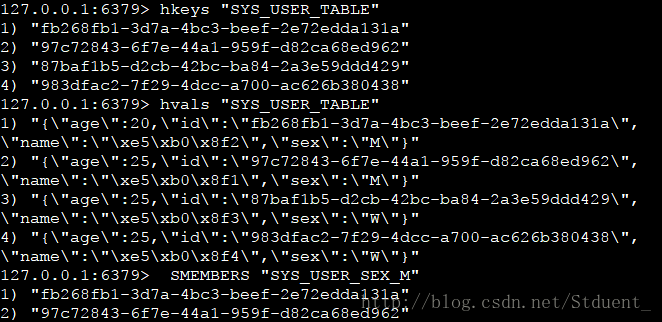
下面就可以利用sinter取两个set的交集,也就是同时满足年龄25是男性的用户了。
Set result = jedis.sinter(SYS_USER_AGE_25,SYS_USER_SEX_M);
List users = new ArrayList();
for (Iterator iterator = result.iterator(); iterator.hasNext();) {
String string = (String) iterator.next();
string = jedis.hget(SYS_USER_TABLE, string);
User user = JSON.parseObject(string, User.class);
users.add(user);
System.out.println(user.toString());
} 其实这里就是利用redis的存储结构的一些特性,集合取交集或并集,来达到关系型数据库sql语句带条件查询的功能。但是这里nosql绝不能当做关系型数据库使用。。它的出现就是为了高效,抛弃了关系型数据库维护关系的成本!所以说,技术都有各自的场景,没有好坏性。
上面只是非常简单的一个demo,真实开发表的字段都会有几十个字段,而我们其实也就是把上面的静态变量增加几十个,放到静态类里面去维护。当有个别数据发生改变,我们可以只修改部分数据即可。
当然最后说一下,学技术需要多了解原理,灵活运用,要知其所以然。