可能是史上覆盖flinksql功能最全的demo--part1
该demo基于flnk 1.10版本,由flink大佬fhueske发布到github:https://github.com/fhueske/flink-sql-demo。
动手实践前请先git clone https://github.com/fhueske/flink-sql-demo.git。
由于该demo内容较多,所以文章拆成了2部分,此为第一部分。
场景和数据介绍
此demo主要演示:
- Flink SQL如何处理不同存储系统中的数据
- Flink SQL如何使用Hive Metastore作为外部持久化catalog
- 批流统一查询实践
- 几种Join动态数据的不同方式
- 使用DDL创建表
- 在Kafka和MySQL中使用连续SQL查询维护物化视图
此demo的场景是电商收到订单
该订单系统由7张表组成
- PROD_ORDERS 主订单表
- PROD_LINEITEM: 子订单表
- PROD_CUSTOMER: 用户表
- PROD_NATION: 国家表
- PROD_REGION: 地区表
- PROD_RATES: 货币汇率表
- PROD_RATES_HISTORY: 货币汇率变更历史记录表
根据数据的更新特征(更新频率、insert-only),上面的表存在不同的系统中:
- 存在KAFKA中的:PROD_ORDERS, PROD_LINEITEM, PROD_RATES_HISTORY
- 存在MySQL中的:PROD_CUSTOMER, PROD_NATION, PROD_REGION, PROD_RATES
数据下载
可以从Google Drive上下载https://drive.google.com/file/d/15LWUBGZenWaW3R_WNxqvcTQOuA_Kgtjv,然后解压到demo的"./data"目录。
部分同学可能下载不方便,我把数据另存了一份在csdn,受csdn文件大小限制,我分成了2个部分,请分别下载后和解压:
part1:https://download.csdn.net/download/cndotaci/12540851
part2:https://download.csdn.net/download/cndotaci/12540856
启动demo
# build
docker-compose build
# start
docker-compose up -d
验证demo环境是否成功
# 验证kafka
docker-compose exec kafka kafka-console-consumer.sh --bootstrap-server kafka:9092 --from-beginning --topic orders
docker-compose exec kafka kafka-console-consumer.sh --bootstrap-server kafka:9092 --from-beginning --topic lineitem
docker-compose exec kafka kafka-console-consumer.sh --bootstrap-server kafka:9092 --from-beginning --topic rates
# 验证MySQL
docker-compose exec mysql mysql -Dsql-demo -usql-demo -pdemo-sql
SHOW TABLES;
DESCRIBE PROD_CUSTOMER;
SELECT * FROM PROD_CUSTOMER LIMIT 10;
quit;
以上,如果kafka能够消费到数据,MySQL能够查询到数据,说明环境部署成功。
此外,demo还启动了以下服务:
Grafana:http://localhost:3000
Minio:http://localhost:9000 (user: sql-demo, password: demo-sql)
Flink WebUI:http://localhost:8081
Flink SQL client
Hive Metastore
正题开始
启动Flink SQL Client:
docker-compose exec sql-client ./sql-client.sh
所有的动态表(kafka表)均在默认的catalog中,所有的静态表(MySQL表)均在Hive catalog中:
可以通过命令USE CATALOG xxx语法切换catalog,通过命令SHOW TABLES查看表。
查询静态表和动态表
得益于flink-sql的批流一体功能,有很多查询的sql语法对批处理和流处理是一致的。
对动态表做快照
- 新建一张以S3为存储的表
使用WATERMARK将o_ordertime定义为延时5分钟的eventtime:
USE CATALOG hive;
CREATE TABLE dev_orders (
o_orderkey INTEGER,
o_custkey INTEGER,
o_orderstatus STRING,
o_totalprice DOUBLE,
o_currency STRING,
o_ordertime TIMESTAMP(3),
o_orderpriority STRING,
o_clerk STRING,
o_shippriority INTEGER,
o_comment STRING,
WATERMARK FOR o_ordertime AS o_ordertime - INTERVAL '5' MINUTE
) WITH (
'connector.type' = 'filesystem',
'connector.path' = 's3://sql-demo/orders.tbl',
'format.type' = 'csv',
'format.field-delimiter' = '|'
);
- 从kafka动态表中写一些样例数据到上面创建的S3静态表dev_orders
Flink SQL> INSERT INTO dev_orders SELECT * FROM default_catalog.default_database.prod_orders;
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 31e3b34814863ceef82201208f1b68c1
-
提交INSERT语句后,可以通过Flink Web UI(http://localhost:8081)查看正在运行的任务
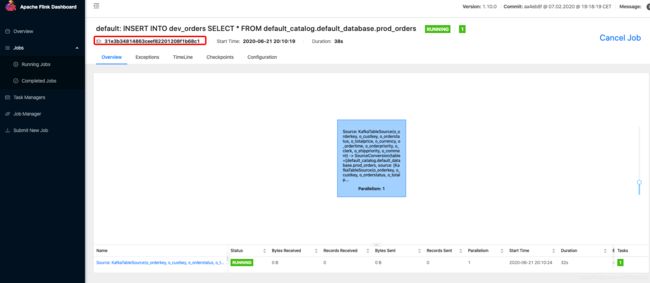
-
手动取消任务
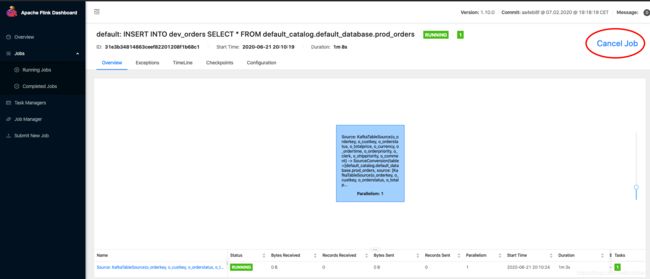
-
打开Minio(http://localhost:9000),可以看到刚刚INSERT操作写入的文件

-
在SQL client中查看刚刚写入的数据
SELECT * FROM dev_orders;
SELECT COUNT(*) AS rowCnt FROM dev_orders;
查询快照数据
- 使用批处理引擎效率更高
SET execution.type=batch;
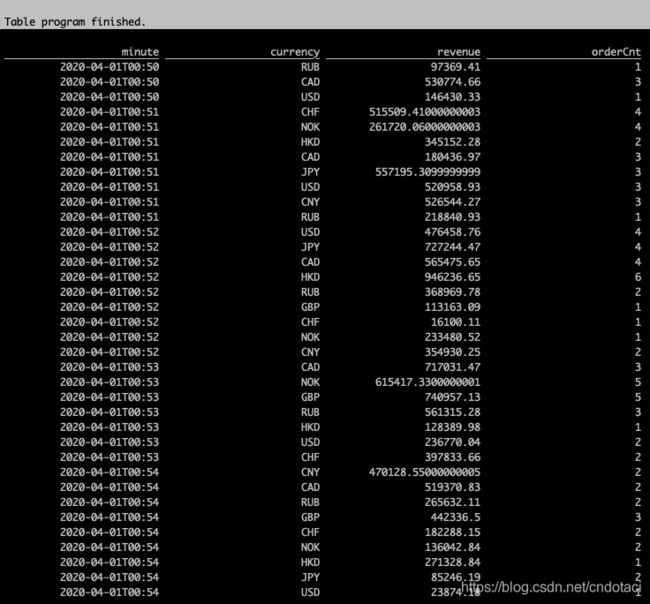
- 计算不同币种每分钟的交易额
SELECT
CEIL(o_ordertime TO MINUTE) AS `minute`,
o_currency AS `currency`,
SUM(o_totalprice) AS `revenue`,
COUNT(*) AS `orderCnt`
FROM dev_orders
GROUP BY
o_currency,
CEIL(o_ordertime TO MINUTE);
- 使用流处理引擎执行上面的查询
SET execution.type=streaming;
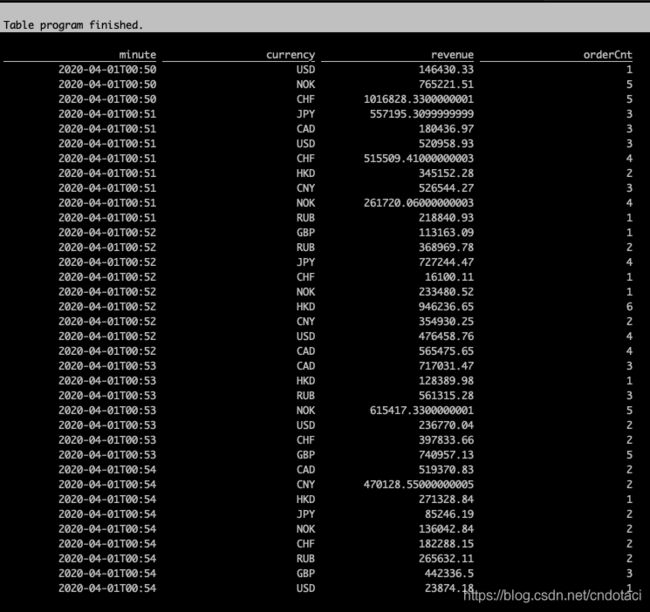
可见同样的sql,使用批处理引擎和流处理引擎会得到同样的结果。
- 下面将查询结果的返回格式由table改为changelog
SET execution.result-mode=changelog;
再次执行上面的sql:
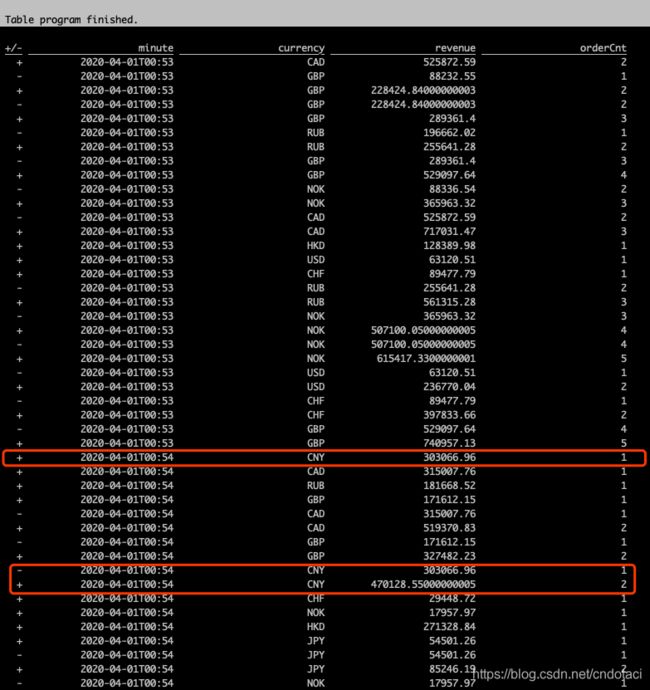
可见使用流处理引擎时,结果是通过插入(+)、删除(-)、再插入(+)的方式输出的,也就是流引擎会实时计算每一条数据并输出计算结果,相对而言批处理引擎则将全量数据统一计算,一次性返回计算结果。
- 通过滚动窗口简化上面需求的查询
SELECT
TUMBLE_END(o_ordertime, INTERVAL '1' MINUTE) AS `minute`,
o_currency AS `currency`,
SUM(o_totalprice) AS `revenue`,
COUNT(*) AS `orderCnt`
FROM dev_orders
GROUP BY
o_currency,
TUMBLE(o_ordertime, INTERVAL '1' MINUTE);
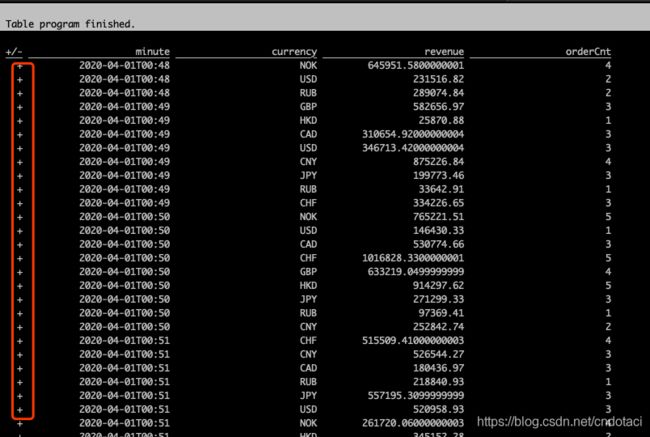
可见返回结果中,只有数据插入(+),并没有删除(-),这是因为窗口计算时,flink会等到窗口结束后统一计算窗口内的数据并返回结果,而不会每收到一条数据就计算一次然后通过删除旧数据插入新数据的方式更新。通过这种方式,简化了数据计算的复杂度,提高了性能。
- 同样,上面的窗口计算也可以使用批处理引擎进行
SET execution.result-mode=table;
SET execution.type=batch;
计算结果与使用流处理引擎一致:
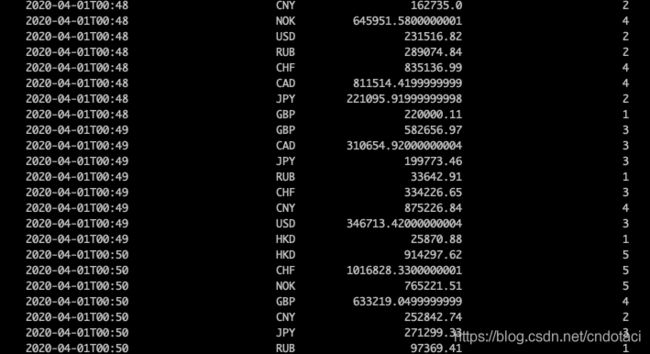
查询流数据
- 在kafka表上执行与上面示例相同的查询
SET execution.type=streaming;
- 仅修改sql中的表名为kafka表
SELECT
TUMBLE_END(o_ordertime, INTERVAL '1' MINUTE) AS `minute`,
o_currency AS `currency`,
SUM(o_totalprice) AS `revenue`,
COUNT(*) AS `orderCnt`
FROM default_catalog.default_database.prod_orders
GROUP BY
o_currency,
TUMBLE(o_ordertime, INTERVAL '1' MINUTE);
得到相同的查询结果:
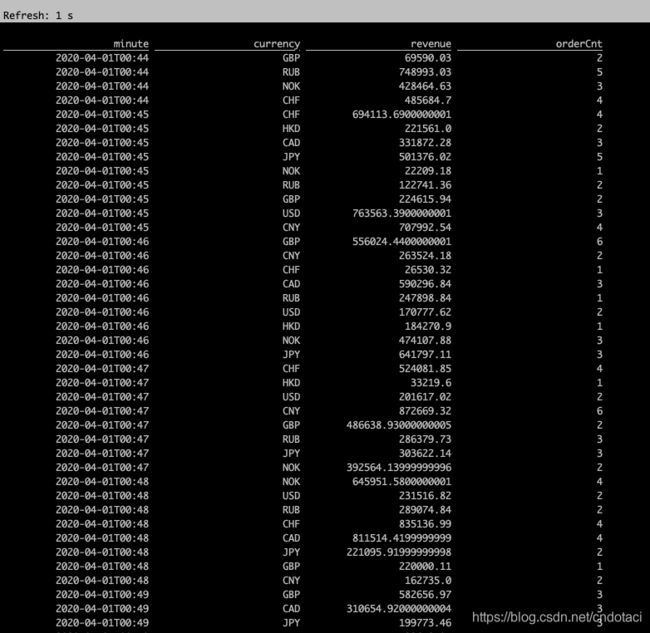
综上,对于静态数据(S3静态表),无论使用批处理引擎还是流处理引擎,同样的sql查询得到的计算结果是一致的。
使用流处理引擎,同样的sql对于静态数据和动态数据(kafka流表)也会得到相同的计算结果,这就是flink流批一体的设计原则——将批数据当做一种有限的流,这样就可以在流和批上共享大部分代码。同时,可以单独对批处理进行特有的优化。