(5) MySQL INSERT插入条件判断:如果不存在则插入 || MySQL中replace into ||INSERT INTO … ON DUPLICATE KEY U...
ref:http://my.oschina.net/jsan/blog/270161/
==============================================================================================
alter table table_name auto_increment=8000;
alter table table_name auto_increment=8000;
ref:http://www.111cn.net/database/mysql/60352.htm
2mysql获取一个表中的下一个自增(id)值的方法
给自己做笔记:从表中获取下一个自增值时只要运行以下sql语句即可:
AUTO_INCREMENT FROM information_schema.TABLES
WHERE TABLE_SCHEMA = $dbName
AND TABLE_NAME = $tblName;
例如:
SELECT auto_increment FROM information_schema.`TABLES`
WHERE TABLE_SCHEMA='my_db_name'
AND TABLE_NAME='my_table_name';
ref:http://www.bram.us/2008/07/30/mysql-get-next-auto_increment-value-fromfor-table/
另附一种PHP+mysql的方法:
$tablename = "tablename";
$next_increment = 0;
$qShowStatus = "SHOW TABLE STATUS LIKE '$tablename'";
$qShowStatusResult = mysql_query($qShowStatus) or die ( "Query failed: " . mysql_error() . "
" . $qShowStatus );
$row = mysql_fetch_assoc($qShowStatusResult);
$next_increment = $row['Auto_increment'];
echo "next increment number: [$next_increment]";
?>
3Mysql 主键自增间隔 不是1
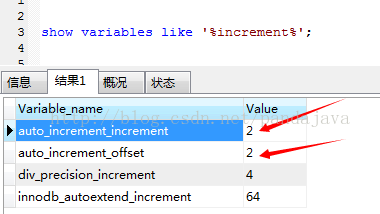
执行命令: SET @@auto_increment_increment = 2;也就是增长幅度为2。
SET @@auto_increment_offset = 1; 就是从1开始增长。
alter table table_name auto_increment=8000; 修改某个表自增id从8000处开始。
ref:http://www.iteye.com/problems/38419
==============================================================================================
MySQL中replace into
在向表中插入数据的时候,经常遇到这样的情况:
1、首先判断数据是否存在;
2、如果不存在,则插入;
3、如果存在,则更新。
但在MySQL 中有更简单的方法,使用 replace into关键字
或
replace into table(id, update_time) select 1, now();
replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中。
1、如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。(存在则影响2rows)
2、 否则,直接插入新数据。(不存在仅插入影响1rows)
要注意的是:插入数据的表必须有主键或者是唯一索引! 否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
MySQL中replace into有三种写法:
1. replace into table(col, ...) values(...)
2. replace into table(col, ...) select ...
3. replace into table set col=value, ...
前两种形式用的多些。其中 “into” 关键字可以省略,不过最好加上 “into”,这样意思更加直观。
另外,对于那些没有给予值的列,MySQL 将自动为这些列赋上默认值。
可惜的是replace不支持update某些特性,也就不能直接当作update使用:
常见update写法:update table set col=col+1 where id=1;
使用replace into不支持这样的写法:replace into table set col=col+1,id=1;
1、首先判断数据是否存在;(没问题)
2、如果不存在,则插入;(没问题)
3、如果存在,某字段值在原来的基础上加上或减去某个数,如加一操作。(不支持)
MySQL 对 SQL 有很多扩展,有些用起来很方便,但有一些被误用之后会有性能问题,还会有一些意料之外的副作用,比如 REPLACE INTO。很多使用 REPLACE INTO 的场景,实际上需要的是 INSERT INTO … ON DUPLICATE KEY U...
==============================================================================================
INSERT ... ON DUPLICATE KEY UPDATE
向数据库插入记录时,有时会有这种需求,当符合某种条件的数据存在时,去修改它,不存在时,则新增,也就是saveOrUpdate操作。这种控制可以放在业务层,也可以放在数据库层,大多数数据库都支持这种需求,如Oracle的merge语句,再如本文所讲的MySQL中的INSERT ... ON DUPLICATE KEY UPDATE语句。
该语句是基于唯一索引或主键使用,比如一个字段a被加上了unique index,并且表中已经存在了一条记录值为1,下面两个语句会有相同的效果:
ON DUPLICATE KEY UPDATE后面可以放多个字段,用英文逗号分割。使用ON DUPLICATE KEY UPDATE,最终如果插入了一个新行,则受影响的行数是1,如果修改了已存在的一行数据,则受影响的行数是2。如果字段b也被加上了unique index,则该语句和下面的update语句是等效的:
如果a=1 OR b=2匹配了多行,则只有一行会被修改。通常的,在ON DUPLICATE KEY UPDATE语句中,我们应该避免多个唯一索引的情况。如果需要插入或更新多条数据,并且更新的字段需要根据其它字段来运算时,可以使用如下语句: 在ON DUPLICATE KEY UPDATE后面使用VALUES()方法,这个语句等同于下面的两个语句: 如果一个表中包含了一个auto_increment的字段,每次insert数据后,可以通过last_insert_id()方法返回最后自动生成的值,如果通过INSERT ... ON DUPLICATE KEY UPDATE语句修改了一条数据,那么再通过last_insert_id()方法获取的值将不正确,实际测试中是多了一个数,比如向表中增加了3条数据,那么通过last_insert_id()方法得到的值是3,但是通过该语句修改了一条数据后,通过last_insert_id()方法得到的值是4。如果想解决该问题,可以通过如下语句:
重点是这句id=LAST_INSERT_ID(id)。
英文原文:https://dev.mysql.com/doc/refman/5.0/en/insert-on-duplicate.html
本文来自: 高爽|Coder ,原文地址: http://blog.csdn.net/ghsau/article/details/23557915 ,转载请注明。