Android 相见恨晚的高效编码规范
文章目录
- 概述
- 创建和销毁对象
- 面向对象
- 类
- 接口 优于抽象类
- 小结
- 泛型
- 枚举
- 注解
- Lambda 和 Stream
- 方法
- 方法命名
- 重载
- 返回值
- 通用编程
- for-each 循环优先于传统的 for 循环
- 尝试使用新 Api (不重复造轮子)
- 货币计算,禁止使用 float 和 double
- 基本类型优先于包装类型
- 命名规约
- 异常
- try 代码块
概述
本篇文章是基于《Effective Java 3》以及阿里出版的《码出高效—Java开发手册》的总结文章。
正如《为什么精英都是时间控》书中总结的 :『读书后一定要有输出,否则很快就会遗忘』
创建和销毁对象
-
静态工厂方法代替构造器
复用,减小类创建开支。用于经常请求创建相同对象,并且创建对象的代价很高。(频繁GC,创建/回收对象可以考虑 对象池)
静态工厂的常用名称包括 from , of , valueOf , instance , getInstance , newInstance , getType 和 newType. -
多个构造器参数考虑构建器,Builder 模式 是一种不错的选择
-
私有构造器强化不可实例化的能力,(单例方法 + 私有构造器)
-
消除过期的对象引用
内存泄漏 的常见原因有:
① 集合,数组保存对象,引用过期后未清空引用。
② 对象引用放缓存后遗忘删除,可以用弱/软引用持有或者是WeakHashMap 代表缓存。
③ 监听器和其它回调生命周期过长,并且持有其它引用。(非静态成员类的每个实例都会隐含的关联外围类的实例。) -
try - with - resources
java 7 引入 try - with -resources 正确处理资源关闭问题. 因为 java 7之后的资源接口基本都实现或者扩展了 AutoCloseable 接口,try() 执行完毕后会调用 close() 方法。
// 将资源处理代码放置 try () 代码块中
try (BufferedReader br1 = new BufferedReader(new FileReader("path"))) {
} catch (IOException e) {
e.printStackTrace();
}
面向对象
类
面向对象强调 高内聚,低耦合 ,先定义共性行为(接口),抽象成模型(抽象类),再解决实际问题。
面向对象有三大特性:
- 封装 : 对象功能内聚的表现形式,使模块之间耦合度变低,更具有维护性。
- 继承 : 子类获取超类的部分属性和行为,模块变得更有复用性。
- 多态 : 在复用性基础上更加有扩展性,使运行期更有想象空间。
多态并不是面向对象的一种特质,而是一种由 继承 衍生而来的进化能力而已。
设计模式的 迪米特法则 就是对于封装的具体要求,即 A 模块使用 B 模块的某个接口行为,对 B 模块中除此行为之外的信息知道得尽可能少。(尽量减少对象间的交互,最少知识原则),类与类之间松散的耦合关系。
-
类和成员的可访问性最小化 ( 信息隐藏 或 封装 )
规则很简单: 尽可能的使每个类或者成员不被外界访问 -
禁止让类具有共有的静态 final 数组域,或者返回数组域的访问方法。 要确保共有静态 final 域所引用的对象都是不可变的。
1 . 共有数组变成私有的,或者改为共有不可变列表。
2 . 添加共有方法,返回私有数组的一个拷贝。
// BAN !!!
public static final Thing[] VALUES={ ... }
- 要么设计继承并提供文档说明,要么禁止继承
① 对于为了继承而设计的类,唯一的测试方法就是 编写子类 ,通常3个子类就可以测试一个可拓展的类。
② 构造器决不能调用可被覆盖的方法。,并且无论是 clone 还是 readObject ,都不可以调用可覆盖的方法。( 子类的重写方法会 优先 子类的构造器初始化,也就是 : 重写方法获取构造器中初始化完毕的字段将为 NULL !)
public static void main(String[] args){
new Son();
new Son();
}
class Son extends Parent {
static {
System.out.println("Son 静态代码块");
}
public Son() {
System.out.println("Son 构造方法");
}
}
class Parent {
static {
System.out.println("Parent 静态代码块");
}
public Parent() {
System.out.println("Parent 构造方法");
}
}
执行结果如下:
Parent 静态代码块
Son 静态代码块
Parent 构造方法
Son 构造方法
Parent 构造方法
Son 构造方法
- 静态成员类优先于非静态成员类
非静态成员类的每个实例都会隐含的关联外围类的实例。
public class OuterClass {
// 成员内部类,对应 OuterClass$InstanceInnerClass
private class InstanceInnerClass {}
// 静态内部类,对应 OuterClass$StaticInnerClass
static class StaticInnerClass {}
public static void main(String[] args) {
// 匿名内部类,对应 OuterClass$1 和 OuterClass$2
new Thread() {}.start();
new Thread() {}.start();
// 方法内部类,对应 OuterClass$1$MethodClass1 和 OuterClass$1$MethodClass2
class MethodClass1 {}
class MethodClass2 {}
}
}
外部类与内部类使用 $ 符号分割,匿名内部类使用数字进行编号,方法内部类的类名前还有一个编号来标识是哪个方法。

-
永远不要把多个顶级类放在一个源文件中。(一个java文件包含多个平行类,多个顶级类改为成员或者内部类)
-
类的重写(一大两小两相同)
一大: 子类的方法访问权限控制符只能相同或者变大。
两小 : 抛出异常和返回值只能变小,能够转型成父类对象。
两同 : 方法名和参数必须完全相同。
抽象类在被继承时体现的是 is-a 关系,接口在被实现时体现的是 can-do 关系
接口是顶级的“类”,虽然关键字是 interface ,但是编译之后的字节码扩展名还是 .class.
抽象类是二当家,接口位于顶层,抽象类对各个接口进行了组合,然后实现部分接口行为。
接口 优于抽象类
-
接口优于抽象类
接口隔离 : 细分功能,不出现大而全的接口。
面向对象强调 高内聚,低耦合 , 先定义共性行为 (接口), 抽象成模型 (抽象类),再解决实际问题。 这就是 模板方法 模式。
接口 : 单一职责,抽象类可以实现不同类型层次的接口。
类层次代替多个标签域,也就是 多层次类(实现多接口) > 扁平类 -
接口的缺省方法
java 8 中增加了缺省方法(default method)的构造,目的就是允许给现有的接口添加方法。
或许接口程序发布之后也能纠正,但是千万别指望它!(仅供抢救)
interface DefaultImpl {
void normalMethod();
// 接口允许缺省方法
default int defaultMethod() {
return -1;
}
}
- 接口只用于 定义类型,而非导出常量(防止子类实现)
常量接口模式是对接口的不良使用!
ps : java 7 开始,数字的字面量中可以使用下划线提升可读性~
interface Constants {
int PAY_NUMBER = 1_000_000;// 下划线提升可读性
double PAY_STATUS = 0.012_123;
}
小结
当纠结定义接口还是抽象类时,优先推荐定义为 接口。遵循接口隔离原则,按某个维度划分多个接口,然后再用 抽象类 去 implement 某些接口,这样做方便后续的扩展和重构。*
泛型
泛型只有在编译才可见,编译后即 .class 文件中的“类型擦除”。
泛型只是一种编写代码时的语法检查。
- 类型安全 : 放置什么,取出来的也相同。不用担心 ClassCastException()。
- 提升可读性 : 编码阶段就清楚的显示泛型集合,方法 等处理的对象是什么。
- 代码重用 : 泛型合并了同类型的处理代码。
使用泛型比使用需要在代码中 进行转换 的类型来的更加安全,也更加容易 (确保类/方法不用转换就能使用!)
消除变量声明 出/入参数的冗余:
// 调用
String s = "";
Map<String, String> a = newHashMap(s, s);
// 泛型静态工厂方法
static <K, V> HashMap<K, V> newHashMap(K k, V v) {
HashMap<K, V> hashMap = new HashMap<>();
hashMap.put(k, v);
return hashMap;
}
泛型可以定义在类,接口,方法中,编译器通过识别尖括号<>,和尖括号内的字母来解析泛型。
在定义泛型时,约定俗成的符号包括:
- E 代表 Element,用于集合中的元素;
- T 代表 the Type of obj ,标识某个类;
- K 代表 Key ,V 代表 value 用于键值对元素;
枚举
枚举类占用内存约为普通类的 2 倍甚至更多,除非遇到以下特例情况, 代替静态常量方法。
- 针对常量之间存在关联,有分组且存在对应关系。
- 非连续数值判断 和 重载等。
// 使用
PayStatus payStatus = PayStatus.getStatus(status);// 服务器返回的状态
payStatus.layoutId;
payStatus.des;
enum PayStatus {
PAY_UNKNOW(-1, "未知", 0x101),
PAY_PROCESSING(0, "进行中", 0x101),
PAY_SUCCESS(1, "支付成功", 0x102),
PAY_FAIL(2, "支付失败", 0x103);
int status;
String des;
int layoutId;
PayStatus(int status, String des, int layoutId) {
this.status = status;
this.des = des;
this.layoutId = layoutId;
}
static PayStatus getStatus(int status) {
for (PayStatus payStatus : values()) {
if (payStatus.status == status) {
return payStatus;
}
}
return PAY_UNKNOW;
}
}
当然不使用枚举,也可以使用 注解限制输入,(指定类型)
注解
注解 Annotation : 源程序中的 元素 关联任何 信息 的途径。
// 注解限制类型输入
@IntDef({PayConstans.SUCCESS, PayConstans.FAIL})
@Retention(RetentionPolicy.SOURCE)
@Target({METHOD, PARAMETER, FIELD, LOCAL_VARIABLE})
public @interface PayConstans {
int SUCCESS = 0;
int FAIL = 1;
}
public void setStatus(@PayConstans int status) {}
public void method() {
setStatus(5);
setStatus(PayConstans.SUCCESS);
}
另外注解的升级版使用 APT (Annotation Processing Tool) 注解处理器用于编译时期生成 java 代码,减少编码量,例如 ButterKnife、Dagger、EventBus 等。
Lambda 和 Stream
-
Lambda 表示小函数的最佳方式(优先于匿名类)
Lambda 没有名称和文档,对于 Lambda 而言,一行是最理想的,三行是合理的最大极限。
如果一个计算本身不是自描述的,或者超出了几行,那就不要把它放在一个 Lambda 中。 -
this
Lambda 无法获取对自身的引用,在 Lambda 中,关键字 this 指的是外围实例。
(在匿名类中,关键字 this 指匿名类实例)
只要方法引用更加简洁、清晰,就用方法引用;如果方法引用并不简洁,就坚持使用 Lambda 。
- Stream (高级版的 Iterator)
java 8 增加的 Stream Api ,简化了数据串行或并行的大批量操作。
Stream 与 Iterator 的区别 :
- 无存储 : Stream 基于数据源对象,本身不存储数据,通过管道传递元素。
- 函数式编程 : 对 Stream 的修改不会影响源数据(产生新的Stream )
- 可消费性 : Stream 只能被“消费”一次,无法复用。
- 延迟执行 : 多个中间操作 和 1 个结束操作。(只有调用了结束操作才会触发中间操作)
更多 Stream 文档请移步 Stream初体验 , Stream的基本语法详解
方法
方法命名
方法命名应该始终遵循标准命名风格,首要目标应该是选择易于理解的,第二点就是选择大众认可的。
一个好的方法名可能需要花点时间考虑,但因此而省下来的时间可能比你花掉的还多!
-
谨慎设计方法命名
-
避免过长的参数列表 (Builder 模式)
-
不要追求提供便利的方法
只有当一项操作经常被用到的时候,才考虑为它暴露方法。避免过多的对外方法。(迪米特法则,减少对象交互,最少知识原则) -
对于参数类型,优先使用接口 而不是具体类。(向上兼容,程序更加灵活)
没有理由在编写方法时传入 HashMap 类作为输入,相反应当使用 Map 接口作为参数。
重载
- 慎用重载
// Broken ! - What does this program print ?
public static void main(String[] args) {
Collection<?>[] collections = { new HashSet<String>()
, new ArrayList<String>()
, new HashMap<String, String>().values()};
for (Collection<?> collection : collections) {
System.out.println(CollectionClassifier.classify(collection));
}
}
public static class CollectionClassifier {
public static String classify(Set<?> s) {
return "Set";
}
public static String classify(List<?> s) {
return "List";
}
public static String classify(Collection<?> s) {
return "Collection";
}
}
考虑一下这个程序会打印出什么。你可能期望打印出 Set , List , Collection ,但实际上是 :
Collection
Collection
Collection
要调用哪个重载方法是在编译期时做出的决定。(移步 : 多态与分派)
对于重载方法的选择是静态的,而对于被覆盖的方法选择则是动态的。
- 所以应该避免胡乱的使用重载机制,并且 永远不要导出两个具有相同参数数目的重载方法。
并且应该保证 : 传递同样的参数,所有的重载方法的行为必须一致。
返回值
即使数组或者集合为空,也要 返回零长度的数组或者集合,而不是 null
通用编程
for-each 循环优先于传统的 for 循环
代码摘自 : Java for循环和foreach循环的性能比较
//实例化arrayList
List<Integer> arrayList = new ArrayList<Integer>();
//实例化linkList
List<Integer> linkList = new LinkedList<Integer>();
//插入10万条数据
for (int i = 0; i < 100000; i++) {
arrayList.add(i);
linkList.add(i);
}
int array = 0;
//用for循环arrayList
long arrayForStartTime = System.currentTimeMillis();
for (int i = 0; i < arrayList.size(); i++) {
array = arrayList.get(i);
}
long arrayForEndTime = System.currentTimeMillis();
System.out.println("用for循环arrayList 10万次花费时间:" + (arrayForEndTime - arrayForStartTime) + "毫秒");
//用foreach循环arrayList
long arrayForeachStartTime = System.currentTimeMillis();
for(Integer in : arrayList){
array = in;
}
long arrayForeachEndTime = System.currentTimeMillis();
System.out.println("用foreach循环arrayList 10万次花费时间:" + (arrayForeachEndTime - arrayForeachStartTime ) + "毫秒");
//用for循环linkList
long linkForStartTime = System.currentTimeMillis();
int link = 0;
for (int i = 0; i < linkList.size(); i++) {
link = linkList.get(i);
}
long linkForEndTime = System.currentTimeMillis();
System.out.println("用for循环linkList 10万次花费时间:" + (linkForEndTime - linkForStartTime) + "毫秒");
//用froeach循环linkList
long linkForeachStartTime = System.currentTimeMillis();
for(Integer in : linkList){
link = in;
}
long linkForeachEndTime = System.currentTimeMillis();
System.out.println("用foreach循环linkList 10万次花费时间:" + (linkForeachEndTime - linkForeachStartTime ) + "毫秒");
用 for 循环 arrayList 10万次花费时间:5毫秒
用 foreach 循环 arrayList 10万次花费时间:7毫秒
用 for 循环 linkList 10万次花费时间:4481毫秒
用 foreach 循环 linkList 10万次花费时间:5毫秒
可以看到用 for 循环遍历 linkList 花费的时间特别长,下面通过 LinkedList 中 get() 代码可以知道,因为是链表结构,所以get(index) 方式只能通过遍历的方式获取,(arrayList 数组的方式存储,get() 方法是以索引方式获取)。
而 foreach 内部其实是通过 Iterator 迭代获取。
// LinkedList
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)// 从头开始遍历!
x = x.next;
return x;
}
......
}
简单来说,与传统的 for 循环相比,for-each 循环在简洁性、灵活性以及出错预防方面占有绝对优势,并且没有性能惩罚的问题。
因此,当可以选择的时候,for-each 循环应该优先于 for 循环。
尝试使用新 Api (不重复造轮子)
举个例子 : 从 Java 7 开始,就不应该再使用 Random。 现在选择随机数生成器,大多使用 ThreadLocalRandom 。
它会产生更高质量的随机数,并且速度比 Random 更快,使用更方便。
ThreadLocalRandom random = ThreadLocalRandom.current();
random.nextInt(10, 50);
在每个重要的发行版本中,都会有许多新的特性被加入到类库中,所以与这些新特性保持同步是值得的。
总而言之,不要重复造轮子。
货币计算,禁止使用 float 和 double
在使用浮点数时推荐使用双精度浮点,使用单精度由于表示区间的限制,计算结果会出现微小的误差。
float ff = 0.9f;
double dd = 0.9d;
// 0.8999999761581421
System.out.println(ff / 1.0);
// 0.9
System.out.println(dd / 1.0);
正确的处理方法是使用 BigDecimal 、int 或者 long 进行货币计算。
BigDecimal a = new BigDecimal(0.9);
BigDecimal b = new BigDecimal("1.0");// 也可以接受字符串
System.out.println(a.divide(b).floatValue());
在特殊的业务场景下,比如圆周率要求存储小数点后 1000 位,这时候推荐采用 数组 保存小数部分的数据。
并且禁止通过判断两个浮点数是否相等来控制某些业务流程。
基本类型优先于包装类型
基本数据类型都有相应的包装类,在很多情况下,需要 以对象的形式 操作,比如获取 hashCode() ,或者 getClass() , 泛型等。
包装类的存在解决了基本数据类型无法做到的事情 :
- 泛型类型参数
- 序列化
- 类型转换
- 高频区间数据缓存 (Integer 缓存 -127 ~ 128 的值)
针对上面最后一点 : 对装箱基本类型禁止运用 ‘==’ 操作符。
但是因为自动装箱,拆箱会导致程序性能下降,运行更慢。
当在一项操作中混合使用基本类型和包装类时,包装类就会自动拆/装箱。(耗时大概相差3倍)
Long sum = 0L;
for (int i = 0; i < 1000000; i++) {
sum += i;
}
System.out.println(sum);
在选择使用包装类还是基本数据类型时,推荐使用如下方式 :
-
所有的 POJO 类属性必须使用包装数据类型。
POJO : 无继承、实现接口的简单 javaBean,多用于数据装载,传递,不具有业务处理能力。 -
RPC 方法的返回值和参数必须使用包装数据类型。
RPC : 远程过程调用,因为包装数据类型可以判空,即 null 情况。( null 表示远程调用失败等。) -
所有的局部变量推荐使用基本数据类型。
命名规约
编程语言种类繁多,命名风格自成一派,但是在同一种语言中就要遵守当前语言的约定
比如在 java 中,所有 代码元素的命名均不能以下划线 _ ( 除了常量域和控件 id名 )或 美元符号 $ 开始或者结束。
-
包名统一小写,"." 点分隔符之间有且仅有一个自然语义的英文单词。
包名统一使用单数形式,但是类名如果有复数含义,可以使用复数形式。 -
抽象类命名使用 Abstract 或者 Base 开头;异常类命名则使用 Exception 结尾 ;测试类以 Test 结尾。
-
枚举类名带上 Enum 后缀,枚举成员名称同常量,需要全大写,单词间下划线隔开。 PAY_SUCCESS
-
类型与中括号紧挨相连来定义数组
int array[] = new int[] {};// 错误示例
int[] arrays = new int[] {};// 类型与中括号紧挨
更多类及方法命名规约移步 Android 相见恨晚的命名规约
异常
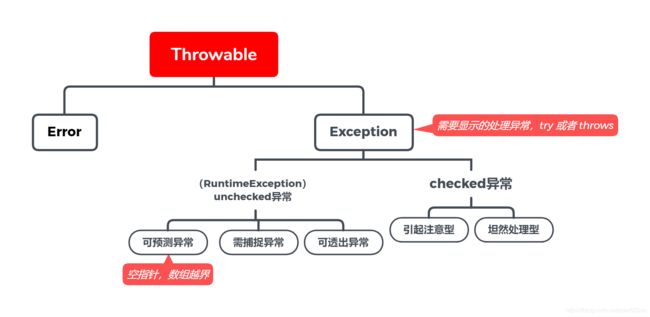
所有的异常都是 Throwable 的子类,分为 Error (致命异常) 和 Exception (非致命异常)
-
Error : 标识系统发生了不可控的错误,例如 StackOverflowError 、OutOfMemoryError ,针对此错误程序无法处理,只能人工介入。
-
Exception : 分为 checked 异常(受检异常) 和 unchecked 异常(非受检异常)。
checked 异常需要在代码中显示的处理(自行处理或者向上抛出),否则编译出错。
unchecked 异常是运行时异常,它们都继承 RuntimeException ,不需要程序进行显示的捕捉和处理。
try 代码块
try - catch -finally 是处理程序异常的三部曲。
-
try : 监视代码执行过程,一旦发现异常则直接跳转至 catch ,如果没有 catch ,则直接跳转至 finally
-
catch : 可选执行的代码块,如果没有异常发生则不会执行;如果发现异常则进行处理或向上抛出。
-
finally : 必选执行的代码块,不管是否有异常产生,即使发生 OutOfMemoryError 也会执行 。 如果 finally 代码块没有执行,那么有三种可能 :
- 没有进入 try 代码块
- 进入 try 代码块,代码运行中出现了死循环或者死锁。
- 进入 try 代码块,但是执行了 System.exit();
方法的返回值会在 finally 的影响下出现一些意想不到的结果。
finally 代码块中修改局部变量 对方法返回值的影响 :
方法在 try-catch 代码块 中出现了 return 语句,此时方法的返回值已经被暂存,即使 finally 代码块中重新对局部变量赋值也不会对影响返回结果。
注意: finally 是在 return 表达式运行后执行的
public static int method() {
// return 在 try - catch 代码块中
int a = 0;
try {
System.out.println("step 1");
a = 1 / 0;
return a;
} catch (Exception e) {
System.out.println("step 2");
return 2;
} finally {
a = -1;
System.out.println("step 3");
// ban return
}
// return a=3; 这里返回多少就是多少,try - catch 函数已经执行完毕
}
step 1
step 2
step 3
return =2
此时 return 的 结果已经被暂存 起来,切勿在 finally 代码块中 赋值或者使用 return 语句。 finally 只适用于 清理资源,释放连接,关闭管道流等操作。