SkyWalking 搭建及简单使用、入门(Linux)
1.需求
公司项目采用微服务的架构,服务很多,人工监控是不可能的,项目的访问量很大,想通过日志查找某个方法中性能的问题也是非常困难的。但是系统的性能问题是不能忽视的。系统性能检测的问题如鲠在喉,经过长时间的查找资料,功夫不负有心人,终于发现几个比较好的开源的APM(Application Performance Management)检测工具。
2.常见apm参考对比及工具选型
- SkyWalking:中国人吴晟(华为)开源的一款分布式追踪,分析,告警的工具,现在是Apache旗下开源项目,对云原生支持,目前增长势头强劲,社区活跃,中文文档没有语言障碍。
- Zipkin:Twitter公司开源的一个分布式追踪工具,被Spring Cloud Sleuth集成,使用广泛而稳定,需要在应用程序中埋点,对代码侵入性强
- Pinpoint:一个韩国团队开源的产品,探针收集的数据粒度非常细,但性能损耗大,因其出现的时间较长,完成度很高。
- Cat:美团大众点评开源的一款分布式链路追踪工具。需要在应用程序中埋点,对代码侵入性强。
项目不想侵入其他的代码,工具尽量损耗性能低,工具的社区活越,文档完善也是考虑的必要条件,经过以下表格部分参数对比,相对来说,SkyWalking更占优,因此团队采用SkyWalking作为APM工具。
| 工具名称 | 代码入侵方式 |
性能 | ui | 使用人数 | 粒度 | 告警 | 依赖分析 | traceID查询 |
|---|---|---|---|---|---|---|---|---|
| SkyWalking | 无侵入 | 高 | 丰富 | 多 | 方法级 | 有 | 有 | 有 |
| Pinpoint | 无侵入 | 低 | 丰富 | 多 | 方法级 | 有 | 有 | 有 |
| Zipkin | 侵入低 | 中 | 一般 | 多 | 接口级 | 无 | 有 | 有 |
| Cat | 侵入高 | 中 | 丰富 | 较多 | 代码级 | 有 | 无 | 无 |
3.工具简介
官方有两句话介绍SkyWalking:
SkyWalking是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8S、Mesos)架构而设计
SkyWalking是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案
SkyWalking 整体架构
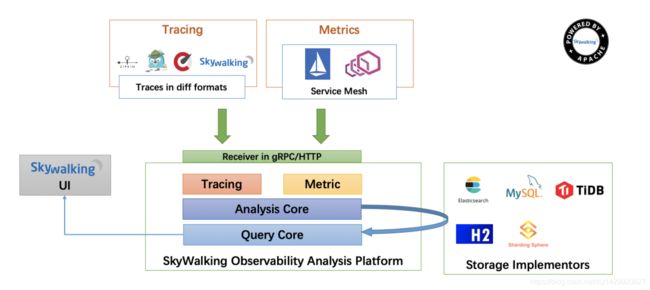
整个架构,分成上、下、左、右四部分:
考虑到让描述更简单,我们舍弃掉 Metric 指标相关,而着重在 Tracing 链路相关功能。
- 上部分 Agent :负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。而我们目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给服务器。
- 下部分 SkyWalking OAP :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
- 右部分 Storage :Tracing 数据存储。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器。而我们目前采用的是 ES ,主要考虑是 SkyWalking 开发团队自己的生产环境采用 ES 为主。
- 左部分 SkyWalking UI :负责提供控台,查看链路等等。
4.搭建步骤单机版
因为对工具可用性要求不高,工具挂掉不会影响系统,所以采用单机版。
- 第一步,搭建一个 Elasticsearch 服务。
- 第二步,下载 SkyWalking 软件包。
- 第三步,搭建一个 SkyWalking OAP 服务。
- 第四步,搭建一个 SkyWalking UI 服务。
- 第五步,启动系统服务,并配置 SkyWalking Agent。
4.1 Elasticsearch 搭建
1.下载elasticsearch-7.2.0,下载地址:https://www.elastic.co/cn/downloads/elasticsearch
2.上传下载的压缩包到linux服务器,解压文件
tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz //解压压缩包
cd elasticsearch-7.2.0 //进入目录
mkdir data //创建data文件夹,保存数据3.修改Elasticsearch配置:config/elasticsearch.yml
cluster.name: apm-application
node.name: node-1
path.data: /app/elasticsearch/elasticsearch-7.2.0/data
path.logs: /app/elasticsearch/elasticsearch-7.2.0/logs
# ES监听的ip地址
network.host: 0.0.0.0
cluster.initial_master_nodes: ["node-1"]
# 需要开启跨域才能给elasticsearch-head,kibana等连接
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type4.尝试启动Elasticsearch。
./bin/elasticsearch -d5.启动失败报错:通过日志可以发现,es不允许linux通过root用户启动,原因是出于系统安全考虑设置的条件。由于Elasticsearch可以接收用户输入的脚本并且执行,为了系统安全考虑,直接使用root权限会带来很大风险,所以我们创建一个elsearch用户
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:106) ~[elasticsearch-7.2.0.jar:7.2.0]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:195) ~[elasticsearch-7.2.0.jar:7.2.0]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:342) ~[elasticsearch-7.2.0.jar:7.2.0]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:132) ~[elasticsearch-7.2.0.jar:7.2.0]
... 6 more6.创建Elasticsearch启动用户,并设置权限等
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
chown -R elsearch:elsearch elasticsearch-7.2.07.使用elsearch用户,再次尝试启动
cd elasticsearch-7.2.0
su elsearch
./bin/elasticsearch -d8.启动失败,有两个错误,是因为有两个参数的值太小
ERROR: [2] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]问题解决办法
# 第一个问题:修改/etc/security/limits.conf文件,添加或修改如下行
hard nofile 65536
soft nofile 65536
# 第二个问题:修改 /etc/sysctl.conf 文件,添加如下行
vm.max_map_count=2621449.使用elsearch用户,再次尝试启动(Elasticsearch默认内存是1G,因为我的服务器内存是足够的,没有修改配置)
# 修改内存大小 config/jvm.options
-Xms200m
-Xmx200m10.查看是否启动成功:访问ip:9200,出现以下信息即为启动成功
{
"name" : "node-1",
"cluster_name" : "apm-application",
"cluster_uuid" : "*******************",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "615e27c",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}4.2 下载 SkyWalking 软件包
1.下载SkyWalking官方包,下载地址: http://skywalking.apache.org/downloads/ ,我们下载操作系统对应的发布版。这里,我们选择apache-skywalking-apm-es7-8.0.0.tar.gz版本想使用 Elasticsearch 7.X 版本作为存储。
2.上传下载的压缩包到linux服务器,解压文件
tar -zxvf apache-skywalking-apm-es7-8.0.0.tar.gz
cd apache-skywalking-apm-es7-8.0.04.3 SkyWalking OAP 搭建
1.修改 OAP 配置文件 config/application.yml
vim config/application.yml
# 配置文件中默认选择的是H2数据源,切换成elasticsearch7,把elasticsearch7配置成自己安装的信息
# 重点修改 storage 配置项,通过 storage.selector 配置项来设置具体使用的存储器。
# storage.elasticsearch 配置项,设置使用 Elasticsearch6.X 版本作为存储器。
# 可以主要修改nameSpace、clusterNodes两个配置即可,设置使用的Elasticsearch的集群和命名空间。
# storage.elasticsearch7配置项,设置使用Elasticsearch7.X 版本作为存储器。
storage:
selector: ${SW_STORAGE:elasticsearch7}2.启动OAP
$ bin/oapService.sh
SkyWalking OAP started successfully!4.4 SkyWalking UI 搭建
1.由于SkyWalking UI的默认地址是8080,与很多中间件有冲突,可以修改一下
# 修改webapp/webapp.yml
server:
port: 180802.启动 SkyWalking UI 服务
$ bin/webappService.sh
SkyWalking Web Application started successfully!4.5 SkyWalking Agent
1.修改探针默认配置 agent/config/agent.config
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.0.4:11800}
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:1}采样率修改
agent.sample_n_per_3_secs配置说明:
在访问量较少时,链路全量收集不会对系统带来太大负担,能够完整的观测到系统的运行状况。但是在访问量较大时,全量的链路收集,对链路收集的客户端(agent探针)、服务端(SkyWalking OAP)、存储器(例如说 Elastcsearch)都会带来较大的性能开销,甚至会影响应用的正常运行。在访问量级较大的情况下,往往会选择抽样采样,只收集部分链路信息。SkyWalking Agent 在 agent/config/agent.config 配置文件中,定义了 agent.sample_n_per_3_secs 配置项,设置每 3 秒可收集的链路数据的数量。
2.放置探针:我们需要将 agent 目录,拷贝到 Java 应用所在的服务器上。这样,Java 应用才可以配置使用该 SkyWalking Agent。通过设置启动参数的方式检测系统,没有代码侵入。
# 在服务的启动命令中添加参数javaagent、Dskywalking.agent.service_name
nohup java -javaagent:agent/skywalking-agent.jar -Dskywalking.agent.service_name=a -jar a.jar > a.log 2>&1 &
5.效果展示
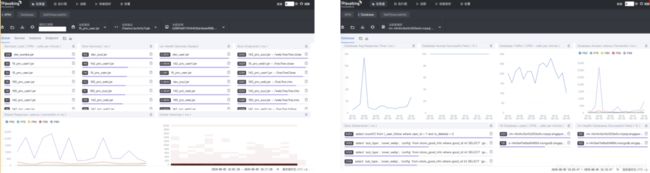
仪表盘:可以查看服务性能,接口总体耗时,数据库sql执行耗时排行等等
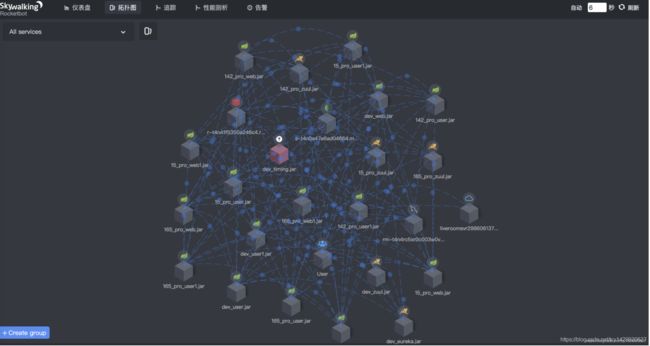
拓扑图:可以查看已经检测的服务及服务之间的关系
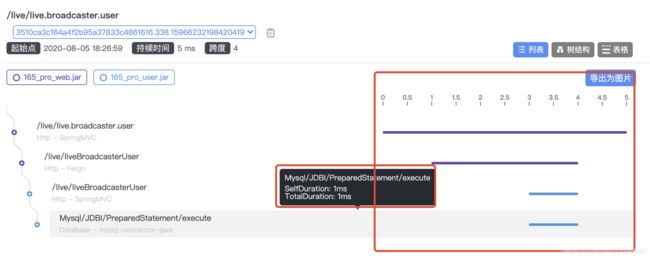
追踪:可以看到服务调用的路径
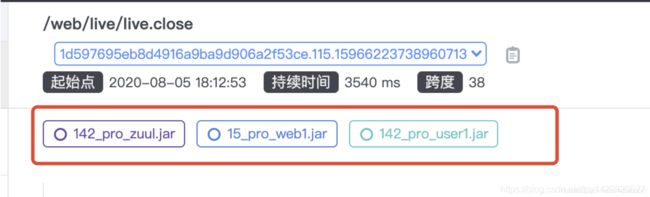
追踪:可以看到整个链路中每一个步骤的耗时情况,其中可以看到方法中各个sql执行耗时及对应的sql,可以有针对的优化sql

刚接触SkyWalking还有很多的功能细节需要再深入了解,如果发现有问题,欢迎大家指教。