Android和java创建xml文件和解析xml文件剖析
创建和解析xml文件大致有三种方法:
sax方法
dom方法
pull方法
一般在java开发环境中用dom方法
1.接口
package cn.com.shine;
public interface xmlInfo {
/**
* 建立XML文档
* @param fileName 文件全路径名称
*/
public void createXml(String fileName);
/**
* 解析XML文档
* @param fileName 文件全路径名称
*/
public void parserXml(String fileName);
}
2.
package cn.com.shine;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.util.List;
import javax.xml.bind.Element;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class Xml implements xmlInfo{
private Document document;
public void init() {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory
.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
this.document = builder.newDocument();
} catch (ParserConfigurationException e) {
System.out.println(e.getMessage());
}
}
@Override
public void createXml(String fileName) {
org.w3c.dom.Element root = this.document.createElement("scores");
this.document.appendChild(root);
org.w3c.dom.Element employee = this.document.createElement("employee");
org.w3c.dom.Element name = this.document.createElement("name");
name.appendChild(this.document.createTextNode("wangchenyang"));
employee.appendChild(name);
org.w3c.dom.Element sex = this.document.createElement("sex");
sex.appendChild(this.document.createTextNode("m"));
employee.appendChild(sex);
org.w3c.dom.Element age = this.document.createElement("age");
age.appendChild(this.document.createTextNode("26"));
employee.appendChild(age);
root.appendChild(employee);
TransformerFactory tf = TransformerFactory.newInstance();
try {
Transformer transformer = tf.newTransformer();
DOMSource source = new DOMSource(document);
transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312");
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
PrintWriter pw = new PrintWriter(new FileOutputStream(fileName));
StreamResult result = new StreamResult(pw);
transformer.transform(source, result);
System.out.println("生成XML文件成功!");
} catch (TransformerConfigurationException e) {
System.out.println(e.getMessage());
} catch (IllegalArgumentException e) {
System.out.println(e.getMessage());
} catch (FileNotFoundException e) {
System.out.println(e.getMessage());
} catch (TransformerException e) {
System.out.println(e.getMessage());
}
}
public void parserXml(String fileName) {
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document document = db.parse(fileName);
NodeList employees = document.getChildNodes();
for (int i = 0; i < employees.getLength(); i++) {
Node employee = employees.item(i);
NodeList employeeInfo = employee.getChildNodes();
for (int j = 0; j < employeeInfo.getLength(); j++) {
Node node = employeeInfo.item(j);
NodeList employeeMeta = node.getChildNodes();
for (int k = 0; k < employeeMeta.getLength(); k++) {
System.out.println(employeeMeta.item(k).getNodeName()
+ ":" + employeeMeta.item(k).getTextContent());
}
}
}
System.out.println("解析完毕");
} catch (FileNotFoundException e) {
System.out.println(e.getMessage());
} catch (ParserConfigurationException e) {
System.out.println(e.getMessage());
} catch (SAXException e) {
System.out.println(e.getMessage());
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
}
3
package cn.com.shine;
public class Mainone {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
Xml dd=new Xml();
String str="D:/grade.xml";
dd.init();
dd.createXml(str); //创建xml
dd.parserXml(str); //读取xml
}
}
================
public class Java2XML {
public void BuildXMLDoc() throws IOException, JDOMException {
// 创建根节点 list;
Element root = new Element("list");
// 根节点添加到文档中;
Document Doc = new Document(root);
// 此处 for 循环可替换成 遍历 数据库表的结果集操作;
for (int i = 0; i < 5; i++) {
// 创建节点 user;
Element elements = new Element("user");
// 给 user 节点添加属性 id;
elements.setAttribute("id", "" + i);
// 给 user 节点添加子节点并赋值;
// new Element("name")中的 "name" 替换成表中相应字段,setText("xuehui")中 "xuehui 替换成表中记录值;
elements.addContent(new Element("name").setText("xuehui"));
elements.addContent(new Element("age").setText("28"));
elements.addContent(new Element("sex").setText("Male"));
// 给父节点list添加user子节点;
root.addContent(elements);
}
XMLOutputter XMLOut = new XMLOutputter();
// 输出 user.xml 文件;
XMLOut.output(Doc, new FileOutputStream("user.xml"));
}
public static void main(String[] args) {
try {
Java2XML j2x = new Java2XML();
System.out.println("生成 mxl 文件...");
j2x.BuildXMLDoc();
} catch (Exception e) {
e.printStackTrace();
}
}
生成的 user.xml 文件
xuehui
28
Male
xuehui
28
Male
生成XML时候处理缩进,对输出格式进行美化
只需要将上面生成XML时候的带吗修改成如下代码:
Format format = Format.getPrettyFormat();
XMLOutputter XMLOut = new XMLOutputter(format);
XMLOut.output(Doc, new FileOutputStream("user.xml"));
生成XML的时候,处理特殊字符
element.addContent(new CDATA(" content"));
生成XML的时候,设置编码
XMLOutputter XMLOut = new XMLOutputter();
XMLOut.setEncoding("gb2312");
XMLOut.output(Doc, new FileOutputStream("test1.xml"));
一般在android开发中用sax方法
package com.shine.victor;
import java.io.OutputStream;
import java.util.List;
import org.xmlpull.v1.XmlSerializer;
import android.util.Xml;
public class PullBuildXMLService {
public void buildXML(List persons,OutputStream outputStream)throws Exception{
XmlSerializer serializer = Xml.newSerializer();
serializer.setOutput(outputStream,"utf-8");
serializer.startDocument("utf-8", true);
serializer.startTag(null, "perisons");
for(Person person:persons){
serializer.startTag(null, "perison");
serializer.attribute(null, "id",String.valueOf(person.id));
serializer.startTag(null, "name");
serializer.text(person.name);
serializer.endTag(null, "name");
serializer.startTag(null, "age");
serializer.text(String.valueOf(person.age));
serializer.endTag(null, "age");
serializer.endTag(null, "perison");
}
serializer.endTag(null, "perisons");
serializer.endDocument();
outputStream.close();
}
}
2
package com.shine.victor;
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import android.os.Bundle;
import android.app.Activity;
import android.view.Menu;
import android.view.View;
import android.widget.Button;
public class MainActivity extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Button bt=(Button) this.findViewById(R.id.bt);
bt.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View arg0) {
// TODO Auto-generated method stub
try {
writeFile();
} catch (Throwable e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
});
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
// Inflate the menu; this adds items to the action bar if it is present.
getMenuInflater().inflate(R.menu.activity_main, menu);
return true;
}
public void writeFile() throws Throwable{
List list = new ArrayList();
for(int i =0;i<10;i++){
Person person = new Person();
person.id = 1;
person.name = "ant";
person.age = 12;
list.add(person);
}
File file = new File(MainActivity.this.getFilesDir(),"person.xml");
FileOutputStream outputStream = new FileOutputStream(file);
PullBuildXMLService service = new PullBuildXMLService();
service.buildXML(list, outputStream);
}
}
==================================================================================
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
XML文件解析技术详解总结:
在开发时很自然的要用到XML文件的解析技术。现在我们就总结一下在这方面的学习所得。
XML简介
XML的是eXtensible Market Language(即可扩展的标记语言)的缩写,它是标准通用标记语言(Standard Generalized Markup Language, SGML)的一个子集。
SGML功能非常的强大,它是可以定义标记语言的元语言。而由于它的复杂,不适合于应用。于是W3C组织在1996年开始设计一种可扩展的标记语言,从而将SGML的丰富功能与HTML的易用性结合在Web应用中,于是就有了XML。XML它是一种开放的、自我描述的方式定义了数据结构。在描述数据内容的同时能突出对结构的描述,从而体现出数据与数据之间的关系。
大家可能比较熟悉HTML。但与HTML相比,XML有下列优点:
l XML将数据和显示分开
HTML文档将数据、页面的排版、以及页面的表现形式混合在一起,如果要增加新的数据,相应地就要调整数据排版与显示方式。这样不利于数据的交换以及数据的操作,例如插入数据和删除数据。随着电子商务等网络应用的普及,不同系统、不同平台的信息交换日益频繁,而HTML本身的不足,限制了它在Web开发中的应用。
XML只描述数据和数据的结构。从而将数据和显示分开,我们就可以为同一份数据设计不同的排版和显示风格,而数据本身不做任何的改变。
l XML对文档的格式要求更加严格
由于HTML文档格式的松散,导致了HTML文档解析的复杂性,当然也造成了浏览器的兼容的问题。
而XML文档对格式有非常严格的要求,凡是符合标准的文档就是格式良好的XML文档(Well-Formed XML Document)。
l XML有且只能有一个根元素
这减少了在解析文档时的难度。
对XML文档的解析
在解析XML文档时通常是利用XML解析器对文档进行分析,而应用程序就是通过解析器提供的API而得到XML数据。
如果不同的开发商开发的XML解析器提供的API都不一样,那么应用程序只能使用一个特定的解析器。一旦更改解析器,就要重新更改代码,这是相当痛苦的。所以目前几乎所有的解析器都对两套标准的API提供了支持,它们就是DOM和SAX(标准的威力啊)。
DOM和SAX只是定义了一套标准的接口,以及一些默认的实现。而解析器的开发商在开发解析器的时候就要实现这些接口。用户只要根据这些接口就能访问XML文档,却不必去知道具体的实现(这就是面向对象编程思想中的:针对接口编程,而不是对类编程)。
Apache的Xerces是一个使用非常广泛的解析器。它都支持DOM和SAX,并提供了相应的接口。它更是提供了多种语言的实现版本。
....
org.xml.sax.XMLReader sp = new org.apache.xerce.parsers.SAXParser();
FileInputStream fis = new FileInputStream("some.xml");
InputSource is = new InputSource(fis);
sp.setContentHandler();
sp.parse(is);
....
要利用Xerces访问XML文档,只需在应用程序中构造一个解析器的实现类的对象。例如:SAX定义的解析器接口是org.xml.sax.XMLReader,Xerces中提供的实现类是org.apache.xerces.parsers.SAXParser。
但是现在仍有问题:不同的解析器实现类是不同的,如果要使用另一个解析器,仍然需要修改程序,比如说就得修改org.apache.xerce.parsers.SAXParser( )这段代码。而JAXP API可以帮助我们在改动解析器时无需改动代码。JAXP提供了在解析器之上一个抽象层,并未提供任何解析XML的方法和实现。从而屏蔽了具体开发商的实现,允许开发人员以独立于厂商的API调用访问XML数据。
从JAXP 1.1开始,JAXP就成为了J2SE 和J2EE的一部分。JAXP开发包有javax.xml包及其子包、org.xml.sax包及其子包、org.w3c.dom及其子包组成。在javax.xml.parsers包中,定义了几个工厂类,用于加载DOM和SAX的实现类。只要符合JAXP规范的解析器实现其中的接口和抽象类,开发人员就可以在不改动代码的前提下,任意切换底层的实现类。
上面介绍了xml的相关解析技术,下面我们介绍解析器模型及案例
DOM
DOM是W3C组织以IDL(Interface Definition Language,接口定义语言)的形式定义了DOM中的接口。某种语言要实现DOM,需要将DOM接口转换为本语言中的适当结构。
DOM结构模型
DOM中的核心概念是节点,它把XML文档的各个部分(元素、属性、文本、注释和处理指令等)都抽象为节点。在内存中整个文档是一个树的结构存储的,整棵树是个节点,树中的每一个节点也是一个树。我们通过访问树中的节点来存取XML文档的内容。
DOM定义了一个Node接口,用于表示文档树中一个节点。从Node接口派生出了更多的具体接口,例如Document接口、Element接口、Attr接口。
上图表示DOM中表示XML文档中各组成部分的接口继承关系
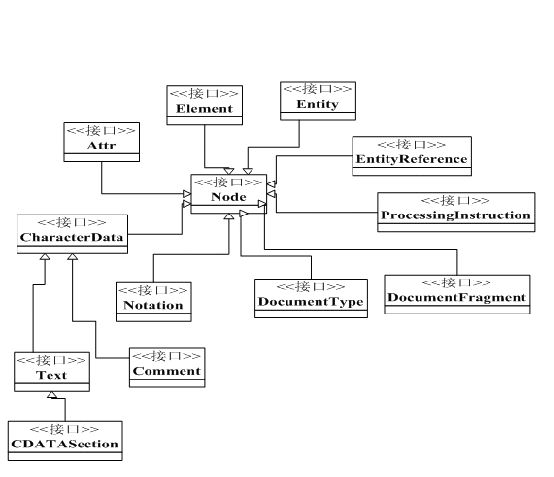
在实际使用中,很少使用Node对象,而是Document、Text、Element和Attr等Node对象的子对象来操作文档。当然在顶层的Node接口声明了对节点进行操作的方法。下面就列出了Node接口的主要方法:
public String getNodeName();
返回该节点的名字
public short getNodeType();
返回表示该节点类型的代码
public String getNodeValue() throws DOMException;
返回该节点的值
public void setNodeValue(String nodeValue) throws DOMException;
设置该节点的值
public boolean hasChildNodes();
判断该节点是否还有子节点
public NodeList getChildNodes();
以列表的形式返回该节点的所有子节点
………等等
DOM解析器工厂
在javax.xml.parsers包中定义了DOM解析器工厂类DocumentBuildFactory,用于产生DOM解析器。DocumentBuildFactory是一个抽象类,在这个类中提供了一个静态的方法newInstance( ),用于创建工厂类的一个实例。
DocumentBuildFactory factory = DocumentBuildFactory.newInstance();
DoucmentBuild build = factory.newDocumentBuilder();
DocumentBuild类也是一个抽象类,调用DocumentBuildFactory的newInstance( )方法得到具体厂商的工厂类的实例后,再利用其newDocumentBuilder( )方法,得到具体厂商的DOM解析器对象。
DocumentBuilder类提供了parse()方法,用于解析XML文档的内容,返回一个表示整个文档的Document对象。Parse()方法的参数可以是File类、InputSource类、InputStream类或表示XML文件的URI。
DOM树中的节点类型
DOM本质上是节点的集合。由于一个文档中可能包含不同类型的信息。
| 节点类型 |
DOM中的接口 |
说明 |
| 注释 |
Comment |
Comment接口继承自CharacterData接口,表示注释的内容 |
| 处理指令 |
ProcessingInstruction |
ProcessingInstruction接口表示XML文档中的处理指令部分 |
| 文档类型 |
DocumentType |
每一个Document都有一个docType属性,其值是null或是DocumentType对象。DocumentType接口为DTD中声明的实体列表和记号(notation)提供了一个接口 |
| 文档片断 |
DocuementFragment |
文档其实是“最小”的Document对象。DocumentFragment对象和Document对象的主要区别是,DocumentFragment可以不是格式良好的。可以通过移动文档的片断来重新排列文档。 |
| CDATA |
CDATASection |
CDATASection接口继承自Text接口,表示XML文档的CDATA段 |
| 实体 |
Entity |
Entity接口表示一个在XML文档中已分析的或未分析的实体。 |
| 实体引用 |
EntityReference |
EntityReference节点可以用于表示DOM树中的一个实体引用。 |
| 记号 |
Notation |
Notation接口表示了在DTD中声明的记号 |
例子
package org.jackkp.dom;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
publicclass DOMTest {
publicstaticvoid main(String[] args){
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try{
DocumentBuilder db = dbf.newDocumentBuilder();
File file = new File("student.xml");
Document doc = db.parse(file);
NodeList nl = doc.getElementsByTagName("student");
for(int i = 0; i < nl.getLength(); i++){
Element stu = (Element)nl.item(i);
Node name = stu.getElementsByTagName("name").item(0);
Node age = stu.getElementsByTagName("age").item(0);
System.out.print("姓名: ");
System.out.println(name.getFirstChild().getNodeValue());
System.out.print("年龄: ");
System.out.println(age.getFirstChild().getNodeValue());
System.out.println("****************************");
}
}catch(ParserConfigurationException e){
e.printStackTrace();
}catch(IOException e){
e.printStackTrace();
}catch(SAXException e){
e.printStackTrace();
}
}
}
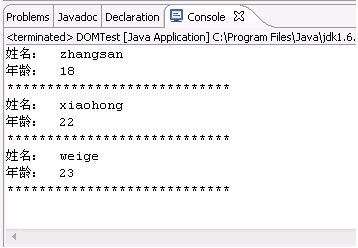
下面是运行结果:

SAX
在使用DOM解析XML文档是,需要读入整个XML文档,然后在内存中创建DOM树,生成DOM树上的每个节点对象。只有在整个DOM树创建完成后,才能进行其它的操作。当XML文档比较大时,构建DOM树将花费大量的时间和内存。
而使用SAX允许你在读取文档的时候对它进行处理。
SAX处理机制
SAX是一种基于事件驱动的API。用SAX模型来解析XML文档时,要涉及到解析器和事件处理器。解析器负责读取XML文档,并向事件处理器发送请求;而事件处理器负责对事件作出响应,对传递的XML数据进行处理。
SAX在解析文档时,一般会依次产生下列事件:
文档开始
元素开始
字符数据(可能是XML文档中的空白部分)
元素开始
字符数据
元素结束
字符数据
元素结束
文档结束
事件处理器中对事件做出响应的方法也叫做回调方法(callback method)。
解析器
XMLReader是SAX2.0解析器必须实现的接口,这个接口允许应用程序设置和查询解析器的功能和特性,可以注册用户自定义的事件处理器,以及文档的解析。XMLReader接口中的主要方法如下:
void setEntityResolver(EntityResolver resolver):允许应用程序注册一个实体解析器。如果应用程序没有注册实体解析器,XMLReader将执行它自己的默认实体解析器。
EntityResolver getEntityResolver( ):返回当前的实体解析器。
void setContentHandler(ContentHandler handler):允许应用程序注册一个内容事件处理器。如果应用程序没有注册内容事件处理器,那么SAX解析器报告的所有内容事件都将被忽略。
ContentHandler getHandler( ):返回当前的内容处理器。
void parse(InputSource input) throws IOException, SAXException
void parse(String systemId) throws IOException, SAXException
parse( )方法用于解析XML文档。应用程序可以使用这个方法来通知XMLReader开始解析从任何有效的输入源(URI、字节流或字符流)读取的XML文档。在解析过程中XMLReader通过注册的事件处理器来提供XML文档的信息。
事件解析器
解析器提供商负责提供实现XMLReader接口的解析器类,用户只需编写事件处理器程序即可。ContentHandler接口是一个主要的处理器接口。如果应用程序要获得基本的解析事件,它就要实现这个接口,并使用XMLReader对象的setContentHandler()方法向解析器注册一个ContentHandler实例。解析器使用这个实例来报告与文档相关的基本事件。ContentHandler( )的主要方法如下:
void setDocumentLocation(Locator locator):接收一个获取文档分析时产生的SAX事件对象定位信息的对象。该方法将在解析器报告任何其它文档事件之前被调用。定位器对象允许应用程序测试任何与文档相关的事件的结束位置。
void startDocument( ) throws SAXException;
void endDocument( ) throws SAXException;
void startElement(String uri, String localName, String qName, Attributes atts) throws SAXException:XML文档的每一个元素开始时调用这个方法。startElement()方法的参数取决于SAX本身的http://xml.org/sax/features/namspaces和http://xml.org/sax/features/namespace-prefixs属性值
l 当namespaces属性值是true时,名称空间(uri)和本地名(localName)是必需的。为false时,两者是可选的(默认是true)
l 当namespace-prefixes属性值是true,那么限定名是必需的,否则是可选的(默认是false)。
void endElement(String uri, String localName, String qName) throws SAXException:解析器在XML文档的每一个元素结束时调用这个方法。
void processingInstruction(String arget, String data) throws SAXException:解析器每遇到一个处理指令就调用这个方法。
JAXP也为SAX解析器提供了工厂类——SAXParserFactory类。SAX解析器工厂类的实例与DOM解析器工厂类的实例类似,都是通过newInstance( )方法来创建的。JAXP中定义的SAX解析器类是SAXParser(相当于DOM中的DocumentBuilder类,获取方法也类似)。实际上SAXParser是JAXP对XMLReader实现类的一个包装类。在SAXParser中定义了返回XMLReader实例的方法getXMLReader( )。
public abstract XMLReader getXMLReader( );
而XMLReader和SAXParser中都有parse( )方法,并且是等效的。但SAXParser中的parse( )方法使用范围更广,因为它能接受更多的参数,对不同的XML文档数据源进行解析。
public void parse(InputSource is, DefaultHandler dh) throws SAXException, IOException
public void parse(InputStream is, DefaultHandler dh, String systemId) throws SAXException, IOException
public void parse(String uri, DefaultHandler dh) throws SAXException, IOException
public void parse(File f, DefaultHandler dh) throws SAXException, IOException
public void parse(InputSource is, DefaultHandler dh) throws SAXExcepiton, IOException
例子
package org.jackkp.sax;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
publicclass SAXParserTestextends DefaultHandler{
publicvoid startDocument()throws SAXException{
System.out.println("This is the starting of the document");
System.out.println("");
}
publicvoid processingInstruction(String target, String data)
throws SAXException{
System.out.println("Processing the instructions");
System.out.println(" + target +" " + data +"?>");
}
publicvoid startElement(String uri,
String localname,
String qName,
Attributes attrs) throws SAXException{
System.out.println("Output the tabs and their attributes");
System.out.print("<" + qName);
int length = attrs.getLength();
for (int i = 0; i < length; i++) {
System.out.print(" ");
System.out.print(attrs.getQName(i));
System.out.print(attrs.getValue(i));
System.out.print("/"");
}
System.out.println(">");
}
publicvoid characters(char[] ch, int start,int length)
throws SAXException{
//输出元素的数据内容
System.out.println(new String(ch, start, length));
}
publicvoid endElement(String uri, String localName, String qName)
throws SAXException{
//输出元素的结束标签
System.out.println(" + qName +">");
}
publicstaticvoid main(String[] args) {
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser sp = null;
try{
sp = spf.newSAXParser();
File file = new File("student.xml");
sp.parse(file, new SAXParserTest());
}catch(ParserConfigurationException e){
e.printStackTrace();
}catch(SAXException e){
e.printStackTrace();
}catch(IOException e){
e.printStackTrace();
}
}
}
下面是这个程序的运行结果:
http://www.cnblogs.com/guoxinkun/category/297244.html
===========================
import org.w3c.dom.*;
import org.xml.sax.*;
import javax.xml.parsers.*;
import java.io.*;
import javax.xml.transform.*;
import javax.xml.transform.dom.*;
import javax.xml.transform.stream.*;
/**author 汤锐*/
public class pxml
{
static String xmlpath = "D:/tr/xml/";
public static void main(String args[])
{
try
{
xml xx = new xml();
xx.ProuduceXml(xmlpath);
}
catch(Exception e)
{
System.out.println("main:\n"+e.getMessage());
}
}
}
class xml
{
DocumentBuilderFactory dbf = null;
DocumentBuilder db = null;
Document doc = null;
TransformerFactory tff = null;
Transformer tf = null;
Source in = null;
Result out = null;
String xmlpath = null;
public xml()throws Exception
{
dbf = DocumentBuilderFactory.newInstance();//实例化工厂类
dbf.setValidating(false);//不进行有效性检查
dbf.setNamespaceAware(true);
db = dbf.newDocumentBuilder();//实例化DocumentBuilder类
doc = db.newDocument();//实例化Document类
tff = TransformerFactory.newInstance();
tf = tff.newTransformer();
in=new DOMSource(doc);
}
/*=====================================================
*============生成xml文件
*=====================================================*/
public void ProuduceXml(String axmlpath)
{
try
{
Element students = doc.createElement("sudents");//生产根元素students
doc.appendChild(students);//将根元素添加到根节点后面
Element student = ProuduceElement("001", "张君宝","男","2");
students.appendChild(student);
student = ProuduceElement("002", "张无忌","女","3");
students.appendChild(student);
xmlpath = axmlpath;
out=new StreamResult(new FileOutputStream(xmlpath+"tr.xml"));//生成输出源
tf.transform(in,out);
}
catch(Exception e)
{
System.out.println(e.getMessage());
}
}
public Element ProuduceElement(String aid, String aname,String asex,String aage) throws Exception
{
Element student = doc.createElement("student");//生成student元素(students的子元素)
student.setAttribute("id",aid);//设置student的属性id的值
Element name = doc.createElement("name");//创建name子元素
name.appendChild(doc.createTextNode(aname));//在name元素后添加文本节点
student.appendChild(name);//添加student的子元素name
Element sex = doc.createElement("sex");
sex.appendChild(doc.createTextNode(asex));
student.appendChild(sex);
Element age = doc.createElement("age");
age.appendChild(doc.createTextNode(aage));
student.appendChild(age);
return student;
}
}