Redis安装及使用
Redis安装及使用
Redis简介:
概述
1、Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。官网:http://redis.io/
2、redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)等。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
3、Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
4、Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
5、Redis这种面向“键/值”对数据类型的内存数据库,可以满足我们对海量数据的读写需求。
特性
1、高性能(Redis读的速度是11W次/s,写的速度是8.1W次/s)
2、原子性(保证数据的准确性)
3、持久存储(两种方式RDB/快照,AOF/日志)
4、主从结构(master-slave,负载均衡,高可用)
5、支持集群(3.0版本)
应用(在高并发和实时请求的场景)
新浪微博:
1、hash:关注列表,粉丝列表
2、string:微博数,粉丝数(避免使用select count(*) from...)
3、sorted set:TopN,热门微博
还有github,stackoverflow等也用到了redis。
使用Redis的公司: http://www.redis.cn/topics/whos-using-redis.html
Redis安装
安装C编译环境
yum -y install cpp
yum -y install binutils
yum -y install glibc
yum -y install glibc-kernheaders
yum -y install glibc-common
yum -y install glibc-devel
yum -y install gcc
yum -y install make 注意:
如果上面的软件都安装之后再执行make命令还报错,就需要在make命令后面加如下选项。
make MALLOC=libc(指定内存分配器,默认是使用jemalloc)
编译安装Redis(单机)
redis官网:http://redis.io/
redis历史版本下载:http://download.redis.io/releases/
解压:tar -zxvf redis-3.0.0.tar.gz
编译、安装
make
make install拷贝配置文件
cp redis/redis.conf /etc/(拷贝到这里只是为了方便以后使用)修改配置文件redis.conf
daemonize yes(后台运行)
logfile /usr/local/redis/log(日志文件,目录必须存在)服务端启动
redis-server /etc/redis.conf [--port 6379]redis客户端启动
redis-cli [-h 127.0.0.1] [-p 6379]关闭服务端
redis-cli shutdown(在redis-cli命令行下直接敲shutdown)注意事项:
1、启动时默认会在启动的目录生成RDB持久化文件dump.rdb,服务端下次启动时,如果还在这个有dump.rdb文件的目录启动,则上次的数据还存在,如果不是,则不存在。这个可以在配置文件redis.conf中配置。
2、启动时可以以指定配置文件redis.conf启动。
Redis多数据库特性
多数据库
1、每个数据库对外都是以一个从0开始的递增数字命名,不支持自定义的。
2、redis默认支持16个数据库,可以通过修改databases参数来修改这个默认值。
3、redis默认选择的是0号数据库。
4、SELECT 数字: 可以切换数据库。
5、多个数据库之间并不是完全隔离的。
6、flushall:清空redis实例下的所有数据。
7、flushdb:清空当前数据库中的所有数据。
Redis基本命令
获得符合规则的键名称
keys 表达式(?,* ,[],\?)判断一个键是否存在
exists key删除键
del key
del key1 key2获得键值的数据类型
Type key返回值可能是这五种类型(string,hash,list,set,zset)
帮助命令
"help " for help on 退出
"quit" to exit注意:redis的命令不区分大小写
Redis数据类型及操作
- 字符串(Strings)
- 列表(List)
- 集合(Set)
- 哈希 / 散列(Hash)
- 有序集合 (Sorted set)
- 位图(Bitmap)和超重对数(HyperLogLog)
字符串(Strings)
字符串类型是redis中最基本的数据类型,它能存储任何形式的内容,包含二进制数据,甚至是一张图片(二进制内容)。一个字符串类型的值存储的最大容量是512MB
常用命令
示例:
启动服务端和客户端 (服务端设置了daemonize yes 在后台运行)
![]()
注意:/etc/redis.conf 是我为了配置方便从编译好的Redis中拷贝过去的,并做了配置修改。
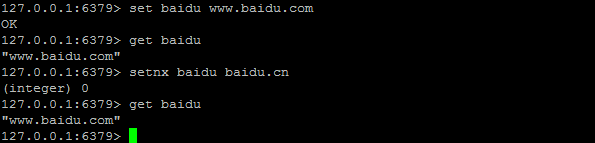
SET / GET(SETNX)
Setnx [SET if Not eXists] (如果不存在,则 SET)的简写:
格式:set key value (如果键存在,则为更新)
MSET / MGET
MSET key value [key value ...] :同时设置一个或多个 key-value 对。
MGET key [key ...] : 返回所有(一个或多个)给定 key 的值。

INCR key
将key中储存的数字值增一。如果key不存在,那么key的值会先被初始化为0,然后再执行INCR 操作。

DECR
DECR key
将key中储存的数字值减一。如果key不存在,那么key的值会先被初始化为0,然后再执行DECR 操作。

INCRBY
INCRBY key increment
将key所储存的值加上增量increment。如果key不存在,那么key的值会先被初始化为0,然后再执行INCRBY 命令。

DECRBY
DECRBY key decrement
将key所储存的值减去减量decrement。如果key不存在,那么key的值会先被初始化为0,然后再执行DECRBY 操作。

INCRBYFLOAT
INCRBYFLOAT key increment
为key中所储存的值加上浮点数增量increment。如果key不存在,那么INCRBYFLOAT 会先将key的值设为0,再执行加法操作。

哈希 / 散列(Hash)
1、hash类型的值存储了字段和字段值的映射,字段和字段值只能是字符串,不支持其他数据类型。hash类型的键至多可以存储2^32 -1 个字段。
2、hash类型适合存储对象,redis可以为任何键增减字段而不影响其他键。
命令:
HSET / HGET
HSET key field value:将哈希表key中的域field的值设为value。
HGET key field:返回哈希表key中给定域field的值。

HMSET / HMGET
HMSET key field value [field value ...]:同时将多个field-value(域-值)对设置到哈希表 key 中。
HMGET key field [field ...]:返回哈希表key中,一个或多个给定域的值。

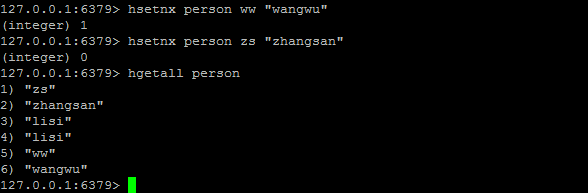
HGETALL / HSETNX
HGETALL key:返回哈希表 key 中,所有的域和值。
HSETNX key field value:将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在。
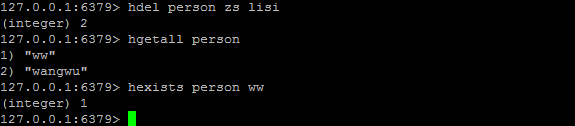
HEXISTS / HDEL
HEXISTS key field:查看哈希表 key 中,给定域 field 是否存在。
HDEL key field [field ...]:删除哈希表 key 中的一个或多个指定域,不存在的域将被忽略。
HINCRBY
HINCRBY key field increment:为哈希表 key 中的域 field 的值加上增量 increment 。
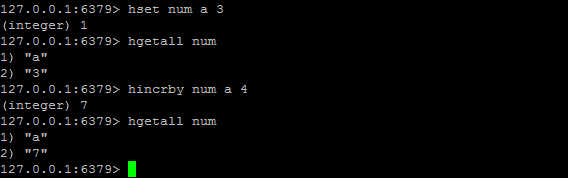
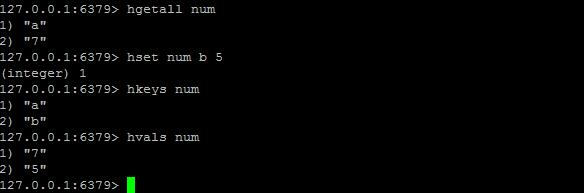
HKEYS / HVALS
HKEYS key:返回哈希表 key 中的所有域。
HVALS key:返回哈希表 key 中所有域的值。
HLEN
HLEN key:返回哈希表 key 中域的数量。

列表(List)
1、list是一个有序的字符串列表,列表内部实现是使用双向链表(linked list)实现的。
2、list还可以作为队列使用
3、一个列表类型的键最多能容纳2^32 - 1个元素。
命令:
LPUSH / RPUSH
LPUSH key value [value ...]:将一个或多个值 value 插入到列表 key 的表头
RPUSH key value [value ...]:将一个或多个值 value 插入到列表 key 的表尾(最右边)。
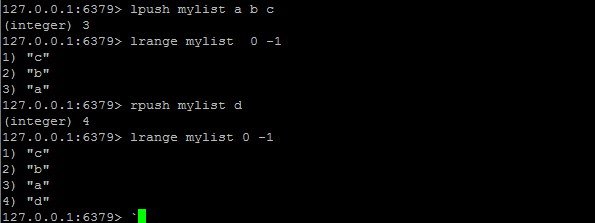
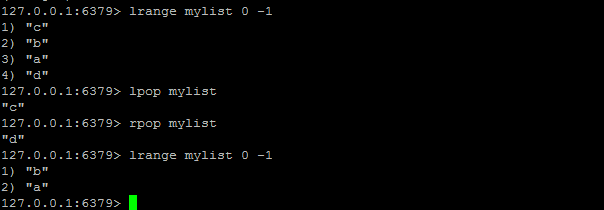
LPOP / RPOP
LPOP key
移除并返回列表 key 的头元素。
RPOP key
移除并返回列表 key 的尾元素。
LLEN
LLEN key:返回列表 key 的长度。
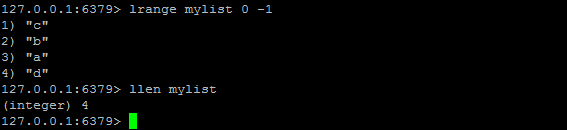
LRANGE
LRANGE key start stop :返回列表 key 中指定区间内的元素,区间以偏移量 start 和 stop 指定。下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。

LINDEX
LINDEX key index:返回列表 key 中,下标为 index 的元素。下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。

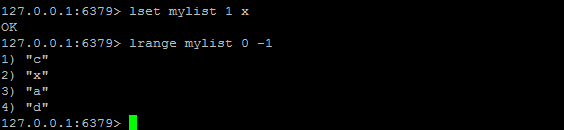
LSET
LSET key index value:将列表 key 下标为 index 的元素的值设置为 value 。
LTRIM
LTRIM key start stop:对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。

RPOPLPUSH
RPOPLPUSH source destination:
命令RPOPLPUSH 在一个原子时间内,执行以下两个动作:
1、将列表 source 中的最后一个元素(尾元素)弹出,并返回给客户端。
2、将 source 弹出的元素插入到列表 destination ,作为 destination 列表的的头元素。

集合(Set)
set集合中的元素都是不重复的,无序的,一个集合类型键可以存储至多2^32 -1个元素
命令:
SADD / SMEMBERS
SADD key member [member ...]:将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。
SMEMBERS key:返回集合 key 中的所有成员。

SREM / SISMEMBER
SREM key member [member ...]:移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略。
SISMEMBER key member:判断 member 元素是否集合 key 的成员。

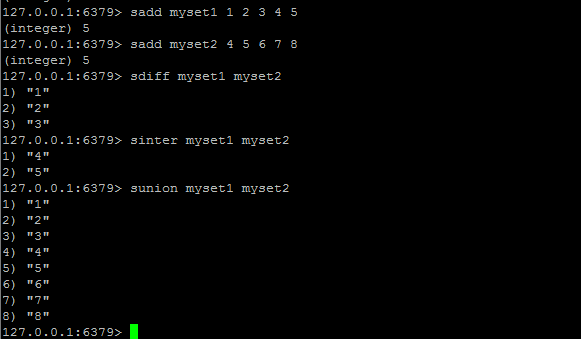
SDIFF / SINTER / SUNION
SDIFF key [key ...]:返回一个集合的全部成员,该集合是所有给定集合之间的差集。
SINTER key [key ...]:返回一个集合的全部成员,该集合是所有给定集合的交集。
SUNION key [key ...]:返回一个集合的全部成员,该集合是所有给定集合的并集。
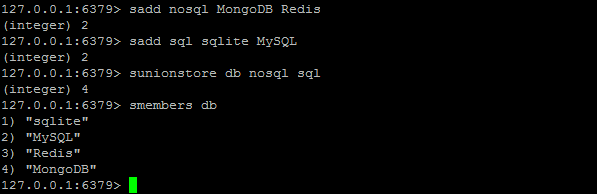
SDIFFSTORE / SINTERSTORE / SUNIONSTORE
SDIFFSTORE destination key [key ...]:这个命令的作用和SDIFFSTORE类似,但它将结果保存到 destination 集合,而不是简单地返回结果集。
SINTERSTORE destination key [key ...]:这个命令类似于SINTERSTORE命令,但它将结果保存到 destination 集合,而不是简单地返回结果集。
SUNIONSTORE destination key [key ...]:这个命令类似于SUNIONSTORE命令,但它将结果保存到 destination 集合,而不是简单地返回结果集。
下面只演示SUNIONSTORE ,其他类似:
SCARD / SPOP
SCARD key:返回集合 key 的基数(集合中元素的数量)。
SPOP key:移除并返回集合中的一个随机元素。

有序集合(Sorted set)
有序集合,在集合类型的基础上为集合中的每个元素都关联了一个分数,这样可以很方便的获得分数最高的N个元素(topN)。
有序集合类型和列表类型的差异
相同点
(1)二者都是有序的
(2)二者都可以获得某一范围的元素
不同点
(1)列表类型是通过双向链表实现的,获取靠近两端的数据速度极快,当列表中元素增多后,访问中间的数据速度会很慢,所以它比较适合很少访问中间元素的应用
(2)有序集合类型是使用散列表和跳跃表(skip list)实现的,所以即使读取位于中间部分的数据速度也很快
(3)列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改这个元素的分值)
(4)有序集合要比列表类型更耗费内存
命令:
ZADD / ZSCORE
ZADD key score member [[score member] [score member] ...]:将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
ZSCORE key member:返回有序集 key 中,成员 member 的 score 值。

ZRANGE / ZREVRANGE
ZRANGE key start stop [WITHSCORES]:返回有序集 key 中,指定区间内的成员。
ZREVRANGE key start stop [WITHSCORES]:返回有序集 key 中,指定区间内的成员。

ZRANGEBYSCORE
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]:返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。

ZINCRBY / ZCARD / ZCOUNT
ZINCRBY key increment member:为有序集 key 的成员 member 的 score 值加上增量 increment 。
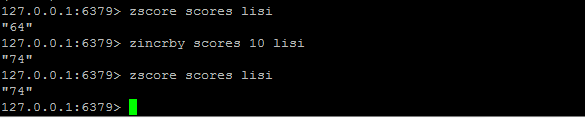
ZCARD / ZCOUNT
ZCARD key:返回有序集 key 的基数。
ZCOUNT key min max:返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。

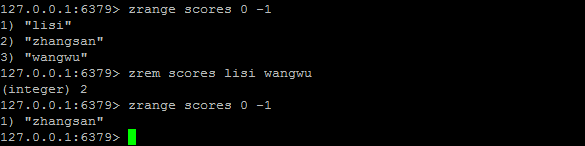
ZREM
ZREM key member [member ...]:移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
HyperLogLog(超重对数)
Redis HyperLogLog 是用来做基数统计的算法。
优点:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。因为在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
缺点:因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
命令:
pfadd key element [element ...]
pfcount key [key ...]
pfmerge destkey sourcekey [sourcekey ...]
注意:Redis的命令很多,详细的可以参考http://redisdoc.com/index.html
Java代码操作Redis
数据库连接方式:
1、单机单连接方式
2、单机连接池方式
3、多机分布式+连接池方式
首先创建Maven项目。然后在pom.xml中指定依赖。
使用jedis第三方jar包操作redis
mvn依赖:
redis.clients
jedis
2.8.0
代码示例:
import java.util.Iterator;
import java.util.Set;
import redis.clients.jedis.Jedis;
public class redisTest {
public static void main(String[] args) throws Exception {
showRedis();
}
//测试redis连接
private static void showRedis() {
//连接redis数据库
Jedis jedis = new Jedis("192.168.33.130", 6379);
//设置 key value
jedis.set("baidu","QQ");
//获取key对应的value
String StrVal = jedis.get("baidu");
System.out.println(StrVal);
//获取数据库中所有keys
System.out.println("数据库中所有键如下:");
Set keys = jedis.keys("*");
Iterator it=keys.iterator() ;
while(it.hasNext()){
String key = it.next();
System.out.println(key);
}
}
} 打印结果:
QQ
数据库中所有键如下:
site
db
person
google
连接池一些配置:
//控制一个pool最多有多少个状态为idle(空闲的)的jedis实例。
poolConfig.setMaxIdle(10);
//控制一个pool最多有多少个jedis实例。
poolConfig.setMaxTotal(100);
//表示当borrow(引入)一个jedis实例时,最大的等待时间,如果超过等待时间,则直接抛出JedisConnectionException;
poolConfig.setMaxWaitMillis(10000);
//在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的;
poolConfig.setTestOnBorrow(true);
连接池工具类:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class redisUtils {
private redisUtils() {}
private static JedisPool jedisPool = null;
//获取链接
public static synchronized Jedis getJedis() {
if(jedisPool == null){
//创建config
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//控制一个pool最多有多少个状态为idle(空闲的)的jedis实例。
jedisPoolConfig.setMaxIdle(10);
//控制一个pool最多有多少个jedis实例。
jedisPoolConfig.setMaxTotal(100);
//表示当borrow(引入)一个jedis实例时,最大的等待时间,如果超过等待时间,则直接抛出JedisConnectionException;
jedisPoolConfig.setMaxWaitMillis(2000);
//在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的;
jedisPoolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool(jedisPoolConfig, "192.168.33.130",6379);
}
//返回连接池资源
return jedisPool.getResource();
}
public static void returnResource(Jedis jedis) {
jedis.close();
}
}工具类使用:
//测试redis连接
private static void showRedis() {
//连接redis数据库
Jedis jedis = redisUtils.getJedis();
//设置 key value
jedis.set("baidu","QQ");
//获取key对应的value
String StrVal = jedis.get("baidu");
System.out.println(StrVal);
//获取数据库中所有keys
System.out.println("数据库中所有键如下:");
Set keys = jedis.keys("*");
Iterator it=keys.iterator() ;
while(it.hasNext()){
String key = it.next();
System.out.println(key);
}
}