用 Python 分析《红楼梦》(2)
6 词频统计
完成分词以后,词频统计就非常简单了。我们只需要根据分词结果把片段切分开,去掉长度为一的片段(也就是单字),然后数一下每一种片段的个数就可以了。
这是出现次数排名前 20 的单词:

(括号内为频数)
可以跟之前只统计出现次数,不考虑切分问题的排名做个对比:

(括号内为频数)
通过分词后的词频,我们发现《红楼梦》中的人物戏份由多到少依次是宝玉、凤姐、贾母、袭人、黛玉、王夫人和宝钗。然而,这个排名是有问题的,因为”林黛玉”这个词的出现次数还有 267 次,需要加到黛玉的戏份里,所以其实黛玉的戏份比袭人多。同理,“老太太”一般是指贾母,所以贾母的戏份加起来应该比凤姐多。正确的排名应该是宝玉、贾母、凤姐、黛玉、袭人、王夫人和宝钗。
此外,我们还发现《红楼梦》中的人物很爱笑,因为除了人名以外出现次数最多的单词就是“笑道” : )
我把完整的词频表做成了一个网页,感兴趣的话可以去看一下:红楼词表 第二版
最后,我随机选择了词频表中的 200 项条目,用来估计其中有多少是真正的单词。其中有 82 条是单词:

而 118 条不是单词:

也就是说,单词的正确率只有 41 %。这比字典的准确率还低,并没有因为采用了分词算法而提高了正确率。不过这也可以理解,因为生成字典的时候我只考虑了出现次数大于 5 的片段,而分词的时候有些单词只出现了一次,所以难度确实应该更大一些。
词频表中总计有 3.99 万个条目。根据估算的词频表中正确单词的比例,我估计《红楼梦》的词汇量大约是 1.6 万。有人用其他程序估计《红楼梦》的词汇量是 0.45 万(http://bbs.creaders.net/politics/bbsviewer.php?trd_id=344894),不过作者没有描述详细的统计方法,所以我对其结果非常怀疑,因为《红楼梦》中的单字就有 0.35 万种了。
7 筛选特征词
终于做完了分词,又离目标靠近了一大步。现在,我可以用之前看到的那篇文章里提到的 PCA 算法来分析章回之间的差异了。不过在此之前,我想先反思一下,到底应该用哪些词的词频来进行分析?
在很多用 PCA 分析《红楼梦》的博文里,大家都是用出现频率最高的词来分析的。然而问题是,万一频率最高的词是和情节变化相关的呢?为了剔除情节变化的影响,我决定选出词频随情节变化最小的单词来作为每一章的特征。而我衡量词频变化的方法就是统计单词在每一回的词频,然后计算标准方差。为了消除单词的常用程度对标准方差的影响,我把标准方差除以该单词在每一回的平均频数,得到修正后的方差,然后利用这个标准来筛选特征词。
按照这个标准,与情节最无关的 20 个词是:

(括号内为修正后的方差)
有趣的是,处在排名末尾的词,也就是词频变化最大的词,大部分都是人名:

可见这个筛选方法确实能去掉我们不想要的特征词。
最终,我选择了词频变化最小的 50 个词作为特征,每个词的修正后标准方差都小于 0.85。这 50 个词如下:

8 主成份分析(PCA)
理论上,有了特征之后,我们就可以比较各个章节的相似性了。然而问题是,现在我们有 50 个特征,也就是说现在的数据空间是 50 维的,这对于想象四维空间都难的人类来说是很难可视化的。对于高维数据的可视化问题来说,PCA 是一个很好用的数学工具。
9.1 何谓是主成份分析
因为高维的数据空间很难想象,所以我们可以先想象一下低维的情况。比如说,假设下图中的每个点都是一个数据,横坐标和纵坐标分别代表两个特征的值:

现在,如果我们让 PCA 程序把这两个特征压缩成一个特征的话,算法就会寻找一条直线,使得数据点都投影到这条直线上后损失的信息最少(如果投影不好理解的话,可以想象用两块平行于直线的板子把数据点都挤压到一条线上)。在这个例子中,这条线损失信息最少的线就是图中较长的那个箭头。这样,如果我们知道了一个数据点在直线上投影的位置,我们就能大致知道数据点在压缩之前的二维空间的位置了(比如是在左上角还是右下角)。
以上是把二维数据空间压缩到一维的情况。三维压缩到二维的情况也是类似的:寻找一个二维平面,使得数据点投影到平面后损失的信息最少,然后把所有数据点投影到这个平面上去。三维压缩到一维就是把寻找平面改成寻找直线。更高维度的情况以此类推,虽然难以想象,但是在数学上是一样的。
至于算法如何找到损失信息最少的二维平面(或者直线、三维平面等等),这会涉及到一些数学知识,感兴趣的同学可以去查找一下相关的数学公式和证明。这里只要把这个算法当成一个黑箱就可以了。
9.2 重大发现?
现在我们可以利用 PCA,把五十个词的词频所构成的五十个维度压缩到二维平面上了。我把压缩后的数据点画出来,发现是这个样子的:
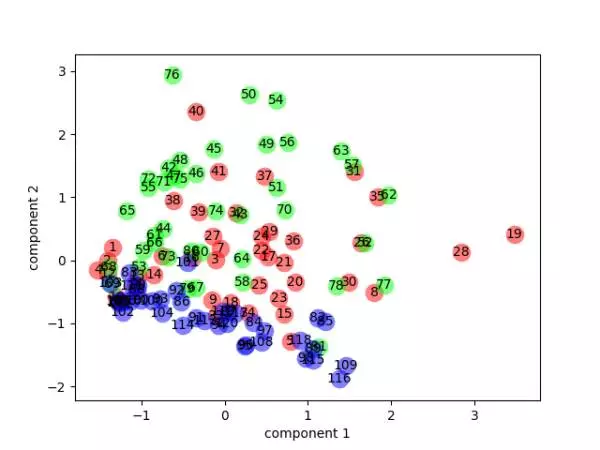
(图中每个圆圈代表一个回目。圆圈内是回目编号,从 1 开始计数。红色圆圈是 1-40 回,绿色圆圈是 41-80回,蓝色圆圈是 81-120 回。)
80 回以后的内容(蓝色)大部分都集中在左下角的一条狭长的区域内,很明显地和其他章回区分开来了!莫非《红楼梦》的最后 40 回真的不是同一个作者写的?!
别着急,分析还没结束。PCA 的一个很重要的优点就是,它的分析结果具有很强的可解释性,因为我们可以知道每一个原始特征在压缩后的特征(或者说成分)中的权重。从上图中可以看到,后 40 回的主要区别在于成分二(component 2)的数值。因此我们可以看一看每一个词的词频在成分 2 中的权重排名:

(括号内为权重)
我发现,“笑道”这个词不仅是除了人名以外出现次数最多的单词,而且在 PCA 结果中的权重也异常地高(0.88),甚至超过了“宝玉”的权重的绝对值(0.31)!为了搞明白这个词为什么有这么大的权重,我把“笑道”的词频变化画了出来:
(图中横坐标是章回编号,纵坐标是“笑道”的词频)
可以发现,“笑道”的词频是先增加再减少的,这不禁让我联想到了贾府兴衰的过程。莫非“笑道”的词频和贾府的发展状况有关?有趣的是,“笑道”的词频顶峰出现在第 50 回左右,而有些人从剧情的角度分析认为贾府的鼎盛时期开始于第 48、49 回,恰好重合:
《红楼梦》之“钗黛合一”带来大观园鼎盛风之子9881198198新浪博客
[转载]白坤峰讲红楼梦(172)贾府鼎盛:该来的都来了史鼎说红楼新浪博客
也许“笑道”这一看似平常的词汇确实侧面反应了贾府的兴衰史呢。虽然因果关系有待考证,不过想想也有一点道理,毕竟只有日子过的好的时候人们才会爱笑。
原文发布时间为:2017-09-22
本文作者:楼宇
本文来自云栖社区合作伙伴“Python中文社区”,了解相关信息可以关注“Python中文社区”微信公众号