python面试题(15题多方法解决正则)(¥29)
还有很多不完善的地方,有看到的大佬,帮忙回复修改下,谢谢了 !
基础问题
01.面相对象的三大特点
封装,继承,多态
02.classmethod、staticmethod、abstractmethod装饰的作用
classmethod:可以用来为一个类创建一些预处理的实例
staticmethod:限制名称空间
abstractmethod:抽象的方法,类是于接口,你可以用具有同一属性的对象实现同一个抽象方法
03.str、repr、init、del、call方法的触发时机
str:强制类型转换的时候
repr:如果找不到str就会找repr方法
init:创建对象后自动调用
del:的触发时机:当一个对象在内存中被销毁的时候会自动执行
call:将对象当函数调用,该方法会自动触发
04.getitem、setitem、delitem方法的触发时机
getitem:将对象做字典操作,根据键获取值时会自动触发
setitem:将对象当做字典操作,添加或设置属性时会自动触发
delitem:将对象当做字典操作,根据键销毁属性时会自动触发
05.enter、exit方法的触发时机
enter 输入内容是触发
exit 失去焦点是触发
06.getattr、setattr、delattr方法的触发时机
getattr当获取不存在的属性时会自动触发
setsttr当设置属性时会自动调用
delattr销毁对象的指定属性时会自动触发
07.实现列表的排序,列表中什么元素都有,需要先去掉非字符串类型的元素,然后按照长度降序排序

def Sort_List(lt):
lt = list(filter(lambda x:isinstance(x,str),lt))
for i in range(len(lt) - 1):
for j in range(len(lt) - 1 - i):
if len(lt[j]) > len(lt[j + 1]):
t = lt[j]
lt[j] = lt[j + 1]
lt[j + 1] = t
return lt
lt = [
'ad',
's',
'sas',
[1,2]
]
print(Sort_List(lt))
08.简述正则的优缺点
正则的优点:对纯文本的处理较好,捕获字符串的能力好,例如截取url的域名
正则的缺点:不适合匹配文本意义,如(匹配多少范围到多少范围的数字就比较麻烦)容易引起性能问题,替换功能比较差,维护性差。
09.正则中的\d、\w、\s、\b的作用是什么
\d:匹配数字字符,等价于[0-9]
\w:匹配字(数字,字母,下划线)
\s:匹配空白字符(\n, \r, \t, 空格)
11.正则中的[]、()、{}的作用是什么
[]:中间的任意一个字符
():表示一个整体
{}:匹配内容数量
10.正则中的*、+、?的作用是什么
*:任意次
+:至少一次
?:至多一次
12.写出邮箱格式匹配的正则表达式
#匹配只用英文字母,数字,下划线,英文语句,以及中划线组成的邮箱
^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
13.写出匹配IPv4格式的IP地址的正则表达式
^((25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))\.){3}(25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))$
14.使用正则提取’GET /index.html HTTP/1.1’中的’/index.html’
import re
s='GET /index.html HTTP/1.1'
l=re.search(r'\W{2,}(.*)\s',s)
print(l.group())
15.使用正则将’get_to_next_page’转换为’getToNextPage’
import re
ret1 = re.search('(\w+)_(\w+)_(\w+)_(\w+)','get_to_next_page')
print(f'{ret1.group(1)}{ret1.group(2).title()}{ret1.group(3).title()}{ret1.group(4).title()}')





16.写一个Bash Shell脚本获取当前日期、时间、用户名
(自动化运维(重要是保护所有的运行功能),测试必备)
一个shell就是一个编程语言
Bash Shell是liunx的
echo -n The time and date are:
date
echo "Let's see who's logged into the system:"
who
17.正则表达式贪婪模式与非贪婪模式的区别
贪婪匹配:最大限度的匹配
非贪婪匹配:只要满足条件,能少匹配就少匹配。可以使用’?'取消贪婪
18.深拷贝浅拷贝的区别(冯诺依曼都有)
深拷贝:拷贝对象本身,对象中的元素也进行拷贝(内存中添加新的空间地址)

浅拷贝:只拷贝对象本身,里面的元素只会增加一个引用

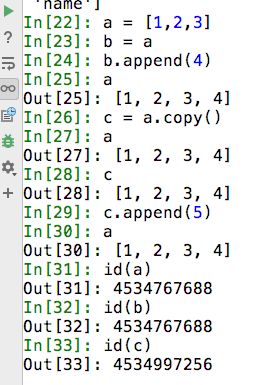
19.什么是函数式编程,举例说明python中的函数式编程(lambda)匿名函数
查询
当参数传递

可以作为返回值
函数式编程:纯粹的函数式编程语言编写的函数没有变量,任意一个函数,只要输入是确定的,输出就是确定的。
a_list= [item**2 for item in range(5)]
print(a_list)
20.结合实际说明你在web项目中如何提高并发性能(uwsgi)
1.工具(django,flask)33分+++++++
使用redis(负载均衡)的管道来打包多条无关命令批量执行,以减少多个命令分别执行带来的网络交互时间
21.阐明一个数据分析的基本流程
1,分析特征值
2,分解data和target
3,交叉验证
4,模型参数自动调优
5.数据可视化
22.什么是ajax跨域,如何解决

1.跨域,当两个地址出现,域名,端口号不一样,(原地址和目标地址)自我保护

解决:客户端(jsonp)和服务器端解决
跨域,指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器对JavaScript施加的安全限制。
解决:1.可以使用jsonp
2.服务器代理
3.在服务端设置response header中Access-Control-Allow-Origin字段。
23.写出一个选择排序算法(必背)
a=[6,5,4,3,2,1]
min_index=0
for i in range(len(a)-1):
min_index=i #每次i变化时,将最小下标值改为i,将本次循环第一个位置的值
for j in range(i+1,len(a)):
if a[min_index]>a[j]:
print(min_index)
a[i],a[min_index]=a[min_index],a[i]
print(a)
24.深度优先搜索和广度优先搜索的区别(爬虫)
深度优先遍历:从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点的第一个未被访问的邻结点,然后再以此邻结点为顶点,继续找它的下一个新的顶点进行访问,重复此步骤,直到所有结点都被访问完为止。
广度优先遍历:从某个顶点出发,首先访问这个顶点,然后找出这个结点的所有未被访问的邻接点,访问完后再访问这些结点中第一个邻接点的所有结点,重复此方法,直到所有结点都被访问完为止。
两种方法最大的区别在于前者从顶点的第一个邻接点一直访问下去再访问顶点的第二个邻接点;后者从顶点开始访问该顶点的所有邻接点再依次向下,一层一层的访问。
25.解释开发中出现乱码问题的原因(2.21分)
使用不同字库上的编码序号进行了解码操作.
26.爬虫工作中如何破解极验验证码(爬虫)
![]()
第一步:使用Selenium打开网页,并输入信息,点击查询按钮
第二步:保存验证码图片
第三步:计算缺口距离
第四步:计算滑动轨迹
第五步:移动滑块
27.requests访问为什么要带上header(欺骗目标网站)
因为header中包含request headers 和response headers 以此获取页面信息,提供了与报文相关的最基本的信息,通用头域包含 Connection 允许客户端和服务器指定与请求/响应连接有关的选项
28.假如每天爬取量在 5、6 万条数据,一般开几个线程,每个线程 ip 需要加锁限定吗?2.30
10个 需要
29.怎么监控爬虫的状态
在scrapy中我们可以使用signals来实现
使用signals机制来插入日志并实时更新spider的运行和数据爬取状态
30.解释并行和并发
并行:是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
编程题
1.一只青蛙一次可以跳一级或二级台阶,请问跳n级台阶需要跳多少方法(递归)
但是递归(理论多了会报错(堆栈深度限制))




对于这个问题
前三次都好算分别为1,2,3次,后面多的话不好简单计算
当第n级台阶时,因为青蛙只能跳一级或二级台阶,所以第n级只有两种方法跳过来,
即,从前一级(n-1)或前两级(n-2),所以调到这两级的方法加起来即为n级方法总数
现在构成斐波那契数列(fěi bō nà qì shù liè)
注意
这个是斐波那契的变种,斐波那契为 1 1 2 3 5 8
现在这个问题为 1 2 3 5 8
仅仅少了个1,代码稍加改动即可
下面代码都是基于1 2 3 5 8实现的
1.斐波那契问题最简单的是递归实现,但是递归运行效率太低,而且python有最大递归深度,我试了一下基本上递归900次都需要很长时间.所以只简单写出来参考,不推荐
可以用循环来做,毕竟递归堆栈深度有限制