关于淘淘商城的一些基本说明
关于淘淘商城的一些基本说明
1. maven
Maven的常见打包方式:jar、war、pom
Pom工程一般都是父工程,管理jar包的版本、maven插件的版本、统一的依赖管理。聚合工程。
jar包就是java的类进行编译生成的class文件打包成的压缩包。里面就是一些class文件。当我们自己使用maven写一些java程序,进行打包生成jar包。同时在可以在其他的工程下使用,但是我们在这个工程依赖的jar包,在其他工程使用该jar包也要导入。JAR 文件不仅用于压缩和发布,而且还用于部署和封装库、组件和插件程序,并可被像编译器和 JVM 这样的工具直接使用。
war包其实就是一个web程序进行打包便于部署的压缩包,里面包含我们web程序需要的一些东西,其中包括一些class文件,web.xml的配置文件,前端的页面文件,以及依赖的jar!把war包放在tomcat目录的webapp下,tomcat服务器在启动的时候自动解压war包编译里面的代码,所以当文件很多的时候,tomcat的启动会很慢。一个war包可以理解为一个web项目,里面是项目的所有东西。
其中运行一个maven工程(web工程)需要一个命令:tomat:run
例如:
Taotao-parent:父工程,打包方式pom,管理jar包的版本号,项目中所有工程都应该继承父工程。
|--Taotao-common:通用的工具类通用的pojo。打包方式jar
|--Taotao-manager:服务层工程。聚合工程。Pom工程
|--taotao-manager-dao:打包方式jar
|--taotao-manager-pojo:打包方式jar
|--taotao-manager-interface:打包方式jar
|--taotao-manager-service:打包方式:war
|--taotao-manager-web:表现层工程。打包方式war
步骤
- 下载maven安装包并解压,路径不要有中文。
apache官网maven下载 - 在Path中配置MAVEN_HOME和path(path中加上bin目录)的路径
- maven安装路径下\conf\settings.xml文件中有本地仓库的配置

- 在终端中运行mvn - v检查maven是否安装成功
在ecplise下配置maven

点击”Add”,进入下面的页面

然后在eclipse中配置仓库的位置

maven仓库地址、私服等配置信息需在setting.xml文件中配置,分为全局配置和用户配置,在maven安装目录下的有 conf/setting.xml文件,此setting.xml文件用于maven的所有project项目,它作为maven的全局配置。如需要个性配置则需要在用户配置中设置,用户配置的setting.xml文件默认的位置在: u s e r . d i r / . m 2 / s e t t i n g s . x m l 目 录 中 , {user.dir} /.m2/settings.xml目录中, user.dir/.m2/settings.xml目录中,{user.dir} 指windows 中的用户目录。maven会先找用户配置,如果找到则以用户配置文件为准,否则使用全局配置文件。
maven的一些标签解释
懒得写了,可以在官方文档上查 maven官方文档
有位博主根据官方文档总结的也不错,可以去看看
https://blog.csdn.net/xupeng874395012/article/details/72921857
2.逆向工程
使用mybatis官方提供的mybatis-generator生成pojo、mapper接口及映射文件。
并且将pojo放到toatao-manager-pojo工程中。
将mapper接口及映射文件放到taotao-manager-dao工程中。
https://blog.csdn.net/qq_39056805/article/details/80585941
3. dubbo
Dubbo采用全Spring配置方式,透明化接入应用,对应用没有任何API侵入,只需用Spring加载Dubbo的配置即可,Dubbo基于Spring的Schema扩展进行加载。
例如:
发布服务:
在服务提供方和服务消费方的pom.xml中添加Dubbo依赖的jar包:
com.alibaba
dubbo
org.springframework
spring
org.jboss.netty
netty
org.apache.zookeeper
zookeeper
com.github.sgroschupf
zkclient
在Spring的配置文件中添加Dubbo约束:
xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd
Dubbo的监控中心。。
4. zookeeper
Zookeeper的安装:
第一步:安装jdk
第二步:解压缩zookeeper压缩包
第三步:将conf文件夹下zoo_sample.cfg复制一份,改名为zoo.cfg
第四步:修改配置dataDir属性,指定一个真实目录
第五步:
启动zookeeper:bin/zkServer.sh start
关闭zookeeper:bin/zkServer.sh stop
查看zookeeper状态:bin/zkServer.sh status
注意要关闭linux的防火墙。
5.图片服务器FastDFS
分布式文件系统FastDFS(用来专门保存图片)
使用FastDFS,分布式文件系统。存储空间可以横向扩展,可以实现服务器的高可用。支持每个节点有备份机。
- 什么是FastDFS?
FastDFS是用c语言编写的一款开源的分布式文件系统。FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。 - FastDFS架构
FastDFS架构包括 Tracker server和Storage server。客户端请求Tracker server进行文件上传、下载,通过Tracker server调度最终由Storage server完成文件上传和下载。 Tracker server作用是负载均衡和调度,通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务。可以将tracker称为追踪服务器或调度服务器。 Storage server作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是利用操作系统 的文件系统来管理文件。可以将storage称为存储服务器。

服务端两个角色:Tracker:管理集群,tracker也可以实现集群。每个tracker节点地位平等。收集Storage集群的状态。Storage:实际保存文件Storage分为多个组,每个组之间保存的文件是不同的。每个组内部可以有多个成员,组成员内部保存的内容是一样的,组成员的地位是一致的,没有主从的概念。
- 文件上传的流程

客户端上传文件后存储服务器将文件ID返回给客户端,此文件ID用于以后访问该文件的索引信息。文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名。
![]()
组名:文件上传后所在的storage组名称,在文件上传成功后有storage服务器返回,需要客户端自行保存。
虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项store_path*对应。如果配置了store_path0则是M00,如果配置了store_path1则是M01,以此类推。
数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
- 文件下载

- 最简单的FastDFS架构

服务器安装方法见5.1
6.redis的配置与redis集群的搭建
Redis是c语言开发的。
安装redis需要c语言的编译环境。如果没有gcc需要在线安装。yum install gcc-c++
安装步骤:第一步:redis的源码包上传到linux系统。第二步:解压缩redis。第三步:编译。进入redis源码目录。make 第四步:安装。make install PREFIX=/usr/local/redisPREFIX参数指定redis的安装目录。一般软件安装到/usr目录下
redis的启动:
前端启动:在redis的安装目录下直接启动redis-server
[root@localhost bin]# ./redis-server
后台启动:把/root/redis-3.0.0/redis.conf复制到/usr/local/redis/bin目录下
[root@localhost redis-3.0.0]# cp redis.conf /usr/local/redis/bin/
修改配置文件:

[root@localhost bin]# ./redis-server redis.conf
查看redis进程:
[root@localhost bin]# ps aux|grep redis
Redis-cli
[root@localhost bin]# ./redis-cli
默认连接localhost运行在6379端口的redis服务。
[root@localhost bin]# ./redis-cli -h 192.168.25.153 -p 6379
-h:连接的服务器的地址
-p:服务的端口号
关闭redis:[root@localhost bin]# ./redis-cli shutdown
Redis的持久化方案
Redis的所有数据都是保存到内存中的。Rdb:快照形式,定期把内存中当前时刻的数据保存到磁盘。Redis默认支持的持久化方案。aof形式:append only file。把所有对redis数据库操作的命令,增删改操作的命令。保存到文件中。数据库恢复时把所有的命令执行一遍即可。
两种持久化方案同时开启使用aof文件来恢复数据库。
Jedis
需要把jedis依赖的jar包添加到工程中。Maven工程中需要把jedis的坐标添加到依赖。 推荐添加到服务层。Taotao-content-Service工程中。
- 连接单机版
第一步:创建一个Jedis对象。需要指定服务端的ip及端口。
第二步:使用Jedis对象操作数据库,每个redis命令对应一个方法。
第三步:打印结果。
第四步:关闭Jedis
- 连接单机版使用连接池
第一步:创建一个JedisPool对象。需要指定服务端的ip及端口。
第二步:从JedisPool中获得Jedis对象。
第三步:使用Jedis操作redis服务器。
第四步:操作完毕后关闭jedis对象,连接池回收资源。
第五步:关闭JedisPool对象。
- 连接集群版
第一步:使用JedisCluster对象。需要一个Set< HostAndPort>参数。Redis节点的列表。
第二步:直接使用JedisCluster对象操作redis。在系统中单例存在。
第三步:打印结果
第四步:系统关闭前,关闭JedisCluster对象。
添加缓存功能:
查询内容列表时添加缓存。
1、查询数据库之前先查询缓存。
2、查询到结果,直接响应结果。
3、查询不到,缓存中没有需要查询数据库。
4、把查询结果添加到缓存中。
5、返回结果。
向redis中添加缓存:
Key:cid
Value:内容列表。需要把java对象转换成json。
使用hash对key进行归类。
HASH_KEY:HASH
|–KEY:VALUE
|–KEY:VALUE
|–KEY:VALUE
|–KEY:VALUE
代码的实现:
@Override
public List getContentList(long cid) {
//查询缓存
try {
String json = jedisClient.hget(CONTENT_KEY, cid + "");
//判断json是否为空
if (StringUtils.isNotBlank(json)) { /
/把json转换成list
List list = JsonUtils.jsonToList(json, TbContent.class); return list;
}
} catch (Exception e) {
e.printStackTrace();
}
//根据cid查询内容列表
TbContentExample example = new TbContentExample();
//设置查询条件
Criteria criteria = example.createCriteria();
criteria.andCategoryIdEqualTo(cid);
//执行查询
List list = contentMapper.selectByExample(example);
//向缓存中添加数据
try {
jedisClient.hset(CONTENT_KEY, cid + "", JsonUtils.objectToJson(list));
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
缓存同步:
对内容信息做增删改操作后只需要把对应缓存删除即可。可以根据cid删除。
@Override
public TaotaoResult addContent(TbContent content) {
//补全属性
content.setCreated(new Date());
content.setUpdated(new Date());
//插入数据
contentMapper.insert(content);
//缓存同步
jedisClient.hdel(CONTENT_KEY, content.getCategoryId().toString());
return TaotaoResult.ok();
}
7.solr服务器的搭建,solr集群与zookeeper集群的问题
solr需要安装JDK,需要安装Tomcat
搭建步骤
第一步:把solr 的压缩包上传到Linux系统
第二步:解压solr。
第三步:安装Tomcat,解压缩即可。
第四步:把solr部署到Tomcat下。
第五步:解压缩war包。启动Tomcat解压。
第六步:把/root/solr-4.10.3/example/lib/ext目录下的所有的jar包,添加到solr工程中。[root@localhost ext]# pwd
/root/solr-4.10.3/example/lib/ext
[root@localhost ext]# cp * /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
第七步:创建一个solrhome。/example/solr目录就是一个solrhome。复制此目录到/usr/local/solr/solrhome
[root@localhost example]# pwd
/root/solr-4.10.3/example
[root@localhost example]# cp -r solr /usr/local/solr/solrhome
[root@localhost example]#
第八步:关联solr及solrhome。需要修改solr工程的web.xml文件。

第九步:启动Tomcat
http://192.168.25.154:8080/solr/
和windows下的配置完全一样。
使用solrJ管理索引库
添加文档:
第一步:把solrJ的jar包添加到工程中。
第二步:创建一个SolrServer,使用HttpSolrServer创建对象。
第三步:创建一个文档对象SolrInputDocument对象。
第四步:向文档中添加域。必须有id域,域的名称必须在schema.xml中定义。
第五步:把文档添加到索引库中。
第六步:提交。
删除文档:
第一步:创建一个SolrServer对象。
第二步:调用SolrServer对象的根据id删除的方法。
第三步:提交。
查询索引库:
第一步:创建一个SolrServer对象
第二步:创建一个SolrQuery对象。
第三步:向SolrQuery中添加查询条件、过滤条件。。。
第四步:执行查询。得到一个Response对象。
第五步:取查询结果。
第六步:遍历结果并打印。
什么是SolrCloud:
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
Solr集群的系统架构:

1.1. 物理结构
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
1.2. 逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
1.2.1. collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+…+shardX 1
.2.2. Core
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
1.2.3. Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
1.2.4. Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。

zookeeper作为集群的管理工具。
1、集群管理:容错、负载均衡。
2、配置文件的集中管理
3、集群的入口 需要实现zookeeper 高可用。
需要搭建集群。建议是奇数节点。需要三个zookeeper服务器。 搭建solr集群需要7台服务器。
搭建伪分布式:
需要三个zookeeper节点需要四个tomcat节点。 建议虚拟机的内容1G以上。
- zookeeper集群搭建步骤和solr集群的搭建看day07
- spring配置全局异常处理器
8.activeMQ消息队列
什么是ActiveMQ:
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
主要特点:
- 多种语言和协议编写客户端。语言: Java, C, C++, C#, Ruby, Perl, Python, PHP。应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
- 完全支持JMS1.1和J2EE 1.4规范 (持久化,XA消息,事务)
- 对Spring的支持,ActiveMQ可以很容易内嵌到使用Spring的系统里面去,而且也支持Spring2.0的特性4. 通过了常见J2EE服务器(如 Geronimo,JBoss
- GlassFish,WebLogic)的测试,其中通过JCA 1.5 resource adaptors的配置,可以让ActiveMQ可以自动的部署到任何兼容J2EE 1.4 商业服务器上
- 支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
- 支持通过JDBC和journal提供高速的消息持久化
- 从设计上保证了高性能的集群,客户端-服务器,点对点
- 支持Ajax
- 支持与Axis的整合
- 可以很容易得调用内嵌JMS provider,进行测试
ActiveMQ的消息形式:
对于消息的传递有两种类型:
一种是点对点的,即一个生产者和一个消费者一一对应;
另一种是发布/订阅模式,即一个生产者产生消息并进行发送后,可以由多个消费者进行接收。
JMS定义了五种不同的消息正文格式,以及调用的消息类型,允许你发送并接收以一些不同形式的数据,提供现有消息格式的一些级别的兼容性。
· StreamMessage – Java原始值的数据流
· MapMessage–一套名称-值对
· TextMessage–一个字符串对象
· ObjectMessage–一个序列化的 Java对象
· BytesMessage–一个字节的数据流
ActiveMQ的安装:
进入http://activemq.apache.org/下载ActiveMQ
安装环境:
1、需要jdk
2、安装Linux系统。生产环境都是Linux系统。
安装步骤:
第一步: 把ActiveMQ 的压缩包上传到Linux系统。
第二步:解压缩。
第三步:启动。
使用bin目录下的activemq命令启动:
[root@localhost bin]# ./activemq start
关闭:
[root@localhost bin]# ./activemq stop
查看状态:
[root@localhost bin]# ./activemq status
注意:如果ActiveMQ整合spring使用不要使用activemq-all-5.12.0.jar包。建议使用5.11.2
进入管理后台:
http://192.168.25.168:8161/admin
用户名:admin
密码:admin

Activemq的使用方法及与Spring的整合
9.静态页面freemaker
商品详情页面展示,动态展示 jsp + redis
使用freemarker实现网页静态化
ActiveMq同步生成静态网页
什么是freemarker:
https://blog.csdn.net/culous/article/details/69948531
FreeMarker是一个用Java语言编写的模板引擎,它基于模板来生成文本输出。FreeMarker与Web容器无关,即在Web运行时,它并不知道Servlet或HTTP。它不仅可以用作表现层的实现技术,而且还可以用于生成XML,JSP或Java 等。
目前企业中:主要用Freemarker做静态页面或是页面展示
使用步骤:
第一步:创建一个Configuration对象,直接new一个对象。构造方法的参数就是freemarker对于的版本号。
第二步:设置模板文件所在的路径。
第三步:设置模板文件使用的字符集。一般就是utf-8.
第四步:加载一个模板,创建一个模板对象。
第五步:创建一个模板使用的数据集,可以是pojo也可以是map。一般是Map。
第六步:创建一个Writer对象,一般创建一FileWriter对象,指定生成的文件名。第
七步:调用模板对象的process方法输出文件。
第八步:关闭流。
网页的静态化方案:
输出文件的名称:商品id+“.html”
输出文件的路径:工程外部的任意目录。
网页访问:使用nginx访问网页。在此方案下tomcat只有一个作用就是生成静态页面。
工程部署:可以把taotao-item-web部署到多个服务器上。
生成静态页面的时机:商品添加后,生成静态页面。可以使用Activemq,订阅topic(商品添加)

商品详情模块实现
通过solr全文搜索找到商品;通过商品id去redis中找当前id的缓存,找不到去数据库中查找并添加到缓存中;
(为了提高redis的高可用,把不常访问的商品从redis缓存中清除:使用定时)
每次点击都会把key的时间重置,当key在他的生命中没有被点击就会从redis中清除,再次访问时再次添加。
两方面影响用户访问速度:
数据库查询
使用缓存
服务器生成html页面
使用freemaker生成静态页面
Freemaker生成静态页面的时机
添加商品后使用activemq广播消息,freemaker监听到消息去数据库查询商品生成静态页面为什么不去redis中。
获取商品信息,添加商品时还没有存到redis中为什么不直接使用商品信息还要到数据库中查询:不在一个项目中传输数据麻烦,也起不到提高效率的作用;而且修改数据时也要修改静态页面。
Redis存储数据库表信息;
Key: 表名?字段
Value: 字段值
两种方案:
一 redis缓存
二 网页静态化
10.nginx服务器的搭建
什么是nginx:
Nginx是一款高性能的http 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。由俄罗斯的程序设计师Igor Sysoev所开发,官方测试nginx能够支支撑5万并发链接,并且cpu、内存等资源消耗却非常低,运行非常稳定。
应用场景:
1、http服务器。Nginx是一个http服务可以独立提供http服务。可以做网页静态服务器。
2、虚拟主机。可以实现在一台服务器虚拟出多个网站。例如个人网站使用的虚拟主机。
3、反向代理,负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理。并且多台服务器可以平均分担负载,不会因为某台服务器负载高宕机而某台服务器闲置的情况。
nginx安装:
官方网站:http://nginx.org/使用的版本是1.8.0版本。
安装环境:
1、需要安装gcc的环境。yum install gcc-c++
2、第三方的开发包。
PCRE:
PCRE(Perl Compatible Regular Expressions)是一个Perl库,包括 perl 兼容的正则表达式库。nginx的http模块使用pcre来解析正则表达式,所以需要在linux上安装pcre库。yum install -y pcre pcre-devel
注:pcre-devel是使用pcre开发的一个二次开发库。nginx也需要此库。
zlib:
zlib库提供了很多种压缩和解压缩的方式,nginx使用zlib对http包的内容进行gzip,所以需要在linux上安装zlib库。
yum install -y zlib zlib-devel
openssl:
OpenSSL 是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及SSL协议,并提供丰富的应用程序供测试或其它目的使用。
nginx不仅支持http协议,还支持https(即在ssl协议上传输http),所以需要在linux安装openssl库。
yum install -y openssl openssl-devel
安装步骤:
第一步:把nginx的源码包上传到linux系统
第二步:解压缩[root@localhost ~]# tar zxf nginx-1.8.0.tar.gz
第三步:使用configure命令创建一makeFile文件。
./configure
–prefix=/usr/local/nginx
–pid-path=/var/run/nginx/nginx.pid
–lock-path=/var/lock/nginx.lock
–error-log-path=/var/log/nginx/error.log
–http-log-path=/var/log/nginx/access.log
–with-http_gzip_static_module
–http-client-body-temp-path=/var/temp/nginx/client
–http-proxy-temp-path=/var/temp/nginx/proxy
–http-fastcgi-temp-path=/var/temp/nginx/fastcgi
–http-uwsgi-temp-path=/var/temp/nginx/uwsgi
–http-scgi-temp-path=/var/temp/nginx/scgi
注意:启动nginx之前,上边将临时文件目录指定为/var/temp/nginx,需要在/var下创建temp及nginx目录
[root@localhost sbin]# mkdir /var/temp/nginx/client -p
第四步:make
第五步:make install
启动nginx:
进入sbin目录
[root@localhost sbin]# ./nginx

关闭nginx:
[root@localhost sbin]# ./nginx -s stop
推荐使用:
[root@localhost sbin]# ./nginx -s quit
重启nginx:
1、先关闭后启动。
2、刷新配置文件:
[root@localhost sbin]# ./nginx -s reload
访问nginx:

默认是80端口。注意:是否关闭防火墙。
- 配置虚拟主机 (http服务器)
- 反向代理
- 负载均衡
软负载,硬负载
F5硬负载第四层负载 :传输层负载
nginx是第七层应用层负载
LVS实现第四层的软负载,能实现F5的60的负载功能 - 高可用
11.sso单点登陆系统
什么是sso系统:
SSO英文全称Single Sign On,单点登录。SSO是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。它包括可以将这次主要的登录映射到其他应用中用于同一个用户的登录的机制。它是目前比较流行的企业业务整合的解决方案之一。
购物车业务逻辑:
1、从cookie中查询商品列表。
2、判断商品在商品列表中是否存在。
3、如果存在,商品数量相加。
4、不存在,根据商品id查询商品信息。
5、把商品添加到购车列表。
6、把购车商品列表写入cookie。
小结
使用cookie实现购物车:
优点:1、实现简单2、不需要占用服务端存储空间。
缺点:1、存储容量有限2、更换设备购车信息不能同步。
实现购车商品数据同步:
1、要求用户登录。
2、把购物车商品列表保存到数据库中。推荐使用redis(用户会频繁操作购物车)。
3、Key:用户id,value:购车商品列表。推荐使用hash,hash的field:商品id,value:商品信息。Key 用户id
Value
Key 商品id
Value 商品json
4、在用户未登录情况下写cookie。当用户登录后,访问购物车列表时,
a) 把cookie中的数据同步到redis。
b) 把cookie中的数据删除
c) 展示购物车列表时以redis为准。
d) 如果redis中有数据cookie中也有数据,需要做数据合并。相同商品数量相加,不同商品添加一个新商品。
5、如果用户登录状态,展示购物车列表以redis为准。如果未登录,以cookie为准
12.mybatis分页插件pagehelper
13.项目部署
项目架构讲解:
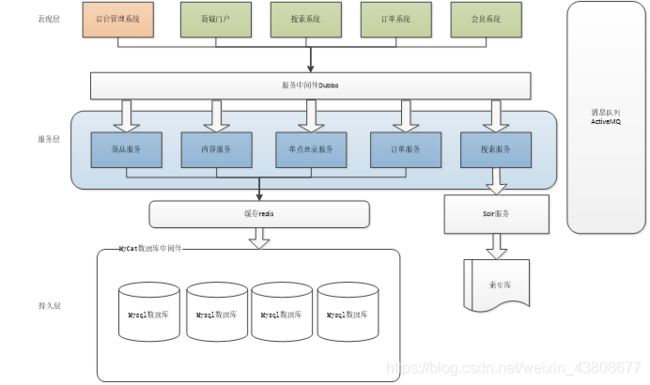
网络拓扑图:
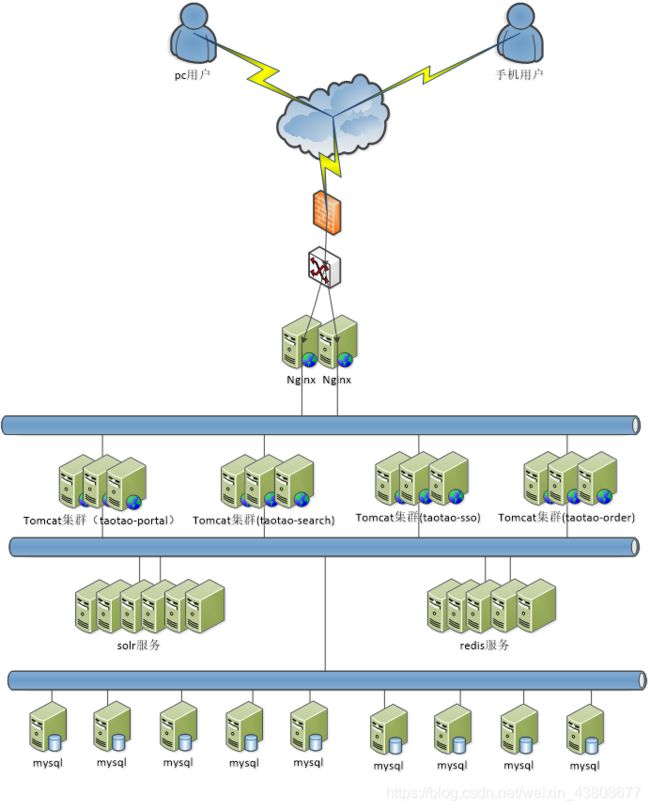 系统部署:
系统部署:
部署分析
Taotao-manager
Taotao-manager-web
Taotao-portal-web
Taotao-content
Taotao-searchT
aotao-search-web
Taotao-item-web
Taotao-sso
Taotao-sso-web
Taotao-cart-web
Taotao-order
Taotao-order-web
需要24台服务器。 24
Mysql 2
Solr 7
Redis 6
图片服务器 2
Nginx 2
注册中心 3
Activemq 2
共需要48台服务器。
项目部分详解:
商品管理:

1.1商品查询业务:
查询所有的商品信息,商品的分页采用的是pagehelp插件,将商品信息查询出来的信息放到pageinfo对象里面,设置分页信息,当前页和每页显示多少条数据,第一次查询的时候会先查询redis里面有没有数据,如果有 直接取出来,取出来的是一个json,需要将json转化成对象,如果没有就从数据里面查出来,同时会存进redis里面去。(总之第一次查询的时候必须是先走redis)
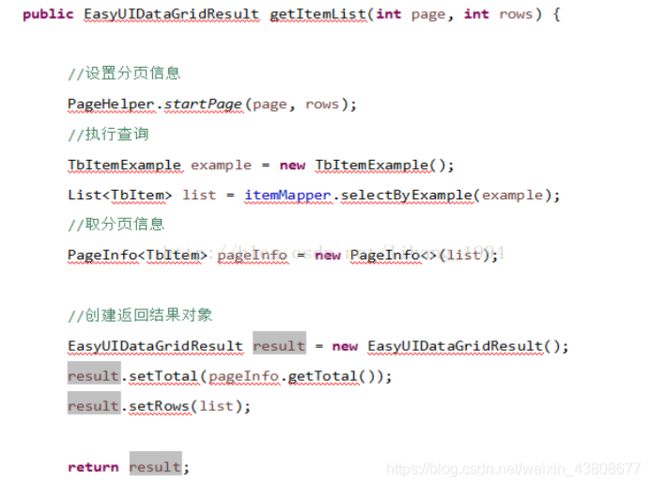
1.2商品添加业务:
在商品添加界面录入商品信息,商品的id,商品标题,商品卖点,商品价格,库存数量,商品条形码,商品图片,商品类别,商品状态(1-正常,2-下架,3-删除’),创建时间,更新时间,商品的描述。其中图片存储考虑到数量比较多,采用的是分布式文件存储系统(fastdfs),图片多了可以搭建集群。商品的描述采用的是富文本编辑器,将录入的商品信息分别插入对应的不同的表,商品添加时还需要和redis数据库进行同步,同时也会添加到redis里面去做缓存。
图片上传操作的步骤:

商品类目管理:
2.1商品类目查询业务:
商品分类列表,使用EasyUI的tree控件展示,前端需要返回的json数据字段有,id,text,state;text:节点的名称,state:如果节点下有子节点“closed”,如果没有子节点“open”。数据的显示采用的是异步加载。点击父节点才会加载父节点下的子节点。查询的条件是parent_id父节点的id,默认值我们给的是0,根据parent_id作为条件查询出来的数据,封装在自己定义的pojo里面,然后在转化成json,回显给界面 。
2.2商品类目添加业务:
在某个节点上添加信息,首先拿到该节点的id,插入一条数据时,将id当成父节点的字段插入进去,如果之前的节点有叶子节点就不用管,没有叶子节点,要把之前的状态改成有子节点的状态。
网站内容管理(CMS)
3.1内容分类查询业务:
内容分类列表,使用EasyUI的tree控件展示,前端需要返回的json数据字段有,id ,text,state;text:节点的名称,state:如果节点下有子节点“closed”,如果没有子节点“open”。数据的显示采用的是异步加载。点击父节点才会加载父节点下的子节点。查询的条件是parent_id父节点的id,默认值我们给的是0,根据parent_id作为条件查询出来的数据,封装在自己定义的pojo里面,然后在转化成json,回显给界面
3.2重命名业务:
根据id查询该节点的对象,拿到这个对象之后,修改该对象的名字。改完之后把该对象当做参数去修改
3.3删除业务:
根据id修改对应表里面的删除字段状态,1表示存在,0表示删除,删除节点的同时还需要判断该节点的父节点是否有子节点存在,如果不存在,要把父节点的那条数据的状态改成没有子节点
3.4内容查询业务
根据内容的分类,查询对应分类的广告内容信息。拿到内容分类id,在内容管理表里面查询,在将返回的对象转换成json数据显示在页面。
3.5内容删除业务
删除是改变对应数据里面对应的状态,如果需要同步到redis里面去,还需要把redis里面对应的K删掉,下次再查询的的时候,发现redis没有对应的k,会再次同步到redis中去。
广告位
1.轮播图业务
选中大广告节点,拿到内容分类大广告的id,在内容管理里面插入数据,进入到大广告添加的界面录入信息,内容的标题,内容的子标题,内容的描述,url地址,图片信息,内容,图片使用的是fastdfs,内容采用的是富文本编辑器。添加之后需要和redis进行同步。下次回显数据的时候从redis里面查,如果没有就从数据里面查询
商品搜索
5.1同步solr库业务
在solr配置文件schema.xml中定义要搜索的域,里面有商品Id,商品标题,商品卖点,商品价格,商品图片,分类名称,商品描述。首先查询出所有的商品数据,查询出来之后再创建一个solrServer对象。在为每个商品创建一个SolrInputDocument对象,将查询出来的商品数据循环遍历添加到SolrInputDocument对象里面去,在将SolrInputDocument对象添加到SolrServer对象里面。
5.2商品搜索业务
商品搜索用到了solr技术,根据IK分词器,对查询的条件进行查询,首先创建一个SolrQuery对象作为商品搜索的查询条件,设置分页条件,指定默认的搜索域,设置高亮,执行查询,计算出总页数和总条数,返回一个QueryResponse结果集,在将结果集循环遍历添加到自己定义的集合里面,返回给页面,一个商品的图片有多个地址,需要将图片的地址分切转化成数组,页面显示的时候取数组的下标为0,取出一张图片就可以了。 
商品详情页:
商品详情页采用的是FreeMarker模板引擎技术,生成一个静态化页面。这样能减轻服务器的压力。首先创建一个Configuration对象,这个对象有个参数,参数是FreeMarker的版本号,拿到这个Configuration对象之后设置模板所在的路径,在设置模板文件使用的字符集,设置完之后加载一个模板,创建一个模板对象,模板创建之后会把查询出来的数据放到模板里面。
购物车:
购物车的实现功能考虑到两种情况,登录的时候商品存在哪里,没有登录的时候商品信息存在哪里。没有登录的时候我们将商品信息保存在cookie里面,在保存之前我们会先在cookie里面先查询有没有该商品,如果该商品存在只需要修改该商品的数量即可,如果cookie里面不存在,就把商品信息添加到cookie里面去。登录的时候我们将商品保存到redis里面去,这个时候需要将cookie和redis里面的商品进行合并,同时需要删除cookie里面的数据。
SSO
用户注册业务:
客户端发送请求到后台,需要校验用户名和密码不能为空,用户名,电话,邮箱是否已经被使用,如果都通过将接受到的密码用MD5进行加密,然后在插入到数据里面去。
用户登录业务:
在登录界面输入用户名和密码之后点击登录按钮,action接受用户名和密码,根据用户名查询密码,将用户输入的密码进行MD5加密,然后在和数据库里面的值进行对比,如果成立就生成一个token的变量。token的值由uuid生成。在将用户信息存到redis里面。Key是token,value就是用户信息,在设置redis的过去时间,一般半个小时,再把token写入到cookie中。客户端发送请求的时候,从cookie里面拿到token的值,把值拿到之后再redis里面当成k来取出用户信息看是都存在,存在登录成功。