安装Hadoop方法集群步骤
在Linux安装hadoop。。。。。 。
我解压的hadoop2.7.3(更名为hadoop)文件路径是在 /home/Mcwang/soft/hadoop
我们要修改的配置文件是在:/home/Mcwang /hadoop/etc/hadoop下的文件
上传并解压缩
上传到/home/Mcwang/soft
tar -zvxf hadoop-2.7.3tar.gz
mv hadoop-2.7.3 hadoop >>将解压的文件更名为hadoop
ln -s hadoop hadoop.soft //建立解压文件的软链接
rm hadoop-2.7.3.tar.gz //可以删除这个压缩包
su root
vi /etc/profile //需要在root用户下配置文件
配置如下:
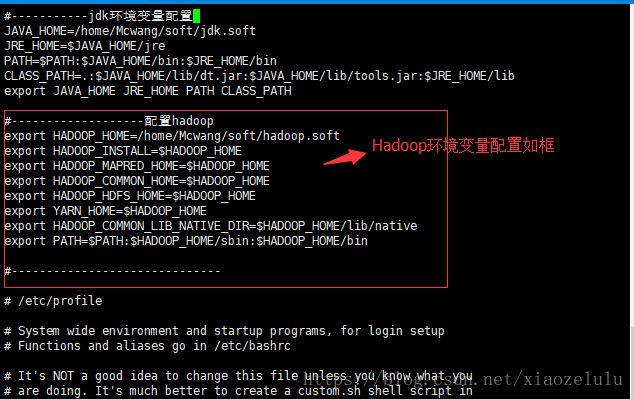
然后执行:source /etc/profile //使之生效,

进行测试一下: hdfs / hadoop 之一
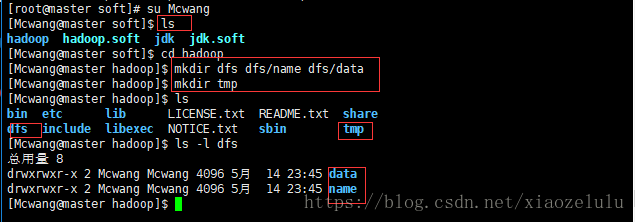
cd hadoop //hadoop下新建三个文件夹
mkdir dfs dfs/name dfs/data
mkdur tmp
接下来修改配置文件:七个 (第七个文件我们需要copy一个文件 并且修改)
我们要修改的配置文件是在:/soft /hadoop/etc/hadoop下的文件
注意:上传文件的时候,一定要在普通用户下(如Mcwang)上传,否则修改文件的时候要求在root用户下
修改,以后操作起来也是不方便,所以最好不要在root下安装程序。(安装软件的命令有些只能root使用)
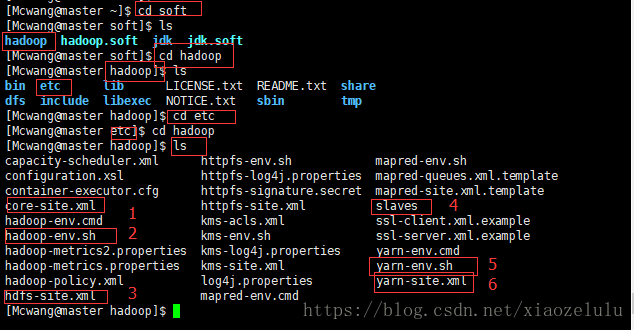
修改是在[Mcwang@master hadoop]下执行:
前提:上传Hadoop的时候一定要在普通用户Mcwang下上传,不然修改这七个文件需要root权限!
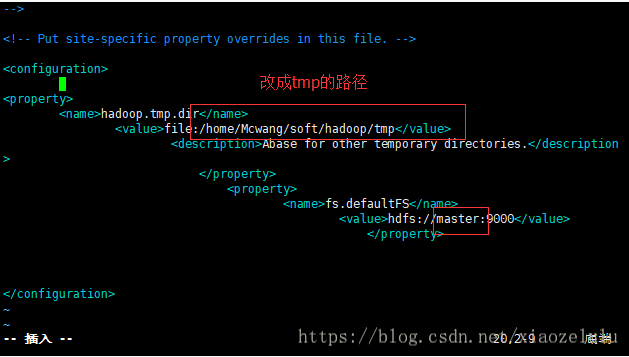
1.修改vi core-site.xml --tmp路径,master
2.修改hadoop-env.sh --安装jdk的路径
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/home/Mcwang/soft/jdk.soft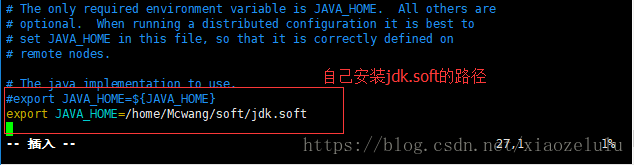
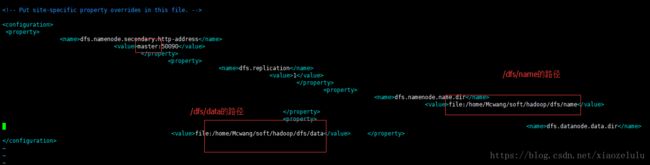
3.修改hdfs-site.xml --master, /dfs/name和/dfs/data路径
4.修改mapred-site.xml --先复制,master(2个)

改一下master
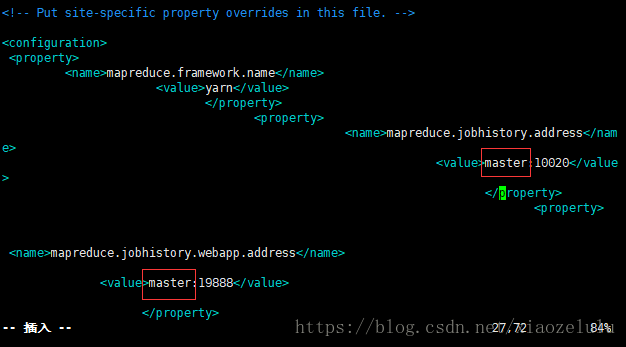
5.修改vi yarn-site.xml --只需要修改Master-master 1
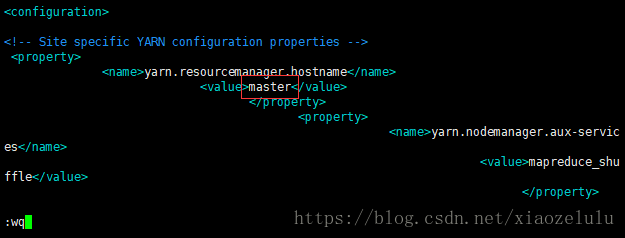
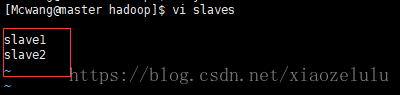
6.修改 vi slaves --先删除,后添加slave1,slave2

7.修改 vi yarn-env.sh --jdk.soft的路径
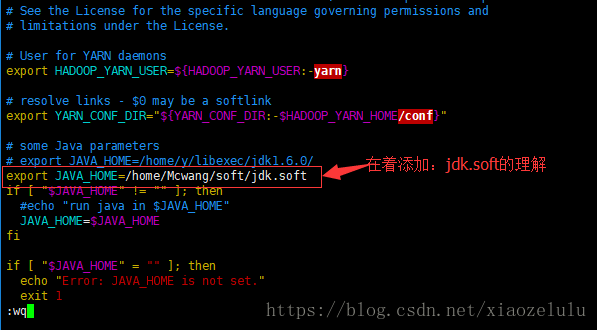
添加:export JAVA_HOME=/home/Mcwang/soft/jdk.soft
启动hadoop
因为master是namenode,slave1和slave2都是datanode,所以只需对master进行初始化,也就是
对hdfs进行初始化
1 .打包文件夹 /soft/hadoop ,复制到 datanode 节点机(指的是slave1,slave2),保证节点机环境配置
与master保持一致格式化文件系统.(将hadoop.tar.gz打包scp到其他机器)
在最下面会出现:格式化成功,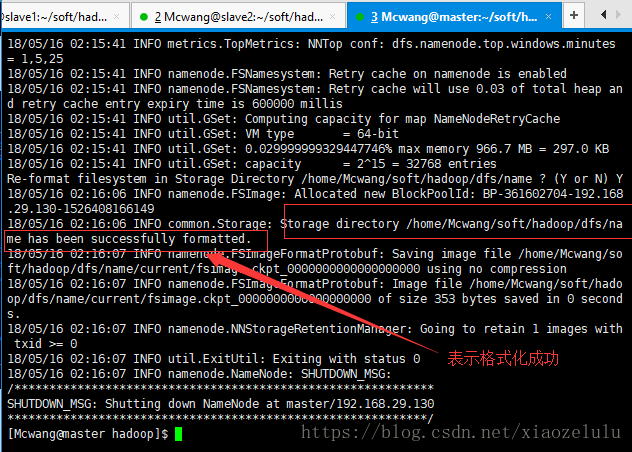
2.启动文件服务 -全部
start-all.sh //无论哪个文件下
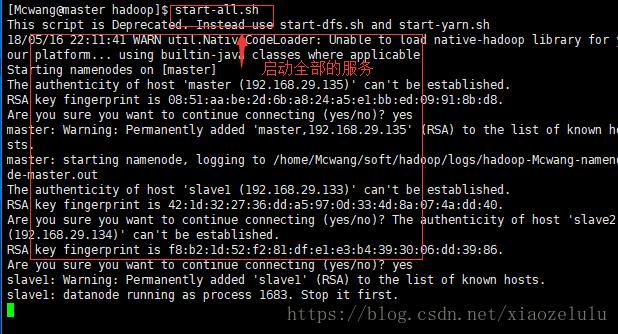
slave1:
satrt-all.sh 需要输入多次密码 由于没有免密,所以需要多次输入密码
slave2:
start-all.sh
3分别在各个主机上执行 jps 查看服务情况



4.如果要在Windows下的浏览器上访问hadoop
需要进行以下更改:
修改文件:C:/Windows/System32/drivers/etc/hosts
在文件中添加键值对:
192.168.29.136 master
192.168.29.137 slave1
192.138.29.138 slave2
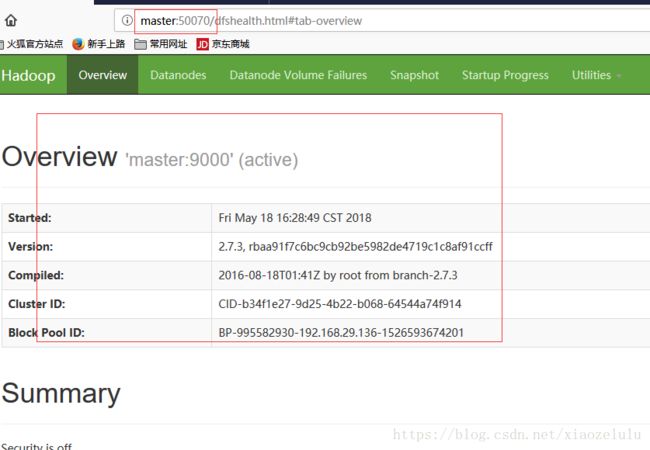
http://master:50070