Redis源码阅读【8-命令处理生命周期-4】
Redis源码阅读【1-简单动态字符串】
Redis源码阅读【2-跳跃表】
Redis源码阅读【3-Redis编译与GDB调试】
Redis源码阅读【4-压缩列表】
Redis源码阅读【5-字典】
Redis源码阅读【6-整数集合】
Redis源码阅读【7-quicklist】
Redis源码阅读【8-命令处理生命周期-1】
Redis源码阅读【8-命令处理生命周期-2】
Redis源码阅读【8-命令处理生命周期-3】
Redis源码阅读【8-命令处理生命周期-4】
Redis源码阅读【番外篇-Redis的多线程】
Redis源码阅读【9-持久化】
建议搭配源码阅读:源码地址
文章目录
- 1、介绍
- 2、命令获取解析与执行
-
- 2.1、命令解析
- 2.2、命令调用
- 2.3、返回结果
- 3、总结
1、介绍
在前面的几篇《命令处理生命周期》的文章中我们分别介绍了:生命周期有关的结构体,Redis相关的事件 ,以及 服务端启动的过程 ,那么这篇文章我们主要讲解命令的处理过程。在Redis中,服务端启动完成后就是等待客户端的连接,并处理来自客户端的命令,最终响应客户端,整个过程涉及多个方面,我们主要从以下几个方面入手:命令解析,命令调用,返回结果。
2、命令获取解析与执行
TCP是一个基于字节流的通信协议,因此会产生半包和粘包的情况,如下图所示:
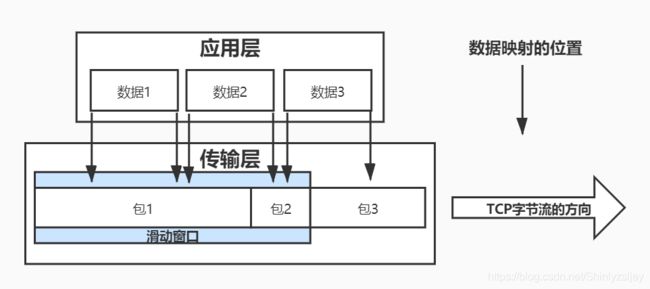
客户端会发送三个数据:数据1,数据2,数据3,但是在TCP传输层真正发送数据的时候,可能会出现一个应用层数据横跨多个包的情况,因此服务端接收到的数据可能就不是一个完整数据包的情况。
为了区分一个完整的数据包,通常有以下三个方法:1、固定长度的数据包,2、特定的字符分隔符号,3、在数据包头部设置数据长度 来区分数据包大小。
Redis则是使用特定的协议来区分数据大小,这个协议称之为RESP协议(其实我个人感觉是为了简化开发,使用字符替代协议编解码以及黏包等工作量,毕竟C开发可拓展的网络指令并不是那么灵活),比如当客户端输入如下命令的时候:
SET key value
客户端会将该协议转换为以下的格式,然后发送给服务器:
*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n
- "
$" 字节,后跟组成字符串的字节数(带前缀的长度),由CRLF终止 - 协议的不同部分始终以"
\ r \ n"(CRLF)结尾 - 对于简单字符串,回复的第一个字节为"
+" - 对于错误,回复的第一个字节为"
-" - 对于整数,答复的第一个字节为"
:" - 对于散装字符串,回复的第一个字节为"
$" - 对于数组,回复的第一个字节为"
*" *3在头部代表这个命令有三个参数,分别为set,key,value
需要注意的是,Redis是可以使用telent会话的方式使用的,只是此时没有了请求协议中的*来声明参数的数量,因此必须使用空格来分隔各个参数,服务器在接收到数据之后,会将空格作为参数分隔符解析命令请求,可以看出 RESP协议中是没有空格存在 的,这个特点会在解析命令的时候使用上。
Redis服务器接收到的命令请求首先存储在客户端 client 对象的querybuf输入缓冲区中,然后解析命令请求各个参数,并存储在客户端对象的argv(参数对象数组)和argc(参数数量)字段中。从上一篇文章我们知道,处理客户端请求的函数是readQueryFromClient,其会读取socket数据并存储到客户端对象的输入缓冲区querybuf中,并调用processInputBufferAndReplicate函数中的processInputBuffer去处理。processInputBuffer函数逻辑如下图所示:

实际内部流程图:

时序图:
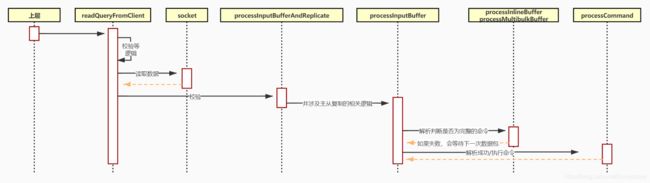
结合前面的图片会发现,命令解析并不是一次性完成的,由于存在拆包和粘包的情况,收到的数据可能并不是一个完整的,那么在readQueryFromClient方法读取完socket中的数据命令可能由于拆包导致不完整,那么在调用processInlineBuffer或者processMultibulkBuffer解析命令就会失败,如果发现是数据缺失但是命令格式正确的情况下,当前的内容会占时存储在 clinet 的querybuf中等待下次数据包到来再继续解析,还记得我们前面在介绍client队列里面的成员属性的时候有一个属性qb_pos它是用来记录当前命令解析到哪个位置的标记便于下次再去读querybuf的时候进行数组的快速定位。外部整体代码实现如下(networking.c):
//processInputBuffer处理socket输入的数据解析成命令并且执行
void processInputBuffer(client *c) {
//当缓冲区仍然有东西的时候,需要继续处理
while (c->qb_pos < sdslen(c->querybuf)) {
............................一堆校验........................
if (c->reqtype == PROTO_REQ_INLINE) {
//telent的内联和客户端
if (processInlineBuffer(c) != C_OK) break;
//如果是Gopher模式,只会有0/1个参数
if (server.gopher_enabled &&
((c->argc == 1 && ((char *) (c->argv[0]->ptr))[0] == '/') ||
c->argc == 0)) {
processGopherRequest(c);
resetClient(c);
c->flags |= CLIENT_CLOSE_AFTER_REPLY;
break;
}
} else if (c->reqtype == PROTO_REQ_MULTIBULK) {
//普通正常客户端,如果解析不成功退出循环,等待下次继续解析
if (processMultibulkBuffer(c) != C_OK) break;
} else {
serverPanic("Unknown request type");
}
/* Multibulk processing could see a <= 0 length. */
if (c->argc == 0) {
//如果解析出来的参数为0,释放client
resetClient(c);
} else {
//标记client为需要等待处理命令的状态,证明本次解析不完整,等待下次数据包到来再继续解析
if (c->flags & CLIENT_PENDING_READ) {
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
//解析完成成并执行命令
if (processCommandAndResetClient(c) == C_ERR) {
//执行失败,无需再继续外层的while循环,直接退出,快速失败机制
return;
}
}
}
//修建qb_pos标记位置
if (c->qb_pos) {
sdsrange(c->querybuf, c->qb_pos, -1);
c->qb_pos = 0;
}
}
2.1、命令解析
我们刚刚看了,命令解析的整体流程以及外部调用方法processInputBuffer的整体实现,下面来详细讲解以下命令解析的整体流程,命令解析本质上可以分为以下两个步骤:
1、解析命令请求参数的数目;
2、循环解析每个请求参数
⭐解析命令请求参数数目
我们这里以processMultibulkBuffer方法为例(普通命令解析),querybuf指向命令请求首地址,假设命令请求参数数目的协议格式为*3\r\n,即首字符必须是*,并且可以使用字符\r定位到行尾位置。解析后的参数数目暂存在客户端对象的multibulklen字段,表示等待解析的参数数目,变量pos记录已解析命令请求的长度,代码如下所示:
if (c->multibulklen == 0) {
........................校验...............................
//定位到行尾
newline = strchr(c->querybuf + c->qb_pos, '\r');
if (newline == NULL) {
//缓冲区存储的数据太大
if (sdslen(c->querybuf) - c->qb_pos > PROTO_INLINE_MAX_SIZE) {
addReplyError(c, "Protocol error: too big mbulk count string");
setProtocolError("too big mbulk count string", c);
}
return C_ERR;
}
// Buffer 应该要包含 \n
if (newline - (c->querybuf + c->qb_pos) > (ssize_t) (sdslen(c->querybuf) - c->qb_pos - 2))
return C_ERR;
//解析命令请求参数数目,并存储在客户端对象multibulklen字段
//注意这里的 c->qb_pos 会是 0 ,因为上面在方法执行结束的时候有一个裁剪 qb_pos的操作,会设置成0
serverAssertWithInfo(c, NULL, c->querybuf[c->qb_pos] == '*');
ok = string2ll(c->querybuf + 1 + c->qb_pos, newline - (c->querybuf + 1 + c->qb_pos), &ll);
//非法长度
if (!ok || ll > 1024 * 1024) {
addReplyError(c, "Protocol error: invalid multibulk length");
setProtocolError("invalid mbulk count", c);
return C_ERR;
}
//记录解析到的位置
c->qb_pos = (newline - c->querybuf) + 2;
if (ll <= 0) return C_OK;
//解析出来的参数个数
c->multibulklen = ll;
/* 先清空空间 */
if (c->argv) zfree(c->argv);
//分配参数存储空间
c->argv = zmalloc(sizeof(robj *) * c->multibulklen);
}
⭐循环解析每个请求参数
假设命令请求各参数的协议格式为:$3\r\nSET\r\n,即首字符必须是$。解析当前参数之前需要解出参数的字符串长度,可以使用字符\r定位到行尾位置;注意,解析参数长度时,字符串开始位置为querybuf+pos+1;字符串参数长度暂存在客户端对象的bulklen字段,同时更新已解析字符串qp_pos,代码如下:
//循环解析每个请求参数
while (c->multibulklen) {
//如果没有长度,先读取该参数的长度
if (c->bulklen == -1) {
//定位到行尾
newline = strchr(c->querybuf + c->qb_pos, '\r');
if (newline == NULL) {
//缓冲区数据过大
if (sdslen(c->querybuf) - c->qb_pos > PROTO_INLINE_MAX_SIZE) {
addReplyError(c,
"Protocol error: too big bulk count string");
setProtocolError("too big bulk count string", c);
return C_ERR;
}
break;
}
//Buffer 需要包含 \n字符
if (newline - (c->querybuf + c->qb_pos) > (ssize_t) (sdslen(c->querybuf) - c->qb_pos - 2))
break;
//解析当前参数字符串长度,字符串首字符偏移量为qb_pos
if (c->querybuf[c->qb_pos] != '$') {
addReplyErrorFormat(c,
"Protocol error: expected '$', got '%c'",
c->querybuf[c->qb_pos]);
setProtocolError("expected $ but got something else", c);
return C_ERR;
}
ok = string2ll(c->querybuf + c->qb_pos + 1, newline - (c->querybuf + c->qb_pos + 1), &ll);
if (!ok || ll < 0 || ll > server.proto_max_bulk_len) {
addReplyError(c, "Protocol error: invalid bulk length");
setProtocolError("invalid bulk length", c);
return C_ERR;
}
c->qb_pos = newline - c->querybuf + 2;
if (ll >= PROTO_MBULK_BIG_ARG) {
if (sdslen(c->querybuf) - c->qb_pos <= (size_t) ll + 2) {
sdsrange(c->querybuf, c->qb_pos, -1);
c->qb_pos = 0;
//sds扩容
c->querybuf = sdsMakeRoomFor(c->querybuf, ll + 2);
}
}
//解析出字符串长度
c->bulklen = ll;
}
//读取参数
if (sdslen(c->querybuf) - c->qb_pos < (size_t) (c->bulklen + 2)) {
//数据不足够,没有到\r\n 可能被拆包了
break;
} else {
//querybuf 可以直接赋给argv 这个相当于之前的sds的复用,清空sds,并且填入新数据,避免sds的内存空间频繁分配和释放
if (c->qb_pos == 0 &&
c->bulklen >= PROTO_MBULK_BIG_ARG &&
sdslen(c->querybuf) == (size_t) (c->bulklen + 2)) {
c->argv[c->argc++] = createObject(OBJ_STRING, c->querybuf);
sdsIncrLen(c->querybuf, -2); /* remove CRLF */
c->querybuf = sdsnewlen(SDS_NOINIT, c->bulklen + 2);
//清空sds
sdsclear(c->querybuf);
} else {
//解析参数,创建新的sds
c->argv[c->argc++] =
createStringObject(c->querybuf + c->qb_pos, c->bulklen);
c->qb_pos += c->bulklen + 2;
}
c->bulklen = -1;
//待解析参数数目减1
c->multibulklen--;
}
}
当multibulklen值更新为0时,说明参数解析完成,结束循环。此外待解析参数需要存储在 client 里面,而不放在函数的局部变量中,因为 TCP 存在半包的情况,函数局部变量在退出函数后会丢失,此时需要放在 client 里面,并需要记录该命令请求待解析的参数数目,以及待解析参数的长度;而剩余解析的参数会继续存储在客户端的输入缓冲区中。
2.2、命令调用
解析命令请求之后,就是执行命令的时候,此时会调用processCommand处理该命令请求,而处理命令请求之前还有很多校验逻辑,比如客户端是否已经完成认证,命令请求参数是否合法。下面简要列出若干校验规则:
- ⭐1、如果是quit命令直接返回并且关闭客户端
if (!strcasecmp(c->argv[0]->ptr,"quit")) {
addReply(c,shared.ok);
c->flags |= CLIENT_CLOSE_AFTER_REPLY;
return C_ERR;
}
- ⭐2、执行函数
lookupCommand查找命令之后,如果命令不存在或者参数错误返回错误
注意:命令结构体的arity用于检验数目是否合法,当arity小于0时,表示命令参数数目大于等于arity的绝对值;当arity大于0时,表示命令参数数目必须为arity。
//查找命令
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
if (!c->cmd) {
//如果找不到返回错误
flagTransaction(c);
sds args = sdsempty();
int i;
for (i = 1; i < c->argc && sdslen(args) < 128; i++)
args = sdscatprintf(args, "`%.*s`, ", 128 - (int) sdslen(args), (char *) c->argv[i]->ptr);
addReplyErrorFormat(c, "unknown command `%s`, with args beginning with: %s",
(char *) c->argv[0]->ptr, args);
sdsfree(args);
return C_OK;
} else if ((c->cmd->arity > 0 && c->cmd->arity != c->argc) ||
(c->argc < -c->cmd->arity)) {
//参数数量错误也返回错误
flagTransaction(c);
addReplyErrorFormat(c, "wrong number of arguments for '%s' command",
c->cmd->name);
return C_OK;
}
- ⭐3、如果配置文件中使用指令
requirepass password设置密码,且客户端未认证通过,只能执行auth命令和hello命令,命令格式为AUTH password
int auth_required = (!(DefaultUser->flags & USER_FLAG_NOPASS) ||
DefaultUser->flags & USER_FLAG_DISABLED) &&
!c->authenticated;
if (auth_required) {
//需要认证的情况下只能使用 auth 和 hello
if (c->cmd->proc != authCommand && c->cmd->proc != helloCommand) {
flagTransaction(c);
addReply(c,shared.noautherr);
return C_OK;
}
}
- ⭐4、如果配置文件中使用指令
maxmemory设置了最大内存限制,且当前内存使用量超过了该配置的门限,服务器会拒绝执行带有m标识的指令 (CMD_DENYOOM),如SET命令,APPEND命令和LPUSH命令等。
//拒绝执行带有m标识的命令,到内存到达上限的时候的内存保护机制
if (server.maxmemory && !server.lua_timedout) {
//先调用freeMemoryIfNeededAndSafe进行一次内存释放
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
//释放内存可能会清空主从同步slave的缓冲区,这可能会导致释放一个活跃的slave客户端
if (server.current_client == NULL) return C_ERR;
//当内存释放也不能解决内存问题的时候,客户端试图执行命令在OOM的情况下被拒绝
// 或者客户端处于MULTI/EXEC的上下文中
if (out_of_memory &&
(c->cmd->flags & CMD_DENYOOM ||
(c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand &&
c->cmd->proc != discardCommand)))
{
flagTransaction(c);
//回复的内容OOM
addReply(c, shared.oomerr);
return C_OK;
}
}
- ⭐5、除了上面的5种校验,还有很多其它的校验,例如集群相关的校验,持久化校验,主从复制校验,发布订阅校验以及事务操作等等,所有的逻辑都在
processCommand这个函数里面大家可以自行查阅。
当所有校验通过后才会开始进行真正的命令执行环节,首先会判断当前的命令是否是在事务中,如果是会添加到commands队列里面,按照事务的方式执行,否则直接执行,此外exec multi watch discard这些命令也是直接执行不用添加到队列,代码如下:
//执行命令,前面已经把找到的命令放到了client 的cmd里面了
//如果当前开启事务,命令会被添加到commands队列中去
//这里也发现 exec multi watch discard的命令是不用进入队列的,因为需要直接执行
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand)
{
//将命令添加到待执行队列种,证明Redis会使用事务的方式执行指令
queueMultiCommand(c);
addReply(c,shared.queued);
} else {
//不进入队列的直接执行
call(c,CMD_CALL_FULL);
c->woff = server.master_repl_offset;
if (listLength(server.ready_keys))
handleClientsBlockedOnKeys();
}
return C_OK;
这里注意,最终执行命令是在call中调用的,在call中会执行命令,并且计时,如果指令执行时间过长,会作为慢查询记录到日志中去。执行完成后如果有必要还需要更新统计信息,记录慢查询日志,AOF持久化该命令请求,传播命令请求给所有的从服务器等。基本代码如下所示(call方法):
//计时
start = server.ustime;
//执行命令
c->cmd->proc(c);
duration = ustime()-start;
dirty = server.dirty-dirty;
if (dirty < 0) dirty = 0;
.........................................
if (flags & CMD_CALL_SLOWLOG && !(c->cmd->flags & CMD_SKIP_SLOWLOG)) {
char *latency_event = (c->cmd->flags & CMD_FAST) ?
"fast-command" : "command";
//AOF持久化相关
latencyAddSampleIfNeeded(latency_event,duration/1000);
//记录慢查询日志
slowlogPushEntryIfNeeded(c,c->argv,c->argc,duration);
}
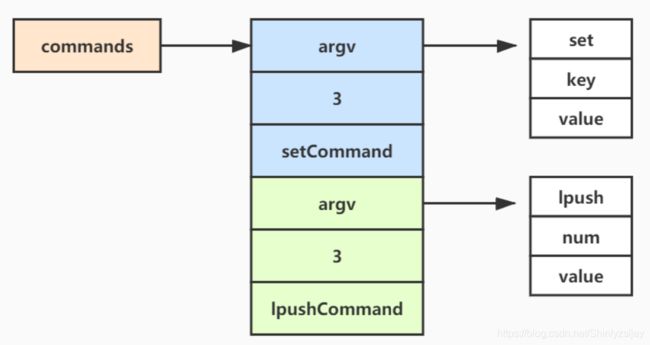
此外还有一个问题,命令的参数和个数是存储在client的,当下次命令到来的时候会被覆盖,那么在事务执行的情况下,每条指令的相关内容是保存在哪的呢?其实Redis提供了两个结构体去处理这个问题,在queueMultiCommand中的命令是被添加到commands中去的commands本身是在结构体multiState下面commands自身的结构体是multiCmd,其定义如下:
typedef struct multiState {
multiCmd *commands; //需要执行的命令
int count; //命令的数量
int cmd_flags;
int minreplicas;
time_t minreplicas_timeout;
} multiState;
typedef struct multiCmd {
robj **argv; //参数对象
int argc; //参数个数
struct redisCommand *cmd; //对应的指令
} multiCmd;
事务模式,命令执行队列其真实结构如下图所示:
2.3、返回结果
Redis服务器返回结果类型不同,协议格式不同,而客户端可以根据返回结果的第一个字符判断返回类型。Redis返回结果可以分为5类。
- ⭐1、状态回复,第一个字符是
+;例如SET命令执行完成会向客户端回复+OK\r\n
addReply(c, ok_reply ? ok_reply : shared.ok);
变量ok_reply 通常为NULL,则返回的是共享变量shared.ok,在服务器启动时就完成共享变量的初始化。
- ⭐2、错误回复,第一个字符是
-。例如,当客户端请求命令不存在时,会向客户端返回-ERR unknown command 'testcmd'
addReplyErrorFormat(c,"unknown command `%s`, with args beginning with: %s",
(char*)c->argv[0]->ptr, args);
而函数addReplyErrorFormat内部实现会拼装错误回复字符串:
void addReplyErrorFormat(client *c, const char *fmt, ...) {
.................................
//拼装字符串
addReplyErrorLength(c, s, sdslen(s));
sdsfree(s);
}
void addReplyErrorLength(client *c, const char *s, size_t len) {
//开头就是 -ERR
if (!len || s[0] != '-') addReplyProto(c, "-ERR ", 5);
addReplyProto(c, s, len);
addReplyProto(c, "\r\n", 2);
if (c->flags & (CLIENT_MASTER | CLIENT_SLAVE) && !(c->flags & CLIENT_MONITOR)) {
char *to = c->flags & CLIENT_MASTER ? "master" : "replica";
char *from = c->flags & CLIENT_MASTER ? "replica" : "master";
char *cmdname = c->lastcmd ? c->lastcmd->name : "" ;
serverLog(LL_WARNING, "== CRITICAL == This %s is sending an error "
"to its %s: '%s' after processing the command "
"'%s'", from, to, s, cmdname);
}
}
- ⭐3、整数回复,第一个字符是
:。例如,INCR命令执行完毕向客户端返回:100\r\n。
//这个就是冒号:
addReply(c,shared.colon);
addReply(c,new);
addReply(c,shared.crlf);
- ⭐4、回复字符串,第一个字符是
$。例如,GET命令查找键向客户端返回结果$5\r\nhello\r\n
void addReplyBulk(client *c, robj *obj) {
//计算长度放在头部,使用$标记
addReplyBulkLen(c, obj);
//回复的内容
addReply(c, obj);
addReply(c, shared.crlf);
}
- ⭐5、多条字符串回复,第一个字符是
*。例如,LRANGE命令可能会返回多个值,格式为*3\r\n$6\r\nnvalueA\r\n$6\r\nvalueB\r\n$6\r\nvalueC\r\n,与命令请求协议格式相同,*3表示返回值数目,$6表示当前返回值字符串长度,基本格式如下*[返回数目]\r\n$[字符长度]......\r\n:
//计算需要返回对象数量*开头
addReplyArrayLen(c,rangelen);
if (o->encoding == OBJ_ENCODING_QUICKLIST) {
listTypeIterator *iter = listTypeInitIterator(o, start, LIST_TAIL);
//循环添加第一个是$
while(rangelen--) {
listTypeEntry entry;
listTypeNext(iter, &entry);
quicklistEntry *qe = &entry.entry;
if (qe->value) {
addReplyBulkCBuffer(c,qe->value,qe->sz);
} else {
addReplyBulkLongLong(c,qe->longval);
}
}
listTypeReleaseIterator(iter);
} else {
serverPanic("List encoding is not QUICKLIST!");
}
这里可以看到5种类型的回复都使用了addReply,在addReply中回复的数据会被暂存在client的reply和buf字段中,分别表示输出链表与输出缓冲区。那么什么时候会发送数据给client呢?下一篇文章会介绍Redis的多线程IO。
3、总结
Redis为了保证命令的执行的顺序性,在服务端维护了client对象,其中里面存储了各种客户端的状态以及当前执行命令的情况,此外client还充当缓冲区的作用,从而能一定程度的提高Redis的吞吐量,由于Redis的命令执行是基于单线程的,所以基本上没有发现作者有使用锁的情况,都是流水线式的指令执行,整体流程我通过下图展示出来:
本章实际执行程图:

时序图:
Redis为例简化通信开发难度,使用了RESP协议的方式与客户端进行通信,通过RESP的解析可以很好的处理TCP的半包问题 (这块是个人见解)。其实我们也发现RESP的本质其实就是解析字符串通过关键标记表示参数和对应的长度数量,由于Redis的作者希望Redis能足够轻量,所以放弃使用了一些C的TCP内库,基本上TCP通信这块都是自行实现的通过调用Linux的内核接口实现 ,通过这种方式实现的Redis本身有很好的拓展性,也方便开发者后续进一步拓展Redis支持的指令集合,让其支持更多的功能。此外在这里我们也发现Redis的一些多线程的影子,从Redis6开始,Redis是开始支持多线程,下一篇文章我们也会对Redis的多线程做进一步的了解。