Redis源码阅读【9-持久化】
Redis源码阅读【1-简单动态字符串】
Redis源码阅读【2-跳跃表】
Redis源码阅读【3-Redis编译与GDB调试】
Redis源码阅读【4-压缩列表】
Redis源码阅读【5-字典】
Redis源码阅读【6-整数集合】
Redis源码阅读【7-quicklist】
Redis源码阅读【8-命令处理生命周期-1】
Redis源码阅读【8-命令处理生命周期-2】
Redis源码阅读【8-命令处理生命周期-3】
Redis源码阅读【8-命令处理生命周期-4】
Redis源码阅读【番外篇-Redis的多线程】
Redis源码阅读【9-持久化】
建议搭配源码阅读:源码地址
文章目录
- 1、前言
- 2、RDB
-
- 2.1、RDB的执行流程
- 2.2、RDB的执行源码
- 2.3、RDB文件写入&触发条件
- 2.4、RDB文件格式
-
- 2.4.1、opcodes
- 2.4.2、RDB文件内容
- 3、AOF
-
- 3.1、AOF的执行流程
-
- 3.1.1、写入AOF缓冲区
- 3.1.2、AOF文件写入
- 3.1.3、AOF重写
- 4、混合持久化
1、前言
Redis是一个内存数据库,当机器重启的时候内存中的数据都会丢失。所以将内存中的数据持久化下来是很有必要的。对于Redis的持久化目前有两种模式:RDB模式和AOF模式。RBD模式是在 指 定 时 间 间 隔 \color{red}{指定时间间隔} 指定时间间隔将内存中的数据通过快照的方式保存在一个名为dump.rdb的文件中来实现持久化的,而AOF模式是通过 指 接 收 每 一 次 \color{red}{指接收每一次} 指接收每一次的写命令,并将其记录在文件中来实现持久化的,两种模式的持久化各有优劣势,下面我们就来具体看一下二者的区别以及实现吧。
2、RDB
RDB是以一种快照的方式去保存当前内存中的数据并持久化在磁盘上,由于是快照形式RDB并不能记录数据的每一次变化的过程(类似能记录过程的有Mysql的Binlog),作为当前数据最新的快照,RDB能够最大限度的节省磁盘空间而不需要记录下每一次的数据变化,当服务器遇到意外断电的时候RDB总能以比AOF更快的数据恢复数据到内存中去,但是由于是通过 指 定 时 间 间 隔 \color{red}{指定时间间隔} 指定时间间隔的方式持久化,在并发度高的情景下,RDB会发生数据丢失的情况
2.1、RDB的执行流程
RDB的触发有两种方式,一种是直接使用bgsave/save命令显示触发RDB(bgsave异步保存/save同步阻塞保存),另一种则是通过配置:save 60 1000的方式触发。配置的意思是如果60秒内有1000个key发生变化就会显示的触发一次RDB快照。
其主要流程如下图所示:

注:当程序调用操作系统的fork()的时候,会创建一个子进程,主进程的fork()返回子进程的PID,子进程返回0,如果是负数代码fork失败

时序图:

从上面的流程图和时序图大致可以看明白RBD的执行方式和函数间的调用关系,对于bgsave(后台保存)其实有两种方式:主动命令触发 和 定时任务触发,主动命令触发就说图中展示的那样,定时任务触发是直接调用rdbSaveBackground来执行的,时序如下所示:

时序图可能部分画的有点问题:大家主要关注调用流程和顺序就好了
由上面的图看出,bgsave的最主要的方法就是rdbSaveBackground,而rdbSave是最终执行RDB的方法,无论是bgsave(后台执行)还是save(同步执行),最终都是执行rdbSave的,定时任务触发的bgsave,本质上还是走前面说的aeEventLoop的方式触发。
2.2、RDB的执行源码
代码实现如下:
/**
* 命令触发bgsave的入口
* @param c
*/
void bgsaveCommand(client *c) {
int schedule = 0;
/* The SCHEDULE option changes the behavior of BGSAVE when an AOF rewrite
* is in progress. Instead of returning an error a BGSAVE gets scheduled. */
//当AOF重写的时候,RDB会被设置成schedule延后执行
if (c->argc > 1) {
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr, "schedule")) {
schedule = 1;
} else {
addReply(c, shared.syntaxerr);
return;
}
}
rdbSaveInfo rsi, *rsiptr;
//获取执行RDB需要的信息
rsiptr = rdbPopulateSaveInfo(&rsi);
//先检验RDB是否存在子进程
if (server.rdb_child_pid != -1) {
addReplyError(c, "Background save already in progress");
//检验当前是否有RDB正在执行/AOF重写正在执行
} else if (hasActiveChildProcess()) {
//设置RDB为schedule模式
if (schedule) {
server.rdb_bgsave_scheduled = 1;
addReplyStatus(c, "Background saving scheduled");
} else {
addReplyError(c,
"Another child process is active (AOF?): can't BGSAVE right now. "
"Use BGSAVE SCHEDULE in order to schedule a BGSAVE whenever "
"possible.");
}
//执行rdbSaveBackground 准备Fork子进程进行RDB
} else if (rdbSaveBackground(server.rdb_filename, rsiptr) == C_OK) {
addReplyStatus(c, "Background saving started");
} else {
addReply(c, shared.err);
}
}
/**
* Fork一个子进程去执行RDB
* @param filename
* @param rsi
* @return
*/
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
//再次判断校验是否有子进程正在执行RDB/AOF重写
if (hasActiveChildProcess()) return C_ERR;
//设置一些信息比如执行时间,记录本次key变化数量到lastbgsave_try
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
openChildInfoPipe();
//Fork一个子进程(并判断返回 如果是0是子进程,如果大于0是父进程)
if ((childpid = redisFork()) == 0) {
int retval;
/* Child */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
//执行RDB
retval = rdbSave(filename, rsi);
if (retval == C_OK) {
sendChildCOWInfo(CHILD_INFO_TYPE_RDB, "RDB");
}
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent */
//如果返回的childpid为-1证明Fork进程失败
if (childpid == -1) {
closeChildInfoPipe();
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING, "Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
//再次记录一些信息
serverLog(LL_NOTICE, "Background saving started by pid %d", childpid);
server.rdb_save_time_start = time(NULL);
server.rdb_child_pid = childpid;
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
//父进程直接返回
return C_OK;
}
return C_OK; /* unreached */
}
/**
* 判断是否有进程执行RDB/AOF重写/模块加载
* @return
*/
int hasActiveChildProcess() {
return server.rdb_child_pid != -1 ||
server.aof_child_pid != -1 ||
server.module_child_pid != -1;
}
/**
* Redis用来Fork子进程的函数
* @return
*/
int redisFork() {
int childpid;
long long start = ustime();
//调用操作系统的Fork 如果是子进程 返回0 如果是父进程 返回进程ID
if ((childpid = fork()) == 0) {
/* Child */
closeListeningSockets(0);
setupChildSignalHandlers();
} else {
/* Parent */
//父亲计算RDB写入速度
server.stat_fork_time = ustime()-start;
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
return -1;
}
updateDictResizePolicy();
}
return childpid;
}
/**
* 执行RDB
* @param filename
* @param rsi 执行RDB需要的信息
* @return
*/
int rdbSave(char *filename, rdbSaveInfo *rsi) {
//通过临时文件的方式写入
char tmpfile[256];
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
FILE *fp;
rio rdb;
int error = 0;
snprintf(tmpfile, 256, "temp-%d.rdb", (int) getpid());
fp = fopen(tmpfile, "w");
if (!fp) {
char *cwdp = getcwd(cwd, MAXPATHLEN);
serverLog(LL_WARNING,
"Failed opening the RDB file %s (in server root dir %s) "
"for saving: %s",
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
return C_ERR;
}
rioInitWithFile(&rdb, fp);
startSaving(RDBFLAGS_NONE);
if (server.rdb_save_incremental_fsync)
rioSetAutoSync(&rdb, REDIS_AUTOSYNC_BYTES);
if (rdbSaveRio(&rdb, &error, RDBFLAGS_NONE, rsi) == C_ERR) {
errno = error;
goto werr;
}
/* Make sure data will not remain on the OS's output buffers */
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
//重命名文件来确保文件修改是原子的
if (rename(tmpfile, filename) == -1) {
char *cwdp = getcwd(cwd, MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
serverLog(LL_NOTICE, "DB saved on disk");
//记录下一些信息
server.dirty = 0;
server.lastsave = time(NULL);
server.lastbgsave_status = C_OK;
stopSaving(1);
return C_OK;
werr:
serverLog(LL_WARNING, "Write error saving DB on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
2.3、RDB文件写入&触发条件
整体代码如上所示,整个逻辑还是比较容易理解的,此外这里有一个细节要注意就是写入RDB文件的方式,Redis是通过写入一个临时文件再重命名的方式写入的,这样可以保证RDB写入操作的事务性。

关于前面我们提到,配置save 60 1000如果60秒内有1000个key发生变化就会显示的触发一次RDB,那么这里理解起来有点拗口,这里我直接贴出代码:
/* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
//sp -> changes 代表发生变化key的数量 sp->seconds 是间隔时间
if (server.dirty >= sp->changes &&
//server.unixtime - server.lastsave 是距离上次执行完的时间差
server.unixtime - server.lastsave > sp->seconds &&
(server.unixtime - server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK)) {
serverLog(LL_NOTICE, "%d changes in %d seconds. Saving...",
sp->changes, (int) sp->seconds);
rdbSaveInfo rsi, *rsiptr;
//获取执行RDB需要的信息
rsiptr = rdbPopulateSaveInfo(&rsi);
//触发执行RDB
rdbSaveBackground(server.rdb_filename, rsiptr);
break;
}
save 60 1000 其实真正的意思是,两次执行RDB的时间间隔大于60,并且同时发生了1000个key以上的变化就会进行一次RDB
2.4、RDB文件格式
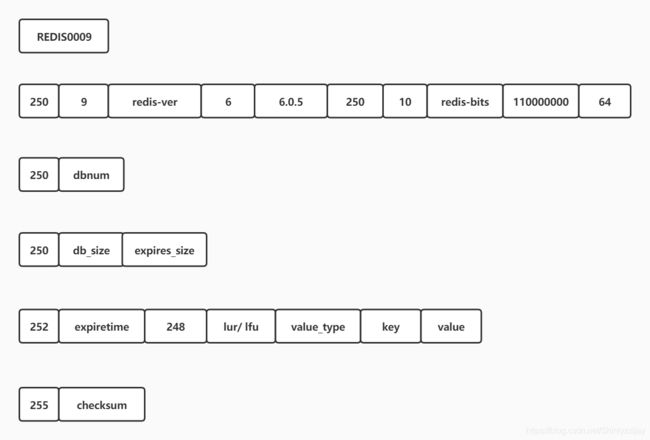
前面我们介绍了RDB的执行方式和源码,这里会继续介绍一下RDB的文件格式。由于RDB的文件格式在未来的版本中还是会发生变化,这里只是作为样例的方式进行介绍,本篇文件阅读的Redis版本为6.0.5 官方编码格式文档:Redis-RDB-Format,下图是Redis RDB 文件基本编码格式

各个部分介绍:
⭐REDIS:文件的头部就是该文件的魔数,RDB文件的魔数自然就是REDIS;
⭐RDB_VERSION:当前RDB格式版本,RDB本身随着Redis的升级也衍生出不同的版本;
⭐AUX_FIELD_KEY_VALUES_PAIRS:辅助字段,按照key-value的方式来记录一些Redis的信息,比如当前RDB文件所属Redis的版本,当前Redis是32位还是64位等等信息,这个辅助字段的大小是变化的,内容大致如下表所示:
| 字段名称 | 字段值 | 描述 |
|---|---|---|
| redis-ver | 6.0.5 | 当前Redis版本 |
| redis-bits | 64/32 | 当前Redis的编译位数 |
| ctime | 当前时间戳 | 当前时间戳 |
| used-mem | Redis 当前占用内存 | Redis 当前占用内存 |
| aof-preamble | 是否开启 aof/rdb 混合模式 | 是否开启 aof/rdb 混合模式 |
| … | … | … |
⭐DB_NUM:数据库序号;
⭐DB_DICT_SIZE:当前数据库键值对散列表的大小。Redis的每个数据库是一个散列表,这个字段指明当前数据库散列表的大小。这样在加载的时候可以直接将散列表扩展到指定大小(类比:为了防止HashMap的自动扩容,在创建的时候就指定大小)从而提升加载速度;
⭐EXPIRE_DICT_SIZE:当前数据库过期时间散列表的大小,理由和上面一样;
⭐KEY_VALUE_PAIRS:Redis中具体键值对的存储,即数据;
⭐EOF:RDB文件结束标志;
⭐CHECK_SUM:8个字节的校验码;
2.4.1、opcodes
此外 RDB 文件中为了区分出每个部分的字段,在每个部分字段之前都会有一个opcodes的字段,如下图所示:
从图中看出加上opcodes后文件各部分之间界限就清晰了,也为编解字节码做下基础。
2.4.2、RDB文件内容
空数据库下生成的RDB文件

存储了key_1 value1 key_2 value2 数据的RDB文件

3、AOF
AOF 是Redis的另外一种持久化方式,与RDB不同的是AOF能以同步的方式将数据持久化,而且对性能的占用率也低,RDB在Fork出子进程后,其实机器本身的性能是被分散了。那么既然AOF比RDB表现的更加优秀,为什么不直接使用AOF呢?
原因主要有两个方面:1、AOF存储的是Redis运行过程中的每一条指令,这样在高并发的情景下,AOF的文件会非常大,毕竟是记录下了每一次变更指令。2、AOF的加载速度不如RDB,当机器启动的时候AOF的加载的本质其实类似于新创建了一个client,并一条一条指令的读取到Redis中,相比RDB这种记录下最终状态的持久化方式自然就要慢的多。
但是由于RDB的执行是调度式的,期间如果发生故障是很容易造成数据丢失的,而AOF理论上是能做到只丢失一条命令,但是由于操作系统对文件独写的代价是很大的,实际运行中通过对性能和安全的折中我们往往采用的策略会比理论要差,但是整体来说会比RDB要好的多。为了发挥出二者持久化方式的优劣性,往往线上是采用RDB和AOF的混合模式。
3.1、AOF的执行流程
AOF的执行一般分为两种:1、命令同步持久化到缓冲区 ,2、缓冲区写入AOF文件 ,3、AOF文件重写。对应过程顺序为:append->sync->rewrite 的这里为了避免AOF的文件数据量过大,到达一定的要求后会把数据重写把统一数据变化的过程合并,流程如下所示:


3.1.1、写入AOF缓冲区
在 《8-命令处理生命周期-4》 中提到,所有的命令最终是通调用 server.c 里面的call方法执行的,所以为了能获取所有执行的命令,将aof的锚点放在call方法中就再合适不过了。redis将命令解析成RESP后存储在server.aof_buf中,其本身是一个sds动态字符类型。
void call(client *c, int flags) {
//.............省略很多代码...................
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
propagate(rop->cmd, rop->dbid, rop->argv, rop->argc, target);
//.............省略很多代码...................
}
/**
* 将命令传播出去,给 AOF 或者 Slaves.
*/
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags) {
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
//给AOF写入文件
feedAppendOnlyFile(cmd, dbid, argv, argc);
if (flags & PROPAGATE_REPL)
replicationFeedSlaves(server.slaves, dbid, argv, argc);
}
/**
* 执行完成的命令追加到AOF缓冲区
*/
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
//................省略代码................
//解析执行的命令为一个sds字符(RESP编码格式)
buf = catAppendOnlyGenericCommand(buf,argc,argv);
//................省略代码................
/**
* 将解析好的buf追加到server.aof_buf
*/
if (server.aof_state == AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
/**
* 当前正在执行重写,那么buf也要追加到重写的缓冲区中
*/
if (server.aof_child_pid != -1)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
}
这里需要提到的一点是,get命令等这种查询命令本质上是不会进入到AOF解析中去的,主要逻辑在call方法中的这段代码,通判断命令是否引起数据变化来选择是否要将命令进行传播,如果需要传播,则会调用propagate->feedAppendOnlyFile->catAppendOnlyGenericCommand解析命令并放入AOF缓冲区server.aof_buf
/*将命令传播到AOF或者主从复制中链路中*/
if (flags & CMD_CALL_PROPAGATE &&
(c->flags & CLIENT_PREVENT_PROP) != CLIENT_PREVENT_PROP) {
int propagate_flags = PROPAGATE_NONE;
//判断命令是否引起数据变化,如果是设置为复制/AOF传播
if (dirty) propagate_flags |= (PROPAGATE_AOF | PROPAGATE_REPL);
//..................................................
/**
* 调用传播函数
*/
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
propagate(c->cmd, c->db->id, c->argv, c->argc, propagate_flags);
}
缓冲区解析后的命令如下图所示,(命令:set test test):

3.1.2、AOF文件写入
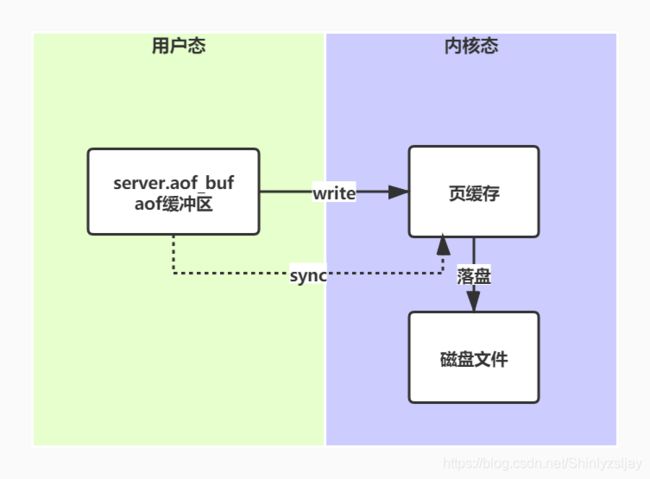
AOF持久化最终的目的是将数据写入文件中来实现持久化,而目前数据已经被解析写入了AOF的缓冲区server.aof_buf,写文件通过操作系统提供的write函数执行。但是调用write后缓冲区的数据会被写入到页缓存(还未落地),页缓存本身是基于操作系统如果需要将操作系统中的页缓存刷入磁盘则需要再调用fsync,调用fsync过程非常慢,中间会出现用户态->内核态的转换,为了提高性能,在安全性和高性能之间取折中方案,Redis提供以下几种方式进行数据落盘:
⭐no:不主动执行落盘操作,一切由操作系统自行决定性能最高;
⭐always:每执行一次写入就执行一次fsync,安全性最高但是性能也是最差的
⭐everysec:每1秒执行fsync,在安全性和性能之间取的折中方案;
生产环境一般建议使用appendfsync everysec 。控制其逻辑的代码位于flushAppendOnlyFile中:
//这里为什么要判断0呢?我是这样理解的,aof_buf里面的字符缓存一定要全部写入页缓存才能执行sync,不然会出现AOF解析后的命令还没全部write就刷盘了
if (sdslen(server.aof_buf) == 0) {
//判断是否需要进行fsync
if (server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.aof_fsync_offset != server.aof_current_size &&
server.unixtime > server.aof_last_fsync &&
!(sync_in_progress = aofFsyncInProgress())) {
goto try_fsync; //goto跳转
} else {
return;
}
}
//通过goto语句来跳转的
try_fsync:
if (server.aof_no_fsync_on_rewrite && hasActiveChildProcess())
return;
/* 对应前面的always */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
latencyStartMonitor(latency);
redis_fsync(server.aof_fd);
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_fsync_offset = server.aof_current_size;
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC && //对应前面的 everysec
server.unixtime > server.aof_last_fsync)) {
if (!sync_in_progress) {
aof_background_fsync(server.aof_fd);
server.aof_fsync_offset = server.aof_current_size;
}
server.aof_last_fsync = server.unixtime;
}
注:就算Redis的落盘行为设置成always,但是由于Redis是通过写入页缓存的方式落盘,可以实现顺序IO,其性能上相比其它随机写入的数据库还是要好一些的
3.1.3、AOF重写
随着Redis的运行,AOF文件会越来越大,尤其是当TPS很高的时候,这个时候就需要对AOF文件进行重写合并一个数据的变化为最终态。和异步RDB一样AOF重写是通过Fork出一个子进程来执行的,也不会对原有的文件进行修改或读取,子进程对所有数据库中所有的健各自生成一条相应的执行命令。最后将重写开始后重写期间父进程执行过的命令进行回放(在此重写之间父进程收到的数据会同步给重写的子进程),最后重写完成并生成一个新的AOF文件,重写的思路大致就是合并一条数据的变化过程如下所示例如:
#执行的命令
set key1 value1
set key1 value2
set key1 value3
set key1 value5
set key1 value7
#最终合并成
set key1 value7
AOF的重写有两种方式触发:1、通过配置达到一定的条件字段执行, 2、通过命令bgrewriteaof手动执行,配置自动触发的例子如下:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
上面两个配置的基本意思是,当AOF文件大于64MB的时候,并且AOF文件当前大小比基准大小增长了100%时,就会触发一次AOF重写。那么什么是基准大小呢?当数据库为空没有AOF文件的时候,基准大小为aof_buf缓冲区的大小。当执行过AOF后,基准大小为AOF文件大小,并且在完成重写后,基准大小也会更新为新的AOF文件大小。AOF重写的流程如下所示:
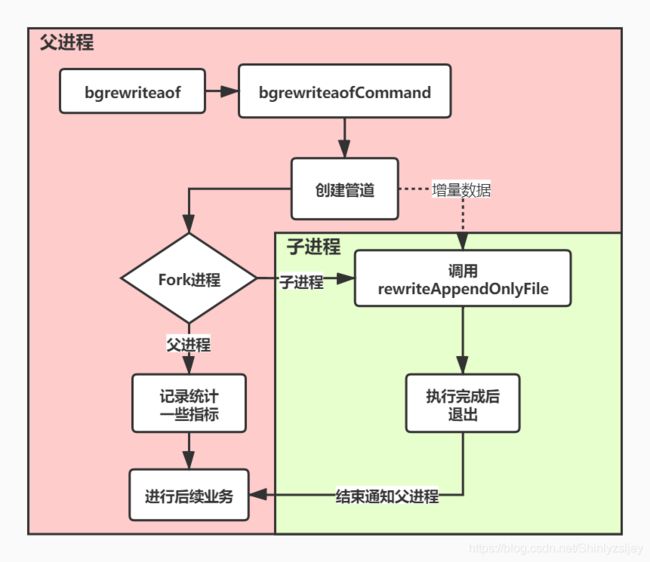
如果服务端在执行一条指令的时候正在执行AOF重写,命令会通过调用函数propagate->feedAppendOnlyFile同步到server.aof_rewrite_buf_blocks中去,server.aof_rewrite_buf_blocks的作用是,当期间正在发生AOF重写的时候保存服务端发生变更的命令,server.aof_rewrite_buf_blocks是aofrwblock结构体的链表,
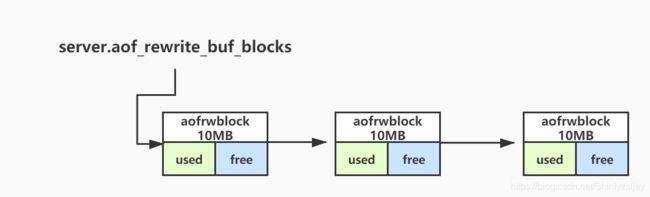
整个追加过程如下所示:

aofrwblock 结构体定义如下:
#define AOF_RW_BUF_BLOCK_SIZE (1024*1024*10) /* 10 MB per block */
typedef struct aofrwblock {
unsigned long used, free; //[缓存使用] 和 [空闲长度] 记录
char buf[AOF_RW_BUF_BLOCK_SIZE];
} aofrwblock;
aofrwblock该结构体会保存大概10MB的缓冲区内容(aof_buf),并且有缓冲区使用和空闲长度的记录。当一个block写满后,会开辟一个新的节点继续保存执行过的命令。写入的位置在feedAppendOnlyFile方法中,写入方式如下所示:
/* If a background append only file rewriting is in progress we want to
* accumulate the differences between the child DB and the current one
* in a buffer, so that when the child process will do its work we
* can append the differences to the new append only file. */
//如果当前正在执行AOF重写,则最佳到aof_rewrite_buf_blocks
if (server.aof_child_pid != -1)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf))
//追加写入block或者创建一给block写入
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
listNode *ln = listLast(server.aof_rewrite_buf_blocks);
aofrwblock *block = ln ? ln->value : NULL;
while(len) {
/* If we already got at least an allocated block, try appending
* at least some piece into it. */
if (block) {
unsigned long thislen = (block->free < len) ? block->free : len;
if (thislen) {
/* The current block is not already full. */
memcpy(block->buf+block->used, s, thislen);
block->used += thislen;
block->free -= thislen;
s += thislen;
len -= thislen;
}
}
if (len) {
/* First block to allocate, or need another block. */
int numblocks;
block = zmalloc(sizeof(*block));
block->free = AOF_RW_BUF_BLOCK_SIZE;
block->used = 0;
listAddNodeTail(server.aof_rewrite_buf_blocks,block);
/* Log every time we cross more 10 or 100 blocks, respectively
* as a notice or warning. */
numblocks = listLength(server.aof_rewrite_buf_blocks);
if (((numblocks+1) % 10) == 0) {
int level = ((numblocks+1) % 100) == 0 ? LL_WARNING :
LL_NOTICE;
serverLog(level,"Background AOF buffer size: %lu MB",
aofRewriteBufferSize()/(1024*1024));
}
}
}
.................................
}
在客户端输入bgrewriteaof命令后,命令会调用bgrewriteaofCommand函数中的rewriteAppendOnlyFileBackground->aofCreatePipes,然后创建6个管道(父进程在fork()之前会创建3组管道,fds[0]/fds[1],fds[2]/fds[3],fds[4]/fds[5],管道的本质就是内存中一块父子进程共享的内存空间),其创建逻辑如下所示:
int aofCreatePipes(void) {
int fds[6] = {
-1, -1, -1, -1, -1, -1};
int j;
//pipe()会两两创建管道,例如 fds[2]的话 fds[0]是接收,fds[1]是发送
if (pipe(fds) == -1) goto error; /* parent -> children data. */
if (pipe(fds+2) == -1) goto error; /* children -> parent ack. */
if (pipe(fds+4) == -1) goto error; /* parent -> children ack. */
/* Parent -> children data is non blocking.(非阻塞) */
// fds[0],fds[1],fds[2]管道都设置为非阻塞
if (anetNonBlock(NULL,fds[0]) != ANET_OK) goto error;
if (anetNonBlock(NULL,fds[1]) != ANET_OK) goto error;
if (aeCreateFileEvent(server.el, fds[2], AE_READABLE, aofChildPipeReadable, NULL) == AE_ERR) goto error;
//各个管道对应的定义
server.aof_pipe_write_data_to_child = fds[1];
server.aof_pipe_read_data_from_parent = fds[0];
server.aof_pipe_write_ack_to_parent = fds[3];
server.aof_pipe_read_ack_from_child = fds[2];
server.aof_pipe_write_ack_to_child = fds[5];
server.aof_pipe_read_ack_from_parent = fds[4];
server.aof_stop_sending_diff = 0;
return C_OK;
error:
serverLog(LL_WARNING,"Error opening /setting AOF rewrite IPC pipes: %s",
strerror(errno));
for (j = 0; j < 6; j++) if(fds[j] != -1) close(fds[j]);
return C_ERR;
}
此外管道的创建是两两配对的,这里一共创建了3组管道,其中fds[0],fds[1],fds[2]设置为非阻塞管道,也就是通过异步或者事件的方式执行,剩余的都是同步执行,创建管道最主要的目的就是让子进程能同步增量接收到父进程的数据变化命令,这样在完成AOF重写后,只剩余少量的命令需要回写,此外Redis对于管道的使用也是有定义的,保证数据的单向流动,例如下图所示:

父进程通过fds[1]将执行aof重写时积累的命令发送给子进程,子进程通过fds[0]进行接收并保存。当子进程执行完重写后,向fds[3]写入一个!通知父进程不需要在继续通过管道发送积累的命令,父进程通过fds[2]接收到!后向fds[5]也写入!表示确认已经收到(有点像TCP握手)。子进程通过fds[4]同步阻塞收到!后才可进行后续的退出操作。退出时会将接收到的积累命令进行回放,让后执行fsync。到这里也说明了为什么fds[0],fds[1],fds[2]是要创建成异步的管道,如果是非阻塞的话,主进程需要等待这个过程的结束,其中aof_pipe_write_data_to_child 和aof_pipe_read_data_from_parent是通过文件事件交互的,通过aofRewriteBufferAppend方法创建相应的文件事件,其实现如下所示:
if (aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) {
aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child,
AE_WRITABLE, aofChildWriteDiffData, NULL);
}
//子进程同步接收主进程的数据变化
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
listNode *ln;
aofrwblock *block;
ssize_t nwritten;
UNUSED(el);
UNUSED(fd);
UNUSED(privdata);
UNUSED(mask);
while(1) {
ln = listFirst(server.aof_rewrite_buf_blocks);
block = ln ? ln->value : NULL;
if (server.aof_stop_sending_diff || !block) {
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child,
AE_WRITABLE);
return;
}
if (block->used > 0) {
//同步写入文件
nwritten = write(server.aof_pipe_write_data_to_child,
block->buf,block->used);
if (nwritten <= 0) return;
memmove(block->buf,block->buf+nwritten,block->used-nwritten);
block->used -= nwritten;
block->free += nwritten;
}
if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln);
}
}
如果还没理解管道的作用话,下面的图可以描述一下使用管道和不使用管道的区别:

从中可以看出,管道最主要的目的是当子进程重写完AOF文件通知主进程后,避免主进程因为期间产生大量命令追加而导致的性能下降的问题。
4、混合持久化
混合持久化指进行AOF重写时子进程将当前时间点的数据快照保存为RDB文件格式,然后将父亲期间积累的命令保存为AOF文件格式,其文件格式如下所示:

服务重启时,在加载前先判断文件的头部魔数是否为REDIS,如果是的话先按照RDB的方式加载数据,待RDB加载完成时,剩余的部分使用AOF的方式加载,开启混合模式的配置如下:
# preamble 意思是 序言,绪论;前言,开场白
aof-use-rdb-preamble yes
AOF开始重写时,调用rewriteAppendOnlyFile方法时会判断当前Redis是否开启了混合模式,如果开启,则首先按RDB的保存方式保存当前的数据快照。保存完成后回放积累的命令到文件末尾即可,。
//判断是否开启了混合持久化模式
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(&aof,&error,RDBFLAGS_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
//未开启,则存粹重写AOF
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
到这里的时候可以思考这么几个问题:
1、AOF重写和RDB哪个性能高?
2、AOF重写是否会发生内存中的数据和文件中的数据不一致?(现有的AOF文件中缺失了某个指令但是数据库中还存在)
3、混合模式,AOF重写哪个性能高?