GIS Tools for Hadoop(最新版)
前言
看了ESRI:《GIS Tools for Hadoop 使用介绍(ArcGIS 与 Hadoop 集成)》,想动手试试看,了解Hadoop是怎么与GIS结合的。
随着ArcGIS 10.2版本的发布,一同推出的开源工具包GIS Tools for Hadoop,完美的诠释了海量空间数据与分布式运算的结合。GIS Tools for Hadoop 是一个开源的工具包,它定义和构建了一整套空间分析的环境,在GIS与hadoop之间搭建起了一个桥梁 [查看更多]。Esri能和Hadoop 进行结合这得益于 Esri提供的Geometry API,其原理是从hadoop的hdfs 文件系统中获取数据,然后使用这些 Geometry API 将数据转化为 Esri 的几何对象,或者要素等,当有了这些空间数据之后,那么就可以进行空间分析等。
软件与数据
- 软件
1. Hadoop [链接](不用管Spark的安装部分
2. Hive [链接]
- 数据
Windows :到 GitHub:gis-tools-for-hadoop 把整个文件下载下来
使用 XShell 连接虚拟机master,进入/data,输入rz上传文件
解压,提取到桌面(/home/你的用户名/Desktop)
当然也可以直接在虚拟机上用 wget 或 git [ 链接 ]
wget https://github.com/Esri/gis-tools-for-hadoop将数据导入到hdfs(注:/usr/hadoop/hdfs/input是之前我在hdfs下创建的一个文件夹)
[root@master ~]# hadoop fs -put /home/你的用户名/Desktop/gis-tools-for-hadoop-master/samples /usr/hadoop/hdfs/input
#删除HDFS文件夹
#[root@master ~]# hadoop fs -rm -r /usr/hadoop/hdfs/input列出HDFS文件
[root@master ~]# hadoop fs -ls /usr/hadoop/hdfs/input/samples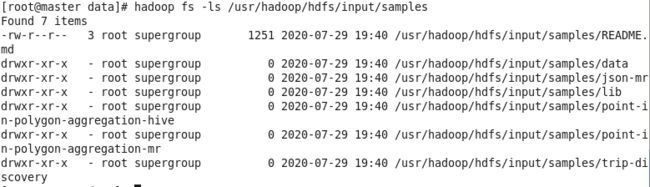
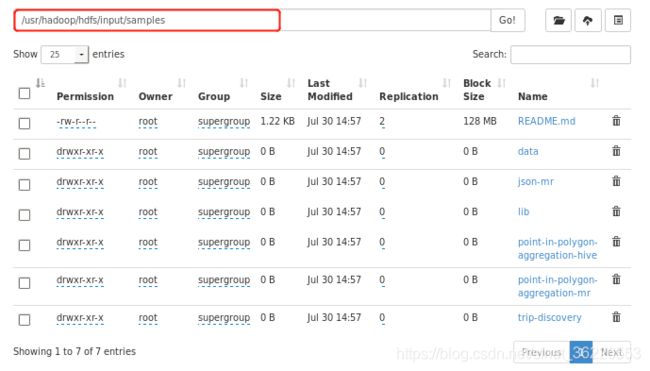
也可以在 http://192.168.1.180:50070/explorer.html 看到
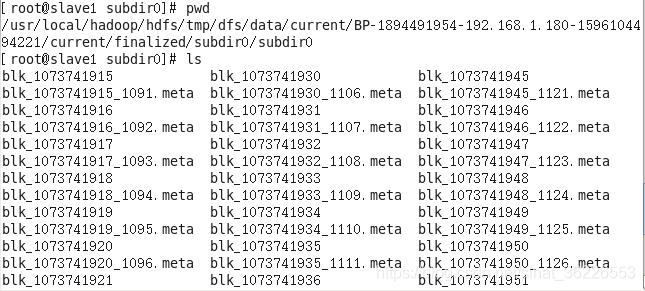
其他:HDFS上传文件后datanode元数据目录和和datanode数据目录的变化
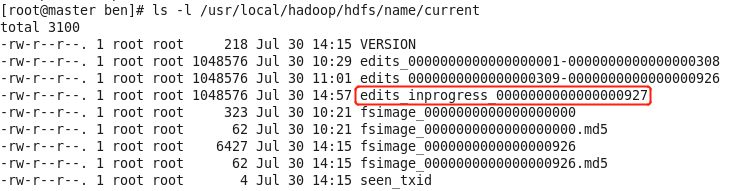
Master
在namenode设置的存储元数据的目录中(dfs.name.dir ),可以看到 fsimage 镜像文件,以及编辑日志文件edits_*
Slave
可以在任意datanode节点机器看到很多碎文件
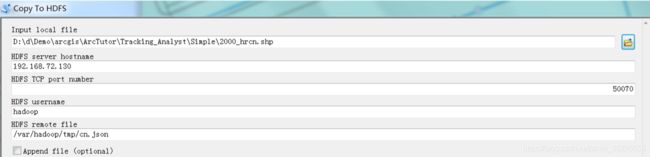
上传数据到HDFS还有一个更简单的方法:使用ESRI 的 Hadoop Tools [链接]
正文
1. 添加jar包
hive > add jar
> /home/你的用户名/Desktop/gis-tools-for-hadoop-master/samples/lib/spatial-sdk-hive-2.0.0.jar;
hive > add jar
> /home/你的用户名/Desktop/gis-tools-for-hadoop-master/samples/lib/esri-geometry-api-2.0.0.jar;
hive > add jar
> /home/你的用户名/Desktop/gis-tools-for-hadoop-master/samples/lib/spatial-sdk-json-2.0.0.jar;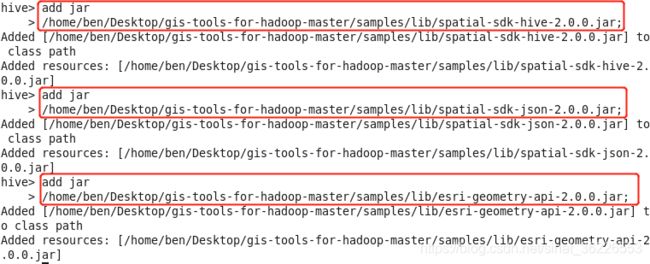
2. 创建临时函数
hive > create temporary function ST_Point as 'com.esri.hadoop.hive.ST_Point';
hive > create temporary function ST_Contains as 'com.esri.hadoop.hive.ST_Contains';
3. 创建外部表
hive > CREATE EXTERNAL TABLE IF NOT EXISTS earthquakes (earthquake_date STRING, latitude DOUBLE, longitude DOUBLE, depth DOUBLE, magnitude DOUBLE, magtype string, mbstations string, gap string, distance string, rms string, source string, eventid string)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> LOCATION '/usr/hadoop/hdfs/input/samples/data/earthquake-data';
hive > CREATE EXTERNAL TABLE IF NOT EXISTS counties (Area string, Perimeter string, State string, County string, Name string, BoundaryShape binary)
> ROW FORMAT SERDE 'com.esri.hadoop.hive.serde.EsriJsonSerDe'
> STORED AS INPUTFORMAT 'com.esri.json.hadoop.EnclosedEsriJsonInputFormat'
> OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
> LOCATION '/usr/hadoop/hdfs/input/samples/data/counties-data';参照网上的教程,在创建counties表时会产生如下错误
![]()
这是因为版本更新后,有些类名进行了修改(通过官方给的案例中也可以看到 [链接])

'com.esri.json.hadoop.EnclosedJsonInputFormat' 改为了 'com.esri.json.hadoop.EnclosedEsriJsonInputFormat'
'com.esri.hadoop.hive.serde.JsonSerde' 改为了 'com.esri.hadoop.hive.serde.EsriJsonSerDe'
4. 运行包含统计
hive > SELECT counties1.name, count(*) cnt FROM counties1
> JOIN earthquakes1
> WHERE ST_Contains(counties1.boundaryshape, ST_Point(earthquakes1.longitude, earthquakes1.latitude))
> GROUP BY counties1.name
> ORDER BY cnt desc;会遇到错误

按照提示进行设置

又遇到报错(参照该博主[链接]的输出结果
![]()
找不到类?尝试着把 spatial-sdk-json-2.0.0.jar 放到了 hadoop/share/hadoop/mapreduce/lib下 [链接],结果这个错误真解决了,但又报了另一个错误

按照网上的解决办法关闭本地 map join 优化 [链接]
hive > set hive.auto.convert.join = false;终于成功运行

其他:以上操作实质上实现的是点与面数据进行空间连接并统计,得到每个county下发生的earthquake数目。
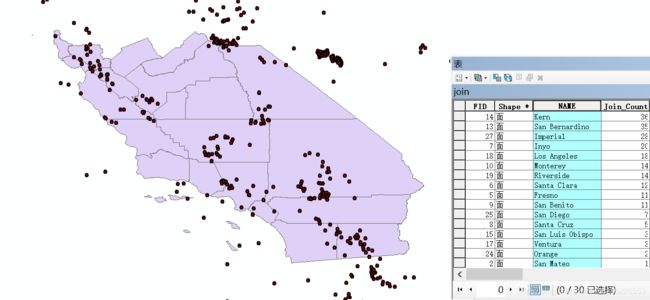
题外话
看 GIS Tools for Hadoop 的 GitHub 更新时间,感觉这个项目好像没有跟进了,可能和Hadoop的MapReduce逐渐被性能更强的Spark取代有关,所以其实可以去学习GeoSpark、GeoMesa等。
参考
[Hadoop学习]Esri/gis-tools-for-hadoop介绍
hive在hadoop中的一个demo运行过程总结
Hadoop与海量GIS数据的碰撞
问题
解决hive报错FAILED: SemanticException Cartesian products are disabled for safety的问题
Hive中运行任务报错:FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTas