2019独角兽企业重金招聘Python工程师标准>>> 
1.简介
ycsb 它是一个数据库测试工具,全称为“Yahoo! Cloud Serving Benchmark”。它内置了对常见NoSQL数据库和数据网格产品的支持,如Cassandra、MongoDB、HBase、Redis、Infinispan等等很多的主流产品,而且不仅安装使用简单,还能自由扩展测试数据类型和支持的数据库产品。产品介绍:https://s.yimg.com/ge/labs/v1/files/ycsb-v4.pdf
2.编译
安装
下载地址: https://github.com/brianfrankcooper/YCSB/releases/download/0.6.0/ycsb-0.6.0.tar.gz
源码地址:https://github.com/brianfrankcooper/YCSB
wiki地址:https://github.com/brianfrankcooper/YCSB/wiki
编译
全部database build
mvn clean package单个database build
mvn -pl com.yahoo.ycsb:hbase10-binding -am clean package安装包位置
- 全部database ---distrbution工程内的target中
- 单个database --- 在各种database文件夹的target中
(注意:不同版本的工程编译完成后可能不太一致,但是大体上都是一致的)
3.如何使用
编译tar.gz包之后目录如下:(我下载的最新的非发行版是0.7)

解释:
目录中包含 lib,bin,workloads和数据库的目录。
-- lib 是ycsb的核心jar所在位置 (当你运行时可能会遇到log4j版本不够高,此时把高版本的jar copy到此处)
-- bin 是运行到启动脚本 (此脚本是python写的,可能会遇到你的缺失python的一些组件,请自行安装)
-- workloads 是测试的一些模版 (当然你可以自己写,或者是修改它)
--数据库的一些配置和依赖的jar包 (手动编译可能不会去少jar,但是有的发行版本缺少一些jar导致运行不成功,比如网上比较多的 0.1.4 版本)
Workloads讲解
默认提供的模版为
- workloada读多写少,50%读,50%更新。
- workloadb读多写少,95%读,5%更新。
- workloadc读多无写,100%读。
- workloadd读多写少,95%读,5%插入。
- workloade读多写少,95%读,5%插入。
- workloadf 读多写少,50%读,50%读写修改同一条记录。
workloada解读
# Yahoo! Cloud System Benchmark
# Workload A: Update heavy workload
# Application example: Session store recording recent actions
#
# Read/update ratio: 50/50
# Default data size: 1 KB records (10 fields, 100 bytes each, plus key)
# Request distribution: zipfian
#记录条数
recordcount=1000
#操作次数
operationcount=1000
#核心模版类(一般请不用修改,如果是自定义workload则需要修改)
workload=com.yahoo.ycsb.workloads.CoreWorkload
#是否读取所有字段
readallfields=true
#读取百分比
readproportion=0.5
#更新百分比
updateproportion=0.5
#全表查询百分比
scanproportion=0
#插入百分比
insertproportion=0
#请求数据访问数据的分布规则
requestdistribution=zipfian具体参数
- fieldcount: 每条记录字段个数 (default: 10)
- fieldlength: 每个字段长度 (default: 100)
- readallfields: 是否读取所有字段true或者读取一个字段false (default: true)
- readproportion: 读取作业比例 (default: 0.95)
- updateproportion: 更新作业比例 (default: 0.05)
- insertproportion: 插入作业比例 (default: 0)
- scanproportion: 扫描作业比例 (default: 0)
- readmodifywriteproportion: 读取一条记录修改它并写回的比例 (default: 0)
- requestdistribution: 请求的分布规则 uniform, zipfian or latest (default: uniform)
- maxscanlength: 扫描作业最大记录数 (default: 1000)
- scanlengthdistribution: 在1和最大扫描记录数的之间的分布规则 (default: uniform)
- insertorder: 记录被插入的规则ordered或者hashed (default: hashed)
- operationcount: 执行的操作数.
- maxexecutiontime: 执行操作的最长时间,当然如果没有超过这个时间以运行时间为主。
- table: 测试表的名称 (default: usertable)
- recordcount: 加载到数据库的纪录条数 (default: 0)
安装
安装很简单,直接将包copy到服务器解压即可。
tar -zxvf ycsb-0.7.0.tar.gz
cd ycsb-0.7.04.运行调试
本文只讲解HBase导入性能调试。(在每次测试前请,清空测试表)
--解压之后,在测试之前需要做3步验证,否则不能运行(前提是保证HBase正常运行)
--需要提前建表,默认表名称是 “usertable” create ‘usertable’,’f1'
1.关于log4j
core/lib 目录下需要log4j 1.6版本以上的版本,否则着添加相关jar
2.关于NoSQL配置
hbase-binding/conf 目录下需要将集群hbase的hbase-site.xml copy到这个目录(注意 hbase.rootdir这个参数要写成namenode节点加端口,因为有些HBase HA设置这里写到不符合要求)
hbase-binding/lib 目录下需要包含hbase的所有jar包 和 hadoop相关jar hadoop-hdfs /hadoop-
auth/hadoop-common/hadoop-annotations
运行命令
导入数据
./bin/ycsb load hbase -P workloads/workloada -p columnfamily=f1 -s > load.dat运行测试模版
./bin/ycsb run hbase -P workloads/workloada -p columnfamily=f1 -s > run.dat解释:load表示导入 run表示运行
hbase导入到类型
-P 是YCSB提供的一个测试模版(可以修改,也可以自己写一个,也可以通过 -p 参数覆盖)
-s > load.dat 表示将结果写到文件load.dat里
workloads 详细配置请看:https://github.com/brianfrankcooper/YCSB/wiki/Running-a-Workload
运行参数 详细请看:https://github.com/brianfrankcooper/YCSB/wiki/Core-Properties
日志如下:
数据导入log
Command line: -db com.yahoo.ycsb.db.HBaseClient -P ../workloads/workloada -p columnfamily=f1 -s -load
[OVERALL], RunTime(ms), 2266.0
[OVERALL], Throughput(ops/sec), 441.306266548985
[INSERT], Operations, 1000
[INSERT], AverageLatency(us), 1555.866
[INSERT], MinLatency(us), 106
[INSERT], MaxLatency(us), 1316612
[INSERT], 95thPercentileLatency(ms), 0
[INSERT], 99thPercentileLatency(ms), 0
[INSERT], Return=0, 1000
[INSERT], 0, 997
[INSERT], 1, 2
[INSERT], 2, 0
[INSERT], 3, 0
[INSERT], 4, 0
[INSERT], 5, 0
...测试模版运行log
Command line: -db com.yahoo.ycsb.db.HBaseClient -P ../workloads/workloada -p columnfamily=f1 -s -t
[OVERALL], RunTime(ms), 7899.0
[OVERALL], Throughput(ops/sec), 126.59830358273199
[UPDATE], Operations, 514
[UPDATE], AverageLatency(us), 2788.3696498054474
[UPDATE], MinLatency(us), 59
[UPDATE], MaxLatency(us), 1353466
[UPDATE], 95thPercentileLatency(ms), 0
[UPDATE], 99thPercentileLatency(ms), 0
[UPDATE], Return=0, 514
[UPDATE], 0, 512
[UPDATE], 1, 1
[UPDATE], 2, 0
...
[UPDATE], 999, 0
[UPDATE], >1000, 1
[READ], Operations, 486
[READ], AverageLatency(us), 12840.707818930041
[READ], MinLatency(us), 1491
[READ], MaxLatency(us), 348069
[READ], 95thPercentileLatency(ms), 38
[READ], 99thPercentileLatency(ms), 59
[READ], Return=0, 486
[READ], 0, 0
[READ], 1, 37
[READ], 2, 98
...
5.结构分析
由于YCSB可以自己扩展数据库类型,所以这里简单讲解下结构。
运行机制
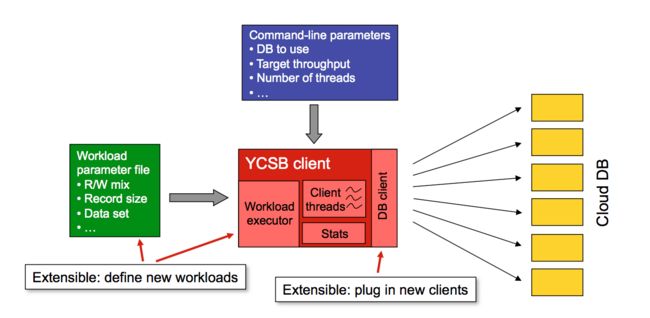
其中DB client就是我们可以自行扩展的组件。
新建DB Client
1.新建工程:在YCSB根目录下,新建一个maven工程,子工程会自动加载到parents 工程中。
2.添加依赖:将core包和其他依赖包写入pom文件中,并加入build配置。(可以参照其他子工程)
3.添加子类:新工程下的类需要继承core包下的DB类
4.执行:可以通过-db指定我们的DB类,或者在启动脚本中加入新工程DB类的别名