深入浅出最优化(5) 共轭梯度下降法
1 共轭方向的定义
对于正定二次函数 f ( x ~ ) = 1 2 x ~ T G ~ x ~ + b ~ T x ~ f(\tilde{x})=\frac{1}{2}\tilde{x}^T\tilde{G}\tilde{x}+\tilde{b}^T\tilde{x} f(x~)=21x~TG~x~+b~Tx~,其中 G G G是 n × n n\times n n×n对角阵,对角元均为正数,这种情况下函数关于原点中心对称,每列由一个n元向量组成,向着每个维度,即正交搜索方向 d ~ \tilde{d} d~,作一次精确线搜索就可以得到最小值的精确解,具有二次终止性。这个过程结合图像不难理解。
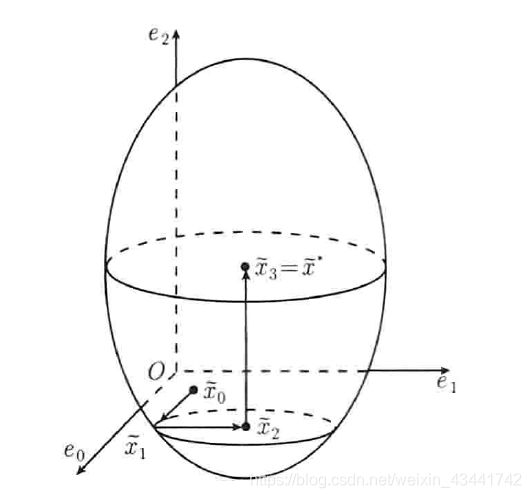
若 G G G是是 n × n n\times n n×n对称正定阵,而非对角阵,为了利用这一性质,我们需要将非对角阵变换为对角阵。作变换 x ~ = D x \tilde {x}=Dx x~=Dx,则有 f ( D x ) = 1 2 x T ( D T G D ) x + b T ( D x ) f(Dx)=\frac{1}{2}x^T(D^TGD)x+b^T(Dx) f(Dx)=21xT(DTGD)x+bT(Dx),D中包含的每两个向量满足:
d i T G d j = 0 , i , j = 0 , 1 , . . . , n − 1 , i ≠ j d_i^TGd_j=0,\quad i,j=0,1,...,n-1,i\neq j diTGdj=0,i,j=0,1,...,n−1,i=j
这样一来,最后 D T G D D^TGD DTGD就变成了对角矩阵 G ~ \tilde{G} G~。我们称这样的每两个方向 d i d_i di和 d j d_j dj为共轭方向,经过这样的变换可以将共轭方向变为正交搜索方向。
三维直角坐标系中的正交搜索方向是很容易求取的,而对于非对角正定二次函数,我们主要要确定共轭方向,这相当于是对坐标进行变换后在新的坐标空间内的正交搜索方向。
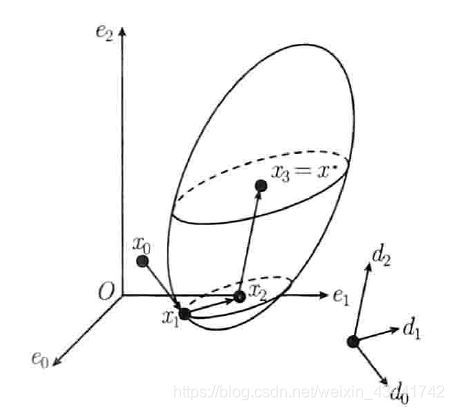
设 G G G为 n × n n\times n n×n。若存在对称正定矩阵 T T T,使得 T 2 = G T^2=G T2=G,则称 T T T为 G G G的平方根矩阵,记为 T = G T=\sqrt{G} T=G,有变换 d = T − 1 d ~ d=T^{-1}\tilde{d} d=T−1d~将正交搜索方向变为共轭方向。
对于秩为n的对称正定矩阵G,共轭方向有n个。
由任意 x 0 x_0 x0出发,依次沿直线 f ( α ) = x k + α d k f(\alpha)=x_k+\alpha d_k f(α)=xk+αdk作满足 g k T d j = 0 g_k^Td_j=0 gkTdj=0的精确线性搜索,其中 g k = G x k + b g_k=Gx_k+b gk=Gxk+b(正定二次函数梯度),则搜满n个共轭方向后 x k x_k xk是线性流形 X k = { x ∣ x ∈ R n , x = x 0 + ∑ j = 0 k − 1 β j d j , β j ∈ R , j = 0 , . . . , k − 1 } X_k=\{x|x\in R^n,x=x_0+\displaystyle\sum_{j=0}^{k-1}\beta_jd_j,\beta_j\in R,j=0,...,k-1\} Xk={ x∣x∈Rn,x=x0+j=0∑k−1βjdj,βj∈R,j=0,...,k−1}中的极小点。
2 针对二次函数的共轭梯度法
给定初始点,取初始搜索方向为负梯度方向,在后面的迭代中取负梯度方向和前一搜索方向的线性组合作为搜索方向 d k = − ∇ f ( x k ) + β k d k − 1 , k ≥ 1 d_k=-\nabla f(x_k)+\beta_kd_{k-1},k\geq 1 dk=−∇f(xk)+βkdk−1,k≥1,控制 β k \beta_k βk使得共轭性条件 d k T G d k − 1 = 0 d_k^TGd_{k-1}=0 dkTGdk−1=0满足。
d k = { − ∇ f ( x 0 ) k = 0 − ∇ f ( x 0 ) + β k d k − 1 k ≥ 1 d_k=\begin{cases}-\nabla f(x_0)\quad k=0\\-\nabla f(x_0)+\beta_k d_{k-1}\quad k\geq 1\end{cases} dk={ −∇f(x0)k=0−∇f(x0)+βkdk−1k≥1
对于共轭方向有 d k − 1 T G d k = 0 d^T_{k-1}Gd_k=0 dk−1TGdk=0,则有 d k − 1 T G d k = − d k − 1 T G ∇ f ( x k ) + β k d k − 1 T G d k − 1 = 0 d_{k-1}^TGd_k=-d_{k-1}^TG\nabla f(x_k)+\beta_k d_{k-1}^TGd_{k-1}=0 dk−1TGdk=−dk−1TG∇f(xk)+βkdk−1TGdk−1=0,所以 β k = d k − 1 T G ∇ f ( x k ) d k − 1 T G d k − 1 \beta_k=\frac{d_{k-1}^TG\nabla f(x_k)}{d_{k-1}^TGd_{k-1}} βk=dk−1TGdk−1dk−1TG∇f(xk)。
因此可以得到针对二次函数的共轭梯度法步骤:
- 给定初始点,令 d 0 = − g 0 , k = 0 d_0=-g_0,k=0 d0=−g0,k=0
- 计算 d k = − g k + ∑ j = 0 k − 1 d j T G g k d j T G d j d j d_k=-g_k+\displaystyle\sum_{j=0}^{k-1}\frac{d_j^TGg_k}{d_j^TGd_j}d_j dk=−gk+j=0∑k−1djTGdjdjTGgkdj
- 若 k = n − 1 k=n-1 k=n−1,则停止
- 线搜索确定步长
- 求 g k + 1 = ∇ f ( x k + α d k ) g_{k+1}=\nabla f(x_k+\alpha d_k) gk+1=∇f(xk+αdk),令 k = k + 1 k=k+1 k=k+1,转步2
3 针对一般函数的共轭梯度法
为了使得共轭梯度法适用于一般函数,我们要消除掉迭代公式中的G。
x k = x k − 1 + α k − 1 d k − 1 , k = 1 , 2 , . . . x_{k}=x_{k-1}+\alpha_{k-1}d_{k-1},k=1,2,... xk=xk−1+αk−1dk−1,k=1,2,...,两边求梯度有 ∇ f ( x k ) = ∇ f ( x k − 1 ) + α k − 1 G d k − 1 \nabla f(x_k)=\nabla f(x_{k-1})+\alpha_{k-1}Gd_{k-1} ∇f(xk)=∇f(xk−1)+αk−1Gdk−1,则有 G d k − 1 = ∇ f ( x k ) − ∇ f ( x k − 1 ) α k − 1 Gd_{k-1}=\frac{\nabla f(x_k)-\nabla f(x_{k-1})}{\alpha_{k-1}} Gdk−1=αk−1∇f(xk)−∇f(xk−1),代入 β k \beta_k βk的计算公式可以消掉 G G G,这种方法被称为HS共轭梯度法,有 β k H S = ∇ f ( x k ) T [ ∇ f ( x k ) − ∇ f ( x k − 1 ) ] d k − 1 T [ ∇ f ( x k ) − ∇ f ( x k − 1 ) ] , k = 1 , 2 , . . . \beta_k^{HS}=\frac{\nabla f(x_k)^T[\nabla f(x_k)-\nabla f(x_{k-1})]}{d_{k-1}^T[\nabla f(x_k)-\nabla f(x_{k-1})]},k=1,2,... βkHS=dk−1T[∇f(xk)−∇f(xk−1)]∇f(xk)T[∇f(xk)−∇f(xk−1)],k=1,2,...
HS法的共轭性证明见附录1。由共轭性证明我们可以得到三个结论:
- ∇ f ( x k ) T d j = 0 \nabla f(x_k)^Td_j=0 ∇f(xk)Tdj=0
- ∇ f ( x k ) T ∇ f ( x j ) = 0 , j < k \nabla f(x_k)^T\nabla f(x_j)=0,j
∇f(xk)T∇f(xj)=0,j<k - ∇ f ( x k ) T d k = − ∣ ∣ ∇ f ( x k ) ∣ ∣ 2 \nabla f(x_k)^Td_k=-||\nabla f(x_k)||^2 ∇f(xk)Tdk=−∣∣∇f(xk)∣∣2
利用以上三个结论可以得到HS共轭梯度法的更多变形,这两种变形产生算法的收敛性是可以得到证明的:
- PRP共轭梯度法: β k P R P = ∇ f ( x k ) T [ ∇ f ( x k ) − ∇ f ( x k − 1 ) ] ∣ ∣ ∇ f ( x k − 1 ) ∣ ∣ 2 , k = 1 , 2 , . . . \beta_k^{PRP}=\frac{\nabla f(x_k)^T[\nabla f(x_k)-\nabla f(x_{k-1})]}{||\nabla f(x_{k-1})||^2},k=1,2,... βkPRP=∣∣∇f(xk−1)∣∣2∇f(xk)T[∇f(xk)−∇f(xk−1)],k=1,2,...
- FR共轭梯度法: β k F R = ∣ ∣ ∇ f ( x k ) ∣ ∣ 2 ∣ ∣ ∇ f ( x k − 1 ) ∣ ∣ 2 , k = 1 , 2 , . . . \beta_k^{FR}=\frac{||\nabla f(x_k)||^2}{||\nabla f(x_{k-1})||^2},k=1,2,... βkFR=∣∣∇f(xk−1)∣∣2∣∣∇f(xk)∣∣2,k=1,2,...
步骤:
- 给定初始点 x 0 ∈ R n x_0\in R^n x0∈Rn,精度 ϵ > 0 \epsilon>0 ϵ>0,令 d 0 = − ∇ f ( x 0 ) , k = 0 d_0=-\nabla f(x_0),k=0 d0=−∇f(x0),k=0
- 若满足终止准则,则得解 x k x_k xk,算法终止
- 确定步长 α k \alpha_k αk
- 令 x k + 1 = x k + α k d k x_{k+1}=x_k+\alpha_kd_k xk+1=xk+αkdk
- 由以上各种方法确定 β k + 1 \beta_{k+1} βk+1
- d k + 1 = − ∇ f ( x k + 1 ) + β k + 1 d k d_{k+1}=-\nabla f(x_{k+1})+\beta_{k+1}d_{k} dk+1=−∇f(xk+1)+βk+1dk确定 d k + 1 d_{k+1} dk+1,令 k = k + 1 k=k+1 k=k+1,转2
4 性能评估
4.1 收敛性
使用精确搜索时,算法的收敛性是可以保证的。(证明见附录2)
-
对于FR算法,采用非精确线性搜索时,需要使用强Wolfe-Powell条件,且 0 < σ < 1 2 0<\sigma<\frac{1}{2} 0<σ<21(证明见附录3)
-
对于PRP算法,采用非精确线性搜索时,需要使用** P R P + PRP^+ PRP+公式**: β P R P + = m a x { β P R P , 0 } \beta^{PRP^+}=max\{\beta^{PRP},0\} βPRP+=max{ βPRP,0}。这是为了使得产生的 β \beta β不为负数,保证下降方向的产生
4.2 其他性能
- 二次终止性:满足,且若矩阵G有r个不同特征值,则算法最多经过r次迭代达到问题的最优解
- 计算量:小,无需计算黑森矩阵
- 储存空间:小,只需记录两点梯度和前一点方向。这使得共轭梯度法适用于解决大规模最优化问题
5 实战测试
对于第一节中提出的最小二乘问题, x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4的初值均在 [ − 2 , 2 ] [-2,2] [−2,2]的范围内随机生成,总共生成100组起点。统计迭代成功(在1000步内得到最优解且单次步长搜索迭代次数不超过1000次)的样本的平均迭代步数、平均迭代时间和得到的最优解及残差平方和最小值。
PRP+:
| 平均迭代步数 | 平均迭代时间 | 最优解 | 残差平方和最小值 |
|---|---|---|---|
| 17.1 | 0.41s | x 1 = 0.1925 x 2 = 0.1989 x 3 = 0.1252 x 4 = 0.1391 x_1=0.1925~x_2=0.1989~x_3=0.1252~ x_4=0.1391 x1=0.1925 x2=0.1989 x3=0.1252 x4=0.1391 | 1.5382 × 1 0 − 4 1.5382\times10^{-4} 1.5382×10−4 |
FR:
| 平均迭代步数 | 平均迭代时间 | 最优解 | 残差平方和最小值 |
|---|---|---|---|
| 23.2 | 0.56s | x 1 = 0.1807 x 2 = 0.4828 x 3 = 0.1868 x 4 = 0.2556 x_1=0.1807~x_2=0.4828~x_3=0.1868~ x_4=0.2556 x1=0.1807 x2=0.4828 x3=0.1868 x4=0.2556 | 1.8243 × 1 0 − 4 1.8243\times10^{-4} 1.8243×10−4 |
代码实现
import numpy as np
from Function import Function #定义法求导工具
from lagb import * #线性代数工具库
from scipy import linalg
n=4 #x的长度
def myFunc(x):
return #目标方程
x=np.zeros(n) #初始值点
e=0.001
beta1=1
sigma=0.4
rho=0.55
tar=Function(myFunc)
k=0
d=-tar.grad(x)
while tar.norm(x)>e:
a=1
if not (tar.value(x+a*d)<=tar.value(x)+rho*a*dot(turn(tar.grad(x)),d) and \
np.abs(dot(turn(tar.grad(x+a*d)),d))>=sigma*dot(turn(tar.grad(x)),d)):
a=beta1
while tar.value(x+a*d)>tar.value(x)+rho*a*dot(turn(tar.grad(x)),d):
a*=rho
while np.abs(dot(turn(tar.grad(x+a*d)),d))<sigma*dot(turn(tar.grad(x)),d):
a1=a/rho
da=a1-a
while tar.value(x+(a+da)*d)>tar.value(x)+rho*(a+da)*dot(turn(tar.grad(x)),d):
da*=rho
a+=da
lx=x
x=x+a*d
beta=np.max((dot(turn(tar.grad(x)),tar.grad(x)-tar.grad(lx))/(tar.norm(lx)**2),0)) #PRP+
beta=(tar.norm(x)**2)/(tar.norm(lx)**2) #FR
d=-tar.grad(x)+beta*d
k+=1
print(k)
附录
-

-
使用精确搜索时共轭梯度算法收敛性证明:因为 g k T d k − 1 = 0 g_{k}^Td_{k-1}=0 gkTdk−1=0,从而 g k T d k = − g k T g k + β k − 1 g k T d k − 1 < 0 g_k^Td_k=-g_k^Tg_k+\beta_{k-1}g_k^Td_{k-1}<0 gkTdk=−gkTgk+βk−1gkTdk−1<0
-

