TruNet: Short Videos Generation from Long Videos via Story-Preserving Truncation(论文翻译)
TruNet: Short Videos Generation from Long Videos via Story-Preserving Truncation
TruNet:通过保存故事截断从长视频生成生成短视频
在这项工作中,我们引入了一个新问题,称为{\ em故事保存长视频截断},该问题需要一种算法来自动将长时间视频截断为多个简短且吸引人的子视频,每个子视频都包含不间断的故事。这不同于传统的视频精彩片段检测或视频摘要问题,因为每个子视频都需要保持连贯且完整的故事,这对于资源生产视频共享平台(例如Youtube,Facebook,TikTok,Kwai等)变得尤为重要为了解决该问题,我们收集并注释了一个新的大型视频截断数据集,称为TruNet,其中包含1470个视频,每个视频平均包含11个短故事。利用新的数据集,我们进一步开发和训练了一种用于视频截断的神经体系结构,该体系结构包含两个部分:边界感知网络(BAN)和快速转发长期短期记忆(FF-LSTM)。我们首先使用BAN通过共同考虑帧级别的吸引力和边界性来生成高质量的时间建议。然后,我们使用FF-LSTM(倾向于捕获一系列帧之间的高阶依存关系)来确定时间建议是否是连贯且完整的故事。我们表明,我们提出的框架在定量方法和用户研究方面都优于现有的用于保留故事的长视频截断问题的方法。可通过https://ai.baidu.com/broad/download将数据集用于公共学术研究。
In this work, we introduce a new problem, named as {\em story-preserving long video truncation}, that requires an algorithm to automatically truncate a long-duration video into multiple short and attractive sub-videos with each one containing an unbroken story. This differs from traditional video highlight detection or video summarization problems in that each sub-video is required to maintain a coherent and integral story, which is becoming particularly important for resource-production video sharing platforms such as Youtube, Facebook, TikTok, Kwai, etc. To address the problem, we collect and annotate a new large video truncation dataset, named as TruNet, which contains 1470 videos with on average 11 short stories per video. With the new dataset, we further develop and train a neural architecture for video truncation that consists of two components: a Boundary Aware Network (BAN) and a Fast-Forward Long Short-Term Memory (FF-LSTM). We first use the BAN to generate high quality temporal proposals by jointly considering frame-level attractiveness and boundaryness. We then apply the FF-LSTM, which tends to capture high-order dependencies among a sequence of frames, to decide whether a temporal proposal is a coherent and integral story. We show that our proposed framework outperforms existing approaches for the story-preserving long video truncation problem in both quantitative measures and user-study. The dataset is available for public academic research usage at https://ai.baidu.com/broad/download.
1. Introduction
诸如TikTok和Kwai之类的短视频共享平台正变得越来越流行,并导致生成短视频的需求。 用户喜欢将时间浪费在更紧凑的短片视频上,而高质量的视频(如真人秀和电视连续剧)通常很长(例如> 1小时)。 在这种情况下,开发新的算法以将长视频截断成简短,吸引人且不间断的故事是特别令人感兴趣的。
Short-form video sharing platforms such as TikTok and Kwai are becoming increasingly popular and lead to the requirement of generating short-form videos. Users prefer to consume their time in more compact short-form videos, while high quality videos such as reality show and TV series are usually long (e.g. > 1 hour). In such context, developing new algorithms that can truncate long videos into short, attractive and unbroken stories is of special interest.
尽管在视频高光检测和视频汇总方面已经取得了很大的进步[32,33,6,7,5],但其中许多都专注于在最终的组合亮点中产生连贯的整个故事,并且不需要每个子视频的故事不间断。由于现有数据集的局限性,仍然无法很好地研究保留故事的长视频截断问题。显然,在这种情况下,故事的完整性或完整性对于简短视频而言是至关重要的衡量标准,但现有视频精彩片段数据集中尚未考虑到这一点。例如,在SumMe [6]和TVSum [25]中,高潮的战斗片段很有趣,也很重要,足以成为实实在在的按键,但是作为一个单独的简短视频,它必须涉及到开始和结束部分阐明故事的因果关系。另一方面,ActivityNet [16]为动作间隔提供了准确的时间边界,但其数据分布与来自大型长视频数据库的短视频制作要求不同。如表1所示,ActivityNet的平均视频长度太短(不到2分钟),因此每个视频的平均故事数量仅为1.2,平均故事长度仅为0.8分钟
Although much progress has been made in video highlight detection and video summarization [32, 33, 6, 7, 5], many of the them focus on producing a coherent whole story in the final combined highlight and there is no requirement of an unbroken story to each sub-video. And the problem of story-preserving long video truncation is still not well studied due to the limitation of existing datasets. Obviously, story integrity or completeness is a crucial measurement for short-form videos under this scenario, but is not yet considered in existing video highlight datasets. For example, a climactic fight fragment is interesting and important enough to be a ground-truth keyshot in SumMe [6] and TVSum [25], but as an individual short-form video, it has to involve the beginning and the ending parts to clarify the cause and effect of the story. On the other hand, ActivityNet [16] provides action intervals with accurate temporal boundaries, but its data distribution is different from the requirement of short-form video production from the massive long video database. As Table 1 shows, the average video length of ActivityNet is too short (< 2 minutes) such that the average story number per video is only 1.2 and the average story length is only 0.8 minute
在本文中,我们收集了一个名为TruNet的新大型数据集,其中包含1470个视频,总计2101小时,平均视频时长超过1小时。 它涵盖了广泛的热门主题,包括综艺节目,真人秀,脱口秀和电视连续剧。 TruNet每个长视频平均提供11个短故事,并且每个故事都带有准确的时间边界。 图1(a)显示了TruNet的示例视频。 该视频是一个综艺节目,其中包含9首歌舞表演。 这9个短篇小说用不同的颜色表示,第三个故事以较高的时间分辨率显示在图1(b)中。
In this paper, we collect a new large dataset, named as TruNet, which contains 1470 videos with a total of 2101 hours and an average video length longer than 1 hour. It covers a wide range of popular topics including variety show, reality show, talk show, and TV series. TruNet provides on average 11 short stories per long video and each story is annotated with accurate temporal boundaries. Figure 1(a) shows A sample video of the TruNet. The video is a variety show that contains 9 song and dance performances. The 9 short stories are indicated in different colors, and the third one is shown in Figure 1(b) with a higher temporal resolution.
借助新的数据集,我们进一步开发了用于保留故事的长视频截断的基线神经体系结构,该体系结构包含两个组件:用于生成提案的边界感知网络(BAN)和快速转发长期短期记忆(FF- LSTM)进行故事完整性分类。 与先前的提案生成仅取决于动作性的最新技术[30]不同,BAN利用额外的帧级边界来生成提案,并在提案数量较少时实现更高的精度。 与传统的LSTM序列建模不同,FF-LSTM [39]将快进连接引入了LSTM层堆栈,以鼓励在深度循环拓扑中进行稳定且有效的反向传播,从而显着改善了视频性能 故事分类。 据我们所知,这是第一次将FF-LSTM用于视频域中的序列建模。
With the new dataset, we further develop a baseline neural architecture for story-preserving long video truncation that consists of two components: a Boundary Aware Network (BAN) for proposal generation and a Fast-Forward Long Short-Term Memory (FF-LSTM) for story integrity classification. Different from previous state-of-the-art methods [30] whose proposal generation only depends on actionness, BAN utilizes additional frame-level boundaryness to generate proposals and achieves higher precision when the number of proposals is small. And different from traditional LSTM on sequence modeling, FF-LSTM [39] introduces fast-forward connections to a stack of LSTM layers to encourage stable and effective backpropagation in the deep recurrent topology, which leads to an obvious performance improvement in our video story classification. To the best of our knowledge, this is the first time that FF-LSTM has been used for modeling sequences in the video domain.
总而言之,我们的贡献是三方面的:(1)我们在视频截断中引入了一个新的实际问题,即保留故事的长视频截断,这需要将长时间视频截断为多个简短视频,每个视频都保留一个故事。 (2)我们收集并注释了一个新的大型数据集以研究此问题,它可以成为现有视频数据集的补充资源。 (3)我们提出了一个基线框架,该框架涉及一个新的时间提议生成模块和一个新的序列建模模块,与传统方法相比,它具有更好的性能。 我们还将发布数据集以供公共学术研究使用。
In summary, our contributions are threefold: (1) We introduce a new practical problem in video truncation, story-preserving long video truncation, which requires to truncate a long-time video into multiple short-form videos with each one preserving a story. (2) We collect and annotate a new large dataset for studying this problem, which can become a complementary source to existing video datasets. (3) We propose a baseline framework that involves a new temporal proposal generation module and a new sequence modeling module, with better performance compared to traditional methods. We will also release the dataset for public academic research usage.
2. Related Work
2.1. Video Dataset
在这里,我们简要回顾与我们的工作相关的典型视频数据集。 SumMe数据集[6]由25个视频组成,涵盖3个类别。 视频的长度约为1到6分钟,提取5%到15%的帧作为视频摘要。 同样,TVSum数据集[25]包含来自10个类别的50个视频。 视频持续时间在2到10分钟之间,并且最多选择5%的帧作为关键帧。 与SueMe和TVSum相比,我们提出的TruNet数据集专注于保留故事的长视频截断问题,这样每个摘要都是具有精确时间边界的完整短格式视频。
Here we briefly review typical video datasets that are related to our work. The SumMe dataset [6] consists of 25 videos covering 3 categories. The length of the videos ranges from about 1 to 6 minutes and 5% to 15% frames are extracted to be the summary of a video. Similarly, the TVSum dataset [25] contains 50 videos from 10 categories. The video duration is between 2 to 10 minutes and at most 5% frames are selected to be the keyshots. Compared with SueMe and TVSum, our proposed TruNet dataset focuses on the story-preserving long video truncation problem such that each summary is an integral short-form video with accurate temporal boundaries.
另一方面,尽管THUMOS14 [12]和Acivityivity [16]也提供了时间边界,但它们的数据分布不适合我们的问题。 以ActivityNet为例,Activi-tyNet的平均视频长度太短,每个视频的平均操作数仅为1.2。 Ac tivityNet收集的日常活动是否适合视频共享是另一个考虑因素。 相反,我们建议的TruNet专注于收集高质量的长视频,这样每个视频的平均短故事数最多可以达到11个。TruNet中的视频主题也被选择为适合在视频共享平台中共享
On the other hand, although THUMOS14 [12] and ActivityNet [16] also provide temporal boundaries, their data distributions are not suitable for our problem. Take ActivityNet as an example, the average video length of Activi-tyNet is too short and the average action number per video is only 1.2. Whether the daily activities collected by ActivityNet are suitable for video sharing is another consideration. In contrast, our proposed TruNet focuses on collecting high-quality long videos, such that the average short story number per video can be up to 11. The video topics in TruNet are also chosen to be suitable to share in video sharing platforms
2.2. Video Summarization
视频汇总已成为计算机视觉和多媒体领域的一个长期存在的问题。 以前的研究通常将其视为提取关键帧[32、1、17、29、13、14],视频剪辑[33、31、37、6、7、20、21],情节提要[5],延时[15]。 ],蒙太奇[26]和视频摘要[22]。 详尽的审查超出了本文的范围。 我们参考[28]对视频摘要的早期作品进行调查。 与以前的方法相比,本文提出了保留故事情节的长视频截断,以不同的方式提出了视频摘要问题。 每个截断的简短视频都应该是一个引人入胜且完整的短故事,以便可以在视频共享平台中使用。
Video summarization has been a long-standing problem in computer vision and multimedia. Previous studies typically treat it as extracting keyshots [32, 1, 17, 29, 13, 14], video skims [33, 31, 37, 6, 7, 20, 21], storyboards [5], timelapses [15], montages [26], and video synopses [22]. An exhaustive review is beyond the scope of this paper. We refer [28] for a survey of early works on video summarization. Compared with previous approaches, this paper proposes story preserving long video truncation that formulates the video summarization problem in a different way. Each truncated short-form video should be an attractive and unbroken short story such that it can be used in the video sharing platforms.
2.3. Temporal Action Localization
我们的工作也与时间动作本地化有关。早期的时间动作定位方法[27,11,34]依靠手工制作的特征和滑动窗口搜索。与基于手工功能的功能相比,使用基于ConvNet的功能(例如C3D [24]和两流CNN [2、35])可实现更高的效率和更好的性能。 [3,4,30]专注于利用更强大的网络结构来生成高质量的时间建议。结构化的时间建模[38]和1d时间卷积[18]也被证明对提高临时动作定位的性能很重要。尽管在概念上相似,但我们提出的模型是新颖的,因为它通过共同考虑帧级别的吸引力和边界性来生成高质量的时间提议,这有利于截短的短视频不间断。 BSN [19]也是边界感知框架,但它是为临时动作建议而设计的,其建议是从框架级动作开始和动作结束置信度得分生成的,我们的BAN根据故事开始,故事结束来生成建议以及帧组级别的故事性得分,以适应极长的输入。
Our work is also related to the work on temporal action localization. Early methods [27, 11, 34] of temporal action location relied on hand-crafted features and sliding window search. Using ConvNet-based features such as C3D [24] and two-stream CNN [2, 35] achieves both higher efficiency and better performance than hand-crafted features. [3, 4, 30] focused on utilizing stronger network structure to generate high-quality temporal proposals. Structured temporal modeling [38] and 1d temporal convolution [18] are also proved important to boost the performance of temporal action localization. While conceptually similar, our proposed model is novel in that it generates high quality temporal proposals by jointly considering frame-level attractiveness and boundaryness, which facilitates the truncated short-form videos to be unbroken. BSN [19] is also boundary sentitive framework, but it is designed for temporal action proposal and its proposals are generated from frame-level action-start and action-end confidence score, our BAN generate proposals according to story-start, story-end as well as the storyness score at group-of-frames level to suite the extremely long input.
3. The TruNet Dataset
由于缺乏公开可用的数据集,因此没有很好地研究保留故事的长视频截断问题。 因此,我们构建了TruNet数据集以定量评估提出的框架。
The story-preserving long video truncation problem is not well studied due to the lack of publicly available dataset. Therefore, we construct the TruNet dataset to quantitatively evaluate the proposed framework.
3.1. Dataset Setup
考虑到长视频中被截短的简短故事应该适合在视频共享平台上共享,我们选择了四种类型的长视频,即综艺节目,真人秀,脱口秀和电视连续剧。 TruNet的大多数视频都是从视频网站iQIYI.com下载的,该网站上有大量高质量的长视频。然后,在收集数据之后,应用基于精心设计的注释工具的众包注释。每个注释工作者都通过注释少量视频进行培训,并且只有在他/她通过培训计划后才能参加正式注释。在注释任务中,要求工作人员1)观看整个视频; 2)注释短篇小说的时间边界; 3)调整边界。每个长视频均由多名工人进行注释,以确保质量,并且最终由多位专家对这些注释进行了审查。我们将数据集分为三部分:训练集包含1241个视频,验证集包含115个样本,测试集包含114个样本。在我们的整个实验中都没有使用验证集。
Considering the truncated short-form stories from long videos should be suitable to share in video sharing platforms, we choose four types of long videos, i.e. variety show, reality show, talk show and TV series. Most videos of the TruNet are downloaded from the video website: iQIYI.com, which has a large quantity of high quality long videos. Crowdsourced annotation based on a carefully designed annotation tool is then applied after data collection. Each annotation worker is trained by annotating a small number of videos, and can participate the formal annotation only when he/she passes the training program. During the annotation task, the worker is asked to 1) watch the whole video; 2) annotate temporal boundaries of short stories; 3) adjust the boundaries. Each long videos are annotated by multiple workers for quality assurance, and the annotations are finally reviewed by several experts. We randomly split the dataset into three parts: training set with 1241 videos, validation set with 115 samples and testing set with 114 samples. The validation set are not used throughout our experiments.
3.2. Dataset Statistics
TruNet数据集包含1470个长视频,平均持续时间为80分钟,总计2101小时。 较长的视频平均包含11个故事,人工标记的故事总数为16891。 短篇小说的平均时长为3分钟。 图2将TruNet与现有的视频摘要和时间活动本地化数据集(例如SumMe,TVSum,Activi tyNet和THUMOS14)进行了比较。 可以看出,TruNet具有最长的总视频长度和平均建议持续时间。
The TruNet dataset consists of 1470 long videos with the duration of 80 minutes on average and 2101 hours in total. A long video contains 11 stories on average, and the manually labeled story number is 16891 in total. The average duration of a short story is 3 minutes. Figure 2 compares TruNet with existing video summarization and temporal action localization dataset such as SumMe, TVSum, ActivityNet and THUMOS14. As can be seen, TruNet has the largest total video length and average proposal duration.
我们在图3中显示了TruNet数据集的一组统计数据。视频长度分布在图3(a)中显示。 每个长视频中故事编号的分布如图3(b)所示。 故事长度的分布如图3(c)所示。 故事区域长度与长视频长度之比的分布如图3(d)所示。
We show a group of statistics of the TruNet dataset in Figure 3. The video length distribution is shown in Figure 3(a). The distribution of story number in each long video is shown in Figure 3(b). The distribution of story length is shown in Figure 3©. The distribution of the ratio story region length to long video length is shown in Figure 3(d).
4. Methodology
保留故事的长视频截断问题的数学公式与时间动作本地化相似。 训练数据集可以表示为 τ = f V i = ( f u i t g T t = 1 i ; f s i ; j ; e i ; j g l j i = 1 ) g N i = 1 τ = fVi = (fui tgT t=1 i ; fsi;j; ei;jgl ji=1)gN i=1 τ=fVi=(fuitgTt=1i;fsi;j;ei;jglji=1)gNi=1 其中帧级特征 u t i u^i_t uti来自长视频 V i V_i Vi,与切成事实的简短视频集相对应。 ( s i , j , e i , j {(s {i,j},e_ {i,j}} (si,j,ei,j 是 V i V_i Vi的 j t h jth jth区间的开始和结束索引。 N是训练视频的数量, T i T_i Ti是 V i V_i Vi的帧数, l i l_i li是 V i V_i Vi的间隔数。
The mathematical formulation of the story-preserving long video truncation problem is similar with temporal action localization. The training dataset can be represented as τ = f V i = ( f u i t g T t = 1 i ; f s i ; j ; e i ; j g l j i = 1 ) g N i = 1 τ = fVi = (fui tgT t=1 i ; fsi;j; ei;jgl ji=1)gN i=1 τ=fVi=(fuitgTt=1i;fsi;j;ei;jglji=1)gNi=1 where frame-level feature u t i u^i_t uti comes from long video V i V_i Vi, which is corresponding with a ground-truth sliced short-form video set. ( s i , j , e i , j ) {(s{i,j}, e_{i,j}}) (si,j,ei,j) is the beginning and ending indexes of the j t h jth jth interval of V i V_i Vi. N is the number of training videos, T i T_i Ti is the frame number of V i V_i Vi and l i l_i li is the interval number of V i V_i Vi.
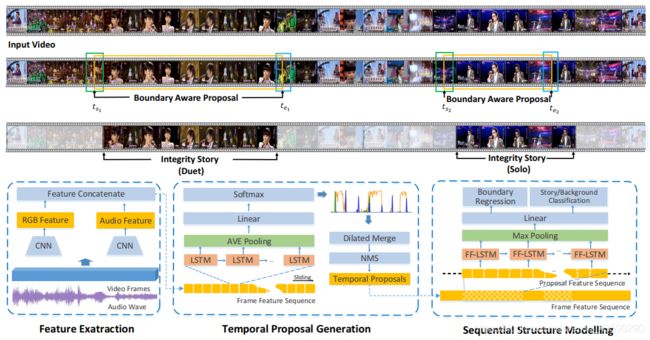
图4.所提议框架的体系结构概述,其中包含三个组件:特征提取,临时提议生成和顺序结构建模。 在第一个组件中提取并连接帧的多峰特征。 在第二部分中,边界感知网络用于预测每个帧的吸引力和边界。 然后执行膨胀的合并算法以生成提议。 在第三个组件中,每个建议的顺序结构都由FF-LSTM建模,该模型输出分类置信度分数和改进的边界。
Figure 4. An architecture overview of the proposed framework which contains three components: feature extraction, temporal proposal generation and sequential structure modeling. Multi-modal features of frames are extracted and concatenated in the first component. In the second component, a boundary aware network is used to predict attractiveness and boundaryness for each frame. A dilated merge algorithm is then carried out to generate proposals. In the third component, the sequential structure of each proposal is modeled by FF-LSTM, which outputs the classification confidence score together with the refined boundaries.
图4说明了所提出框架的体系结构,其中包括三个主要组件:特征提取,临时提议生成和顺序结构建模。 给定输入长视频,提取并连接基于RGB的2D卷积特征和音频特征。 在临时提议生成组件中,将特征输入到BAN中以预测每个帧的吸引力和边界。 然后执行膨胀的合并算法,以根据帧级别的吸引力和边界得分生成临时提议。 在顺序结构建模组件中,每个建议的顺序结构都由FF-LSTM建模,该模型输出建议的分类置信度分数以及改进的边界。
Figure 4 illustrates the architecture of the proposed framework, which includes three major components: feature extraction, temporal proposal generation and sequential structure modeling. Given an input long video, RGB-based 2D convolutional feature and audio feature are extracted and concatenated. In the temporal proposal generation component, the features are fed into the BAN to predict the attractiveness and boundaryness for each frame. A dilated merge algorithm is then carried out to generate temporal proposals according to the frame-level attractiveness and boundaryness scores. In the sequential structure modeling component, the sequential structure of each proposal is modeled by FF-LSTM, which outputs the classification confidence score of the proposal together with the refined boundaries.
4.1. Boundary Aware Network
本文提出了一种新颖的边界感知网络(BAN),以提供高质量的故事建议。 如图4所示,BAN将连续7帧的特征作为LSTM层的输入。 将LSTM的输出平均化,并使用线性层来预测四类概率分数,包括:故事内,背景,故事开始边界和故事结束边界。 中心帧的标签由得分最高的类别决定。 如果序列中的每个帧都属于故事内类别,则我们将帧序列视为故事的候选项。 实施了一种简单的扩张合并算法,以较小的距离(5帧)合并相邻的故事候选对象。 执行非最大抑制(NMS)以减少冗余并生成最终建议。
A novel boundary aware network (BAN) is proposed in this paper to provide high quality story proposals. As Figure 4 shows, BAN takes the features of consecutive 7 frames as the input of a LSTM layer. The output of the LSTM is averaged pooled and a linear layer is utilized to predict a four-categories probability scores, include: within story, background, story beginning boundary and story ending boundary. The label of the center frame is decided by the category with the largest score. We regard a frame sequence as a story candidate if every frame in the sequence belongs to the within story category. A simple dilated merge algorithm is carried out to merge adjacent story candidates with small distance (5 frames). Non-Maximal Suppression (NMS) is carried out to reduce redundancy and generate the final proposals.
与以前仅依赖于操作性来生成建议的流行方法[30、3、4、38]不同,BAN利用附加的帧级边界来生成建议。 TAG [30](上排)和拟议的BAN(中排)的动作评分之间的比较如图5所示。对于TAG,我们显示的动作评分大于0.5。 对于BAN,我们以不同的颜色显示三个前景类别中的最高分数。 真实建议间隔显示在底部行中。 可以看出,BAN的得分曲线比TAG平滑,并且边界更好地匹配了真实提议间隔。
Different from previous popular methods [30, 3, 4, 38] that only depend on actionness for proposal generation, BAN utilizes additional frame-level boundaryness to generate proposals. A comparison between the actionness score of TAG [30] (the upper row) and the proposed BAN (the middle row) is shown in Figure 5. For TAG, we show actionness scores larger than 0.5. For BAN, we show the maximum scores among the three foreground categories in different colors. The ground-truth proposal intervals are shown in the bottom row. As can be seen, the score curve of BAN is smoother than TAG, and the boundaries better match the ground-truth proposal intervals.
4.2. FF-LSTM
我们首先简要回顾一下LSTM,它是顺序结构建模的基础。 长短期记忆(LSTM)[10]是具有一组记忆单元c的递归神经网络(RNN)的增强版本。 LSTM的计算可写为
We first briefly review LSTM that serves as the basis of sequential structure modeling. Long-Short Term Memory (LSTM) [10] is an enhanced version of recurrent neural network (RNN) with a set of memory cells c. The computation of LSTM can be written as
其中 t t t是时间步长, x x x是输入, [ z i , z g , z c , z o ] [z_i,z_g,z_c,z_o] [zi,zg,zc,zo]是大小相等的四个向量的串联,h是 c 的 输 出 , b i , b g c的输出,b_i,b_g c的输出,bi,bg和 bo分别是输入门,忘记门和输出门, σ i , σ g σ_i,σ_g σi,σg和 σ o σ_o σo分别是输入激活函数,忘记激活函数和输出激活函数, W f , W h , W g W_f,W_h,W_g Wf,Wh,Wg和 W o W_o Wo是可学习的参数。 (1)的计算可以等效地分为两个连续的步骤:隐藏块 f t = W f x t f ^ t = W_f x ^ t ft=Wfxt和循环块 ( h t , c t ) = L S T M ( f t , h t − 1 , c t − 1 ) (h ^ t,c ^ t)= LSTM(f ^ t,h_ {t-1},c ^ {t-1}) (ht,ct)=LSTM(ft,ht−1,ct−1)。
where t t t is the time step, x x x is the input, [ z i , z g , z c , z o ] [z_i,z_g,z_c, z_o] [zi,zg,zc,zo] is a concatenation of four vectors of equal size, h is the output of c , b i , b g c, b_i, b_g c,bi,bg and bo are input gate, forget gate and output gate respectively, σ i , σ g σ_i, σ_g σi,σg and σ o σ_o σo are input activation function, forget activation function and output activation function respectively, W f , W h , W g W_f , W_h, W_g Wf,Wh,Wg and W o W_o Wo are learnable parameters. The computation of (1) can be equivalently split into two consecutive steps: the hidden block f t = W f x t f^t = W_f x^t ft=Wfxt and the recurrent block ( h t , c t ) = L S T M ( f t , h t − 1 , c t − 1 ) (h^t,c^t) = LSTM(f^t,h_{t−1}, c^{t−1}) (ht,ct)=LSTM(ft,ht−1,ct−1).
可以通过直接堆叠多个LSTM层来构建直接的深度LSTM。 假设LSTMk是第k个LSTM层,则:
A straightforward deep LSTM can be constructed by directly stacking multiple LSTM layers. Suppose LSTMk is the kth LSTM layer, then:
图6(b)显示了具有三个堆叠层的深LSTM。 可以看出,隐藏块的输入是循环块在其上一层的输出。 在FF-LSTM中,添加了快进连接以连接相邻层的两个隐藏块。 添加的连接建立了一条既不包含非线性激活也不包含递归计算的快速路径,从而可以轻松地传播信息或梯度。 图6(a)说明了具有三层的FF-LSTM,深FF-LSTM的计算可表示为:
Figure 6(b) illustrates a deep LSTM with three stacked layers. As can be seen, the input of the hidden block is the output of the recurrent block at its previous layer. In FF-LSTM, a fast-forward connection is added to connect two hidden blocks of adjacent layers. The added connections build a fast path that contains neither non-linear activations nor recurrent computations such that the information or gradients can be propagated easily. Figure 6(a) illustrates a FF-LSTM with three layers, and the computation of deep FF-LSTM can be expressed as:
假设多层FF-LSTM从视频 V i V_i Vi收到提案范围 { p i , s , p i , e } \{p_ {i,s},p_ {i,e} \} { pi,s,pi,e},则第一个FF-LSTM的隐藏块可以计算为 f f 1 t = W f 1 u t i + p i ; s g p t = 0 i ; e − p i ; s ff1t = Wf1ut i + pi; sgp t = 0 i; e-pi; s ff1t=Wf1uti+pi;sgpt=0i;e−pi;s。
Supposing the multi-layer FF-LSTMs receive a proposal range { p i , s , p i , e } \{p_{i,s},p_{i,e}\} { pi,s,pi,e} from video V i V_i Vi, the hidden block of the first FF-LSTM can be calculated as f f 1 t = W f 1 u t i + p i ; s g p t = 0 i ; e − p i ; s ff1t = Wf1ut i+pi;sgp t=0 i;e−pi;s ff1t=Wf1uti+pi;sgpt=0i;e−pi;s.
在最顶层的FF-LSTM上,最大池化层用于获取提案的全局表示。 基于故事/背景分类的全局表示来计算二进制分类器。 我们计算每个提议与真实情况之间的交叉相交(IoU),如果最大IoU大于0.7,则该提议被视为正样本,而负样本的IoU小于0.3。 还基于最大池化全局表示来计算边界回归器。 训练建议 p i , k = { p i , k , s , p i , k , e } p_ {i,k} = \{p_ {i,k,s},p_ {i,k,e} \} pi,k={ pi,k,s,pi,k,e} 的多任务损失可以写为:
On the topmost FF-LSTM, a max-pooling layer is used to obtain a global representation of the proposal. A binary classifier is calculated based on the global representation for story/background classification. We calculate the intersection-over-union (IoU) between each proposal and ground-truth story, and if the max IoU is larger than 0.7 the proposal is regarded as a positive sample, and a negative sample with IoU less than 0.3. A boundary regressor is also computed based on the max-pooled global representation. The multi-task loss over an training proposal p i , k = { p i , k , s , p i , k , e } p_{i,k} = \{p_{i,k,s}, p_{i,k,e}\} pi,k={ pi,k,s,pi,k,e} can be written as:
其中 c i , k c_ {i,k} ci,k是提案的标签, P ( c i ; k j p i ; k P(ci; kjpi; k P(ci;kjpi;k是多层FF-LSTM,最大池化和二进制分类器定义的分类分数。 λ是权重参数, 1 c i ; k = 1 1ci; k = 1 1ci;k=1 表示第二项仅在投标标签为1时有效。
where c i , k c_{i,k} ci,k is the label of the proposal and P ( c i ; k j p i ; k ) P(ci;kjpi;k) P(ci;kjpi;k) is the classification score defined by multi-layer FF-LSTMs, max-pooling and the binary classifier. λ is a balanced weight parameter, and 1 c i ; k = 1 1ci;k=1 1ci;k=1 means that the second term works only when the label of the proposal is 1.
5. Experiments
5.1. Implementation Details
由于数据集的大小太大而无法处理,因此我们对视频进行预处理并提取帧级特征。 我们以每秒1帧(FPS)的速度对视频进行解码,并提取两种功能:在ImageNet [23]上训练的ResNet-50 [8]的“ pool5”和卷积音频功能[9]。
Because the size of the dataset is too large to process, we pre-process the videos and extract frame-level features. We decode the videos in 1 frame-per-second (FPS) and extract two kinds of features: “pool5” of ResNet-50 [8] trained on ImageNet [23] and convolutional audio feature [9].
我们在四个K40 GPU上使用动量为0.9,历元数为70,重量衰减为0.0005,最小批量为256的随机梯度体面(SGD)训练BAN。 一个时期意味着所有训练样本均通过一次。 所有参数都是随机初始化的。 学习率设置为0.001。 我们尝试降低培训期间的学习率,但没有发现任何好处。 四个类别(在故事,背景,开始边界和结束边界内)的采样率为6:6:1:1:1。为了在时间结构建模阶段实现边界回归,我们增加了BAN生成的建议以扩展开始 和结束边界类似于[38]。
We train the BAN using Stochastic Gradient Decent (SGD) with momentum of 0.9, epoch number of 70, weight decay of 0.0005 and a mini-batch size of 256 on four K40 GPUs. One epoch means all training samples are passed through once. All parameters are randomly initialized. The learning rate is set at 0.001. We tried reducing the learning rate during training but found no benefit. The sampling ratio of the four categories (within story, background, beginning boundary and ending boundary) is 6 : 6 : 1 : 1. To enable boundary regression in the temporal structure modeling stage, we augment the BAN-generated proposals to extend the beginning and ending boundaries similar with[38].
我们使用SGD训练5层FF-LSTM,其动量为0.9,历元数为40,重量衰减为0.0008,最小批量为256。在整个训练过程中,学习率保持0.001。 正提议和负提议的比率为1:3。平衡参数λ设置为5。
We train a 5 layer FF-LSTM using SGD with momentum of 0.9, epoch number of 40, weight decay of 0.0008 and a mini-batch size of 256. The learning rate is kept 0.001 throughout the training. Positive and negative proposals are sampled with the ratio of 1 : 3. The balanced parameter λ is set at 5.
5.2. Evaluation Metrics
对于故事定位,报告了在三个不同的IoU阈值 { 0.5 , 0.7 , 0.9 } \{0.5,0.7,0.9 \} { 0.5,0.7,0.9}下,不同方法的平均平均精度(mAP)。 我们还报告了阈值[0,5:0,05:0,95]的平均mAP。 为了评估生成的临时提议的质量,我们报告了[4]中定义的平均召回率与检索到的提议的平均数量(AR-AN)曲线。
For story localization, the mean average precision (mAP) of different methods at three different IoU thresholds { 0.5 , 0.7 , 0.9 } \{0.5, 0.7, 0.9\} { 0.5,0.7,0.9} are reported. We also report the average of mAP with thresholds [0,5 : 0,05 :0,95]. For evaluating the quality of generated temporal proposals, we report the average recall vs. average number of retrieved proposals (AR-AN) curve defined in [4].
5.3. Ablation Studies
为了研究所提出的BAN的有效性,我们将其与滑动窗口搜索(SW),KTS [21]和TAG [30]进行了比较。 比较结果总结在图6中。我们可以看到,当提案数量较小时,所提议的BAN的平均召回率显着高于其他方法,但是由于其选择标准,它无法生成与其他提案一样多的提案。 注意到TAG和BAN是高度互补的,因此将它们的提案合并会获得更好的曲线。
To study the effectiveness of the proposed BAN, we compare with sliding window search (SW), KTS [21] and TAG [30]. The comparison results are summarized in Figure 6. We can see that the average recall of the proposed BAN is significantly higher than other methods when the proposal number is small, but it cannot generate as much proposals as others because of its selection standard. Noticing that TAG and BAN are highly complementary, merging their proposals obtains an substantial better curve.
表2总结了临时提案生成和顺序结构建模的消融研究结果,发现这两个组件对于最终性能至关重要。 FF-LSTM用不同的提案生成方法不断击败LSTM。 我们观察到带有训练步骤的方法(TAG和BAN)比启发式方法(滑动窗口和KTS)产生更好的建议。 使用单个BAN提案比使用单个TAG提案要好一些,但是考虑到TAG可以生成大量提案,BAN和TAG是高度互补的。 如表2所示,将它们合并会比每个单独的对象都有明显的改进。
Table 2 summarizes the ablation study results of temporal proposal generation and sequential structure modeling, emerging that both components are crucial for the final performance. FF-LSTM keeps beating LSTM with different proposal generation methods. We observe that methods with a training step (TAG and BAN) generate much better proposals than heuristic ones (sliding window and KTS). Using individual BAN proposals are slight better than using individual TAG proposals, but considering TAG can generate larger number of proposals, BAN and TAG are highly complementary. As shown in Table 2, merging them brings an obvious improvement over each individual one.
表3总结了使用不同功能的消融研究结果。 可以看出,RGB和音频功能是高度互补的,并且丢弃其中任何一个功能都会明显降低性能。 另一个有趣的现象是使用单一音频功能比使用单一RGB功能获得更好的性能。 我们猜测这是因为音频模式在视频故事边界中发生了快速变化,尤其是对于综艺节目而言。
Table 3 summarizes the ablation study results of using different features. As can be seen, the RGB and audio features are highly complementary and dropping either feature decreases the performance obviously. Another interesting phenomenon is using single audio feature achieves better performance than using single RGB feature. We guess this is because audio patterns change rapidly in video story boundaries, especially for variety programs.
表4总结了使用不同的深度递归模型进行顺序结构建模的消融研究结果。 由于收敛困难,直接堆叠多个LSTM层会导致性能下降。 相反,使用更深的FF-LSTM可获得明显的性能提升。 与1层LSTM相比,3层FF-LSTM使mAP增加3.9,而5层FF-LSTM毛刺使mAP增加0.9。 我们还尝试了5层以上的FF-LSTM,但是发现了很小的改进。
Table 4 summarizes the ablation study results of using different deep recurrent models for sequential structure modeling. Directly stacking multiple LSTM layers lead to performance drop because of convergence difficulty. Instead, using deeper FF-LSTM obtains noteworthy performance gains. A 3-layer FF-LSTM increases the mAP by 3.9 over 1-layer LSTM, and a 5-layer FF-LSTM furter increases the mAP by 0.9. We also tried more than 5-layer FF-LSTM, but found very marginal improvements.
表5总结了回归损耗的消融研究结果。 从结果可以看出,增加回归损失可使mAP提高3.0。 考虑到BAN在生成提案时已解决了故事边界问题,我们的FF-LSTM组件可以捕获帧之间的高阶依存关系,以进一步完善边界。
Table 5 summarizes the ablation study results of the regression loss. From the results, we can see that adding the regression loss improves the mAP by 3.0. Considering that BAN has addressed the story boundaries when generating proposals, our FF-LSTM component can capture high-order dependencies among frames for further boundary refinement.
5.4. Quantitative Comparison Results
我们将我们提出的框架与最新的视频摘要方法(包括vsLSTM [36]和HD-VS [33])进行比较。 我们必须重新实现vsLSTM和HD-VS以使其适合于我们的公式,因为讲故事的完整性对于保留故事的长视频截断至关重要,但以前的视频摘要论文中并未考虑。
We compare our proposed framework with state-of-the-art video summary methods, including vsLSTM [36] and HD-VS [33]. We have to re-implement vsLSTM and HD-VS to make them suitable for our formulation, because the completeness of the storytelling is essential in story-preserving long video truncation, but is not considered in previous video summary papers.
对于vsLSTM,我们使用合并的TAG和BAN提议作为vsLSTM的输入,它代替了FF-LSTM和服务器作为时间建模的回归和分类基础。 对于HD-VS,我们使用合并的TAG和BAN建议作为5层FF-LSTM的输入,并且将交叉熵损失替换为HD-VS中提出的深度排序损失。 结果总结在表6中。可以看出,在所有情况下,提出的框架在所有情况下均优于所有先前的方法。
For vsLSTM, we use the merged TAG and BAN proposals as the input of vsLSTM, which replaces the FF-LSTM and servers as the basis of temporal modeling for regression and classification. For HD-VS, we use the merged TAG and BAN proposals as the input of a 5-layer FF-LSTM, and the cross-entropy loss is replaced with a deep ranking loss proposed in HD-VS. The results are summarized in Table 6. As can be seen, the proposed framework outperforms all previous methods in all cases in a large margin.
5.5. User-Study Results
我们最终进行主观评估,以比较所生成的简短视频故事摘要的质量。 要求100名不同性别,教育背景和年龄的志愿者分别处理以下步骤:
We finally conduct subjective evaluation to compare the quality of generated short video story summary. 100 volunteers with different genders, education backgrounds and ages are required to process the following steps independently:
-
观看18个随机选择的长视频。
-
对于每个长视频,请观看由建议的框架vsLSTM [36]和HD-VS [33]生成的简短视频故事摘要。
-
对于每个长视频,请选择其中一个视频故事
总结是最好的。 -
Watch 18 randomly selected long videos.
-
For each long video, watch the short video story summaries generated by the proposed framework, vsLSTM [36] and HD-VS [33].
-
For each long video, choose one of the video story
summaries as the best one.
表7中汇总了100名志愿者的答案,并总结了这三种方法的选择比例。可以看出,所提出的框架生成的摘要获得46.4%的选票,高于vsLSTM(40.8%)和HD -VS(12.8%)。
The answers of the 100 volunteers are accumulated and the chosen ratio of the three methods are summarized in Table 7. As can be seen, the proposed framework generated summaries receive 46.4% of the votes, which is higher than vsLSTM (40.8%) and HD-VS(12.8%).
6. Conclusions
在本文中,我们提出了一个新的保留故事的视频截断问题,该问题需要使用算法将长视频截断为简短,吸引人且不间断的故事。 这个问题对于视频共享平台中的资源生产特别重要。 我们收集并注释了一个新的大型TruNet数据集,并提出了一个结合BAN和FF-LSTM的新颖框架来解决此问题。
In this paper, we propose a new story-preserving video truncation problem that requires algorithms to truncate long videos into short, attractive, and unbroken stories. This problem is particularly important for resource production in video sharing platforms. We collect and annotate a new large TruNet dataset and propose a novel framework that combines BAN and FF-LSTM is proposed to address this problem.