深度学习 机器视觉 经典卷积神经网络 Tensorflow2.0 keras.applications
前言:
最近在学习深度学习时发现各类经典网络成为高频词,比如AlexNet、VGG、GoogLeNet、Inception、Xception、ResNet、MobileNet、SENet、CBAM、DenseNet、NASNet等等。快速整理了如下内容,为大家快速了解经典网络的结构特点提供一个参考。
由于博主能力有限,内容大多引自网络博客,并未严格考证如有错误之处望予以指出,后续也会逐步修正和补充一些实现后的代码。
经典卷积神经网络
- 背景
- Keras.applications
-
- VGG16
-
- 背景 (2014)
- 网络结构
- 结果
- 讨论
- 参考
- VGG19
-
- 网络结构
- TF2.0代码复现
- 参考
- ResNet
-
- 背景(2015)
- 网络结构
- 结果
- 讨论
- TF2.0代码复现
- 参考
- InceptionV3
-
- 背景 (2015)
- 网络结构
- 结果
- 讨论
- 参考
- InceptionResNetV2
-
- 背景 (2016)
- 网络结构
- 结果
- 讨论
- TF2.0代码复现
- 参考
- Xception
-
- 背景 (2017)
- 网络结构
- 结果
- 讨论
- 参考
- MobileNet
-
- 背景(2017)
- 网络结构
- 结果
- 讨论
- [TF2.* 代码实现](https://blog.csdn.net/Forrest97/article/details/106216395)
- 参考
- DenseNet
-
- 背景(2018)
- 网络结构
- 结果
- 讨论
- TF2.0代码复现
- 参考
- NASNet
-
- 背景(2018)
- 网络结构
- 结果
- 讨论
- 参考
- MobileNetV2
-
- 背景(2019)
- 网络结构
- 结果
- 讨论
- [TF2.* 代码实现](https://blog.csdn.net/Forrest97/article/details/106223297)
- 参考
- SENet & CBAM
- 总结
- 迁移学习
-
- 使用keras.application代码实现
- 使用keras team GitHub
- 使用Tensorflow slim
背景
自2012至今近十年的深度学习发展中,机器视觉领域涌现了一大批性能突出的深度卷积神经网络结构。这些经典网络就好比我们在烹饪深度学习这道美食的不可获取的重要食材,了解并掌握不同结构的特点和基本原理,为我们活学活用卷积神经网络,快速应用于实践中,能够起到事半功倍的效果。
但由于大型神经网络规模巨大,个人电脑难以实现大规模数据集合的模型训练。Tensorflow.Keras.applications中便提供了不少基于ImageNet完成训练的经典网络模型和权值。基于大规模图像数据集训练的卷积神经网络被认为具有突出的图像特征提取的功能,被广泛应用于图像分类、语义分割、人脸识别和目标检测等实际场景中。
希望借此文,方便大家一窥经典深度卷积网络,并站在经典网络的肩膀上迅速开展自己的研究。
Keras.applications
如下,Keras官网提供了近二十组经典网络模型和权重参数。借此内容按照时间顺序展开进行介绍。

官网链接
VGG16
背景 (2014)
VGG是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG名字的由来了)在2014年提出来的模型。当这个模型被提出时,由于它的简洁性和实用性,马上成为了当时最流行的卷积神经网络模型。它在图像分类和目标检测任务中都表现出非常好的结果。
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)
网络结构


VGG16包含了16个隐藏层(13个卷积层和3个全连接层)
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling
结果

讨论
VGG优点
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好
- 验证了通过不断加深网络结构可以提升性能。
VGG缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
参考
论文:Very Deep Convolutional Networks for Large-Scale Image Recognition.
代码的github链接:https://github.com/liuzhuang13/DenseNet
参考博文: https://github.com/machrisaa/tensorflow-vgg
VGG19
网络结构

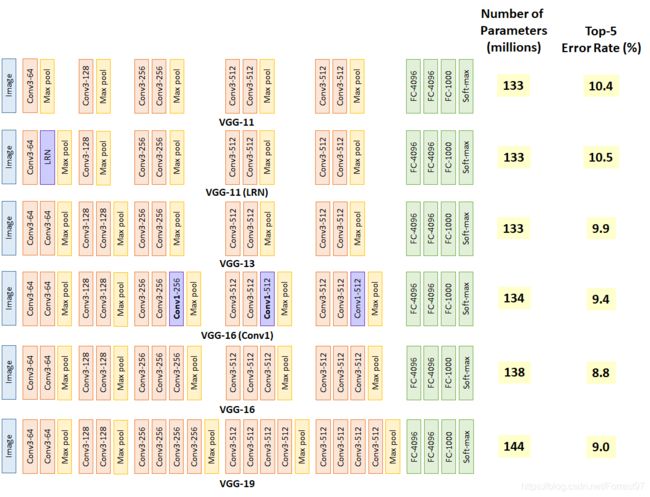
VGG19包含了19个隐藏层(16个卷积层和3个全连接层)
TF2.0代码复现
https://blog.csdn.net/Forrest97/article/details/106135431
参考
论文:Very Deep Convolutional Networks for Large-Scale Image Recognition.
参考博文: https://github.com/machrisaa/tensorflow-vgg
ResNet
背景(2015)
深度卷积网络在图像分类任务上取得了一系列突破。深度网络通过多层端到端的方式,集成了低中高三个层次的特征和分类器,并且这些特征的数量还可以通过堆叠层数来增加。在ImageNet数据集上获胜的网络揭示了网络深度的重要性。
随着网络层数的增加,训练的问题随之凸显。比较显著的问题有梯度消失/爆炸,这会在一开始就影响收敛。收敛的问题可以通过正则化来得到部分的解决。
在深层网络能够收敛的前提下,随着网络深度的增加,正确率开始饱和甚至下降,称之为网络的退化(degradation)问题。 示例可见Figure 1. 显然,56层的网络相对于20层的网络,不管是训练误差还是测试误差都显著增大。

很明显,这些退化并不是过拟合造成的。在给定的网络上增加层数会增大训练误差。 网络的退化说明不是所有的系统都很容易优化。考虑一个浅层的网络架构和在它基础上构建的深层网络,在极端条件下,如果增加的所有层都是前一层的直接复制(即y=x),这种情况下深层网络的训练误差应该和浅层网络相等。因此,网络退化的根本原因还是优化问题。 为了解决优化的难题,提出了残差网络。
网络结构
ResNet 通过在卷积层的输入和输出之间添加Skip Connection 实现层数回退机制,如下
图 所示,输入通过两个卷积层,得到特征变换后的输出ℱ(),与输入进行对应元
素的相加运算,得到最终输出
ℋ() = + ℱ()
ℋ()叫做残差模块(Residual Block,ResBlock)。由于被Skip Connection 包围的卷积神经网络需要学习映射ℱ() = ℋ() − ,故称为残差网络。

为了能够满足输入与卷积层的输出ℱ()能够相加运算,需要输入的shape 与ℱ()的shape 完全一致。当出现shape 不一致时,一般通过在Skip Connection 上添加额外的卷积运算环节将输入变换到与ℱ()相同的shape,如图 10.63 中identity()函数所示,其中identity()以1x1 的卷积运算居多,主要用于调整输入的通道数。
下图 对比了34 层的深度残差网络、34 层的普通深度网络以及19 层的VGG 网络结构。可以看到,深度残差网络通过堆叠残差模块,达到了较深的网络层数,从而获得
了训练稳定、性能优越的深层网络。


结果
分别使用18层的plain nets和34层的plain nets,结果显示34层的网络有更高的验证误差。下图比较了整个过程的训练和测试误差:

注:细实线代表训练误差,粗实线代表验证误差。左侧为plain nets,右侧为ResNet。 这种优化上的困难不是由于梯度消失造成的,因为在网络中已经使用了BN,保证了前向传播的信号有非零的方差。猜想深层的神经网络的收敛几率随着网络层数的加深,以指数的形式下降,导致训练误差很难降低
测试18层和34层的ResNet。注意到34层的训练和测试误差都要比18层的小。这说明网络退化的问题得到了部分解决,通过加深网络深度,可以提高正确率。注意到18层的plain net和18层的ResNet可以达到相近的正确率,但是ResNet收敛更快。这说明网络不够深的时候,SGD还是能够找到很好的解。
Identity vs. Projection Shortcuts
比较了三种选择:
(A)zero-padding shortcuts用来增加维度(Residual block的维度小于输出维度时,使用0来进行填充),所有的shortcut无参数。
(B)projection shortcuts用来增加维度(维度不一致时使用),其他的shortcut都是恒等映射(identity)类型。
(C)所有的shortcut都是使用projection shortcuts。

结果表明,这三种选择都有助于提高正确率。其中,B比A效果好,原因可能是A中zero-padded的维度没有使用残差学习。C比B效果好,原因可能是projection shortcuts中引入的参数。但是ABC中的结果表明,projection shortcuts对于解决网络的退化问题是没有作用的,对于正确率的提升作用也十分有限。所以,从减少模型参数,降低复杂度的角度考虑,使用Identity shortcuts就已经足够了。
Deeper Bottleneck Architectures.
在探究更深层网络性能的时候,处于训练时间的考虑,我们使用bottleneck design的方式来设计building block。对于每一个残差函数FF,使用一个三层的stack代替以前的两层。这三层分别使用1×1, 3×3, 和 1×1的卷积。其中,1×1卷积用来降维然后升维,即利用1×1卷积解决维度不同的问题。3×3对应一个瓶颈(更少的输入、输出维度)。Fig.5 展示了这种设计。

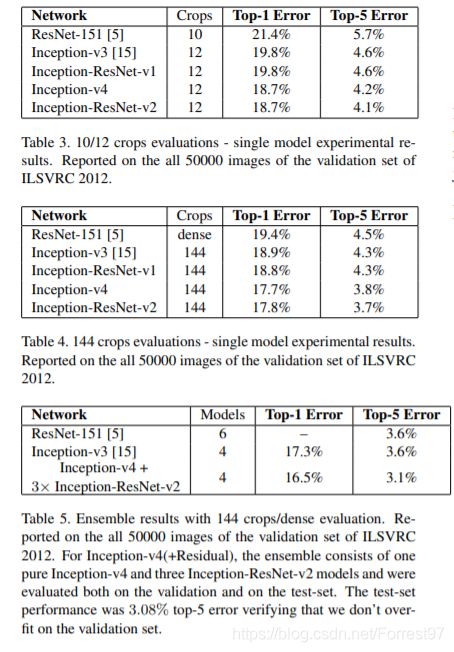
50、101和152层的ResNet相对于32层网络有更高的准确率。Table3和4中给出了测试结果。

讨论
ResNet和Highway Network的思路比较类似,都是将部分原始输入的信息不经过矩阵乘法和非线性变换,直接传输到下一层。这就如同在深层网络中建立了许多条信息高速公路。ResNet通过改变学习目标,即不再学习完整的输出F(x),而是学习残差H(x)−x,解决了传统卷积层或全连接层在进行信息传递时存在的丢失、损耗等问题。通过直接将信息从输入绕道传输到输出,一定程度上保护了信息的完整性。同时,由于学习的目标是残差,简化了学习的难度。根据Schmidhuber教授的观点,ResNet类似于一个没有gates的LSTM网络,即旁路输入x一直向之后的层传递,而不需要学习。有论文表示,ResNet的效果类似于对不同层数网络进行集成方法。
TF2.0代码复现
https://blog.csdn.net/Forrest97/article/details/106136435
参考
论文:Deep Residual Learning for Image Recognition.
参考博文: https://blog.csdn.net/csdnldp/article/details/78313087
何恺明主页:http://kaiminghe.com/
InceptionV3
背景 (2015)
GoogLeNet
在Going deeper with convolutions论文中,作者提出一种深度卷积神经网络 Inception,它在 ILSVRC14 中达到了当时最好的分类和检测性能。该架构的主要特点是更好地利用网络内部的计算资源,这通过一个精心制作的设计来实现,该设计允许增加网络的深度和宽度,同时保持计算预算不变。为了优化质量,架构决策基于赫布原则和多尺度处理。作者向 ILSVRC14 提交使用该架构的模型即 GoogLeNet,这是一个 22 层的深度网络,它的质量是在分类和检测领域进行了评估。
为什么不在同一层级上运行具备多个尺寸的滤波器呢?网络本质上会变得稍微「宽一些」,而不是「更深」。作者因此设计了 Inception 模块。
下图是「原始」Inception 模块。它使用 3 个不同大小的滤波器(1x1、3x3、5x5)对输入执行卷积操作,此外它还会执行最大池化。所有子层的输出最后会被级联起来,并传送至下一个 Inception 模块。

如前所述,深度神经网络需要耗费大量计算资源。为了降低算力成本,作者在 3x3 和 5x5 卷积层之前添加额外的 1x1 卷积层,来限制输入信道的数量。尽管添加额外的卷积操作似乎是反直觉的,但是 1x1 卷积比 5x5 卷积要廉价很多,而且输入信道数量减少也有利于降低算力成本。不过一定要注意,1x1 卷积是在最大池化层之后,而不是之前。

GoogLeNet 有 9 个线性堆叠的 Inception 模块。它有 22 层(包括池化层的话是 27 层)。该模型在最后一个 inception 模块处使用全局平均池化。和所有深层网络一样,它也会遇到梯度消失问题。为了阻止该网络中间部分梯度的「消失」过程,作者引入了两个辅助分类器(上图紫色框)。它们对其中两个 Inception 模块的输出执行 softmax 操作,然后在同样的标签上计算辅助损失。总损失即辅助损失和真实损失的加权和。该论文中对每个辅助损失使用的权重值是 0.3。
The total loss used by the inception net during training.total_loss = real_loss + 0.3 * aux_loss_1 + 0.3 * aux_loss_2
辅助损失只是用于训练,在推断过程中并不使用。
Inception v2 和 Inception v3 来自同一篇2015年论文《Rethinking the Inception Architecture for Computer Vision》,作者提出了一系列能增加准确度和减少计算复杂度的修正方法。
问题:
- 减少特征的表征性瓶颈。直观上来说,当卷积不会大幅度改变输入维度时,神经网络可能会执行地更好。过多地减少维度可能会造成信息的损失,这也称为「表征性瓶颈」。
- 使用更优秀的因子分解方法,卷积才能在计算复杂度上更加高效。
网络结构
将 5×5 的卷积分解为两个 3×3 的卷积运算以提升计算速度。尽管这有点违反直觉,但一个 5×5 的卷积在计算成本上是一个 3×3 卷积的 2.78 倍。所以叠加两个 3×3 卷积实际上在性能上会有所提升,如下图所示:

最左侧前一版 Inception 模块中的 5×5 卷积变成了两个 3×3 卷积的堆叠。
此外,作者将 n*n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。他们还发现这种方法在成本上要比单个 3×3 的卷积降低 33%,这一结构如下图所示:

此处如果 n=3,则与上一张图像一致。最左侧的 5x5 卷积可被表示为两个 3x3 卷积,它们又可以被表示为 1x3 和 3x1 卷积。
模块中的滤波器组被扩展(即变得更宽而不是更深),以解决表征性瓶颈。如果该模块没有被拓展宽度,而是变得更深,那么维度会过多减少,造成信息损失。如下图所示:

使 Inception 模块变得更宽。这种类型等同于前面展示的模块
前面三个原则用来构建三种不同类型的 Inception 模块(这里我们按引入顺序称之为模块 A、B、C,这里使用「A、B、C」作为名称只是为了清晰期间,并不是它们的正式名称)。架构如下所示:

这里「figure 5」是模块 A,「figure 6」是模块 B,「figure 7」是模块 C
结果



讨论
Inception v2问题:
- 作者注意到辅助分类器直到训练过程快结束时才有较多贡献,那时准确率接近饱和。作者认为辅助分类器的功能是正则化,尤其是它们具备 BatchNorm 或 Dropout 操作时。
- 是否能够改进 Inception v2 而无需大幅更改模块仍需要调查。
Inception v3解决方案:
Inception v3 整合了前面 Inception v2 中提到的所有升级,还使用了:
- RMSProp 优化器;
- Factorized 7x7 卷积;
- 辅助分类器使用了 BatchNorm;
- 标签平滑(添加到损失公式的一种正则化项,旨在阻止网络对某一类别过分自信,即阻止过拟合)。
参考
论文:Rethinking the Inception Architecture for Computer Vision.
代码的github链接:
参考博文: https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
https://baijiahao.baidu.com/s?id=1601882944953788623&wfr=spider&for=pc
InceptionResNetV2
背景 (2016)
Inception 架构可以用很低的计算成本达到很高的性能。而在传统的网络架构中引入残差连接曾在 2015ILSVRC 挑战赛中获得当前最佳结果,其结果和 Inception-v3 网络当时的最新版本相近。这使得人们好奇,如果将 Inception 架构和残差连接结合起来会是什么效果。在这篇论文中,研究者通过实验明确地证实了,结合残差连接可以显著加速 Inception 的训练。也有一些证据表明残差 Inception 网络在相近的成本下略微超过没有残差连接的 Inception 网络。研究者还展示了多种新型残差和非残差 Inception 网络的简化架构。这些变体显著提高了在 ILSVRC2012 分类任务挑战赛上的单帧识别性能。作者进一步展示了适当的激活值缩放如何稳定非常宽的残差 Inception 网络的训练过程。通过三个残差和一个 Inception v4 的模型集成,作者在 ImageNet 分类挑战赛的测试集上取得了 3.08% 的 top-5 误差率。
网络结构
引入残差连接,它将 inception 模块的卷积运算输出添加到输入上。
为了使残差加运算可行,卷积之后的输入和输出必须有相同的维度。因此,我们在初始卷积之后使用 1x1 卷积来匹配深度(深度在卷积之后会增加)。

(左起)Inception ResNet 中的 Inception 模块 A、B、C。注意池化层被残差连接所替代,并在残差加运算之前有额外的 1x1 卷积


结果
讨论
受 ResNet 的优越性能启发,研究者提出了一种混合 inception 模块。Inception ResNet 有两个子版本:v1 和 v2。在我们分析其显著特征之前,先看看这两个子版本之间的微小差异。
Inception-ResNet v1 的计算成本和 Inception v3 的接近。
Inception-ResNetv2 的计算成本和 Inception v4 的接近。
它们有不同的 stem,正如 Inception v4 部分所展示的。
两个子版本都有相同的模块 A、B、C 和缩减块结构。唯一的不同在于超参数设置。在这一部分,我们将聚焦于结构,并参考论文中的相同超参数设置(图像是关于 Inception-ResNet v1 的)。
TF2.0代码复现
https://blog.csdn.net/Forrest97/article/details/106150730
参考
论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning.
参考博文: https://medium.com/@mannasiladittya/building-inception-resnet-v2-in-keras-from-scratch-a3546c4d93f0
Xception
背景 (2017)
2017年,Xception是google继Inception后提出的对Inception v3的另一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的卷积操作。
当时提出Inception的初衷可以认为是:特征的提取和传递可以通过11卷积,33卷积,5*5卷积,pooling等,到底哪种才是最好的提取特征方式呢?Inception结构将这个疑问留给网络自己训练,也就是将一个输入同时输给这几种提取特征方式,然后做concat。
在 Inception 中,特征可以通过 1×1 卷积,3×3 卷积,5×5 卷积,pooling 等进行提取,Inception 结构将特征类型的选择留给网络自己训练,也就是将一个输入同时输给几种提取特征方式,然后做 concat 。Inception-v3的结构图如下:

对 Inception-v3 进行简化,去除 Inception-v3 中的 avg pool 后,输入的下一步操作就都是 1×1 卷积

提取 1×1 卷积的公共部分

网络结构
关键点
- Xception(An “extreme” version of Inception module,极致的 Inception):先进行普通卷积操作,再对 1×1 卷积后的每个channel分别进行 3×3 卷积操作,最后将结果 concat:

- Depthwise Separable Convolution,深度可分离卷积
Depthwise Separable Convolution 与 极致的 Inception 区别:
极致的 Inception:
第一步:普通 1×1 卷积。
第二步:对 1×1 卷积结果的每个 channel,分别进行 3×3 卷积操作,并将结果 concat。
Depthwise Separable Convolution:
第一步:Depthwise 卷积,对输入的每个channel,分别进行 3×3 卷积操作,并将结果 concat。
第二步:Pointwise 卷积,对 Depthwise 卷积中的 concat 结果,进行 1×1 卷积操作。
两种操作的循序不一致:Inception 先进行 1×1 卷积,再进行 3×3 卷积;Depthwise Separable Convolution 先进行 3×3 卷积,再进行 1×1 卷积。(作者认为这个差异并没有大的影响)
Xception 的结构基于 ResNet,但是将其中的卷积层换成了Separable Convolution(极致的 Inception模块)。如下图所示。整个网络被分为了三个部分:Entry,Middle和Exit。

结果

Xception 在 ImageNet 上,比 Inception-v3 的准确率稍高, 同时参数量有所下降,在 Xception 中加入的类似 ResNet 的残差连接机制也显著加快了Xception的收敛过程并获得了显著更高的准确率。

讨论
Xception作为Inception v3的改进,主要是在Inception v3的基础上引入了depthwise separable convolution,在基本不增加网络复杂度的前提下提高了模型的效果。depthwise separable convolution没有大大降低网络的复杂度,因为depthwise separable convolution在mobileNet中主要就是为了降低网络的复杂度而设计的。原因是作者加宽了网络,使得参数数量和Inception v3差不多,然后在这前提下比较性能。因此Xception目的不在于模型压缩,而是提高性能。
潜在的问题:虽然 Depthwise Separable Convolution 可以带来准确率的提升或是理论计算量的大幅下降,但由于其计算过程较为零散,现有的卷积神经网络实现中它的效率都不够高,例如本文中 Xception 的理论计算量是远小于Inception-v3的,但其训练时的迭代速度反而更慢一些。
参考
论文:Xception: Deep Learning with Depthwise Separable Convolutions.
代码的github链接:https://github.com/liuzhuang13/DenseNet
参考博文: https://blog.csdn.net/lk3030/article/details/84847879
https://blog.csdn.net/u014380165/article/details/75142710
MobileNet
背景(2017)
深度卷积神经网络将多个计算机视觉任务性能提升到了一个新高度,总体的趋势是为了达到更高的准确性构建了更深更复杂的网络,但是这些网络在尺度和速度上不一定满足移动设备要求。MobileNet描述了一个高效的网络架构,允许通过两个超参数直接构建非常小、低延迟、易满足嵌入式设备要求的模型。

建立小型高效的神经网络的方法:
压缩预训练模型获得小型网络的一个办法是减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;还有一种训练小型网络的方法叫蒸馏(distillation ),使用大型网络指导小型网络,这是对论文的方法做了一个补充,后续有介绍补充。
直接训练小型模型 例如Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到Inception V3 networks;Squeezenet 使用一个bottleneck用于构建小型网络。
本文提出的MobileNet网络架构,允许模型开发人员专门选择与其资源限制(延迟、大小)匹配的小型模型,MobileNets主要注重于优化延迟同时考虑小型网络,从深度可分离卷积的角度重新构建模型。
MobileNets是为移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions)来构建轻量级深度神经网络。
网络结构
传统卷积的实现过程:



Depthwise Separable Convolution 的实现过程:


depthwise separable convolution就是先用M个33卷积核一对一卷积输入的M个feature map,不求和,生成M个结果;然后用N个11的卷积核正常卷积前面生成的M个结果,求和,最后生成N个结果

例子:输入图片的大小为(6,6,3),卷积操作(4,4,3,5).
标准卷积和MobileNet中使用的深度分离卷积结构对比如下:

MobileNet的具体结构如下(dw表示深度分离卷积):
两个控制模型大小的超参数:
宽度因子α\alphaα(Width multiplier ):用于控制输入和输出的通道数,即输入通道从M变为αM,输出通道从N变为αN。

分辨率因子ρ\rhoρ(resolution multiplier ):.用于控制输入和内部层表示。即用分辨率因子控制输入的分辨率

结果
ImageNet
表6显示宽度因子对模型参数量、计算量精度的影响,表7显示分辨率因子对模型参数量、计算量精度的影响

表8将完整的MobileNet与原始的GoogleNet和VGG16对比,MobileNet与VGG16有相似的精度,参数量和计算量减少了2个数量级。

Face Attributes
MobileNet的框架技术可用于压缩大型模型,在Face Attributes任务中,我们验证了MobileNet的蒸馏(distillation )技术的关系,蒸馏的核心是让小模型去模拟大模型,而不是直接逼近Ground Label:

将蒸馏技术的可扩展性和MobileNet技术的精简性结合到一起,最终系统不仅不需要正则技术(例如权重衰减和退火等),而且表现出更强的性能。
Object Detection
基于MobileNet改进的检测模型对比如下:

讨论
一种基于深度可分离卷积的新模型MobileNet,同时提出了两个超参数用于快速调节模型适配到特定环境。实验部分将MobileNet与许多先进模型做对比,展现出MobileNet的在尺寸、计算量、速度上的优越性。
TF2.* 代码实现
https://blog.csdn.net/Forrest97/article/details/106216395
参考
论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.
代码的github链接:https://github.com/tensorflow/models/tree/master/research/slim/nets
参考博文: https://blog.csdn.net/u011974639/article/details/79199306
DenseNet
背景(2018)
这篇文章是CVPR2017的oral,非常厉害。文章提出的DenseNet(Dense Convolutional Network)主要还是和ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效!最近一两年卷积神经网络提高效果的方向,要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception),而作者则是从feature入手,通过对feature的极致利用达到更好的效果和更少的参数。
网络结构


如果你有L层,那么就会有L个连接,但是在DenseNet中,会有L(L+1)/2个连接。简单讲,就是每一层的输入来自前面所有层的输出
文章中只有两个公式,是用来阐述DenseNet和ResNet的关系,对于从原理上理解这两个网络还是非常重要的。
第一个公式是ResNet的。这里的l表示层,xl表示l层的输出,Hl表示一个非线性变换。所以对于ResNet而言,l层的输出是l-1层的输出加上对l-1层输出的非线性变换
![]()
第二个公式是DenseNet的。[x0,x1,…,xl-1]表示将0到l-1层的输出feature map做concatenation。concatenation是做通道的合并,就像Inception那样。而前面resnet是做值的相加,通道数是不变的。Hl包括BN,ReLU和3*3的卷积。
![]()

结果

DenseNet-BC的网络参数和相同深度的DenseNet相比确实减少了很多!参数减少除了可以节省内存,还能减少过拟合。这里对于SVHN数据集,DenseNet-BC的结果并没有DenseNet(k=24)的效果好,作者认为原因主要是SVHN这个数据集相对简单,更深的模型容易过拟合。在表格的倒数第二个区域的三个不同深度L和k的DenseNet的对比可以看出随着L和k的增加,模型的效果是更好的。

Figure3是DenseNet-BC和ResNet在Imagenet数据集上的对比,左边那个图是参数复杂度和错误率的对比,你可以在相同错误率下看参数复杂度,也可以在相同参数复杂度下看错误率,提升还是很明显的!右边是flops(可以理解为计算复杂度)和错误率的对比,同样有效果。

Figure4也很重要。左边的图表示不同类型DenseNet的参数和error对比。中间的图表示DenseNet-BC和ResNet在参数和error的对比,相同error下,DenseNet-BC的参数复杂度要小很多。右边的图也是表达DenseNet-BC-100只需要很少的参数就能达到和ResNet-1001相同的结果
讨论
该文章提出的DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Translation layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。DenseNet优点很多,而且在和ResNet的对比中优势还是非常明显的。
DenseNet的几个优点:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上较少了参数数量
TF2.0代码复现
https://blog.csdn.net/Forrest97/article/details/106159896
参考
论文:Densely Connected Convolutional Networks.
代码的github链接:https://github.com/liuzhuang13/DenseNet
参考博文: https://blog.csdn.net/u014380165/article/details/75142664
NASNet
背景(2018)
此论文是一开始发表于ICLR2017,后来转投与CVPR2017,又是Google Brain的一篇著作。这个模型并非是人为设计出来的,而是通过谷歌很早之前推出的AutoML自动训练出来的。该项目目的是实现“自动化的机器学习”,即训练机器学习的软件来打造机器学习的软件,自行开发新系统的代码层,它也是一种神经架构搜索技术(Neural Architecture Search technology)。机器在小数据集(CIFAR-10数据集)上自动设计出CNN网络,并利用迁移学习技术使得设计的网络能够被很好的迁移到大数据集(ImageNet数据集),同时也可以迁移到其他的计算机视觉任务上(如目标检测)。
网络结构
基于AutoML首先在CIFAR-10这种数据集上进行神经网络架构搜索,以便 AutoML 找到最佳层并灵活进行多次堆叠来创建最终网络,并将学到的最好架构转移到 ImageNet 图像分类和 COCO 对象检测中。其中NasNet的组成由两种网络单元组合而成

针对不同的分类数据集,将Normal Cell 和 Reduction Cell进行堆叠

结果

在 ImageNet 图像分类上,NASNet 在验证集上的预测准确率达到了 82.7%,超过了之前构建的所有 Inception 模型 。此外,NASNet 的准确率比之前公布的所有结果提升了 1.2%。NASNet 还可以调整规模,生成一系列可以实现较高准确率的模型,同时将计算开销控制在非常低的水平。例如,小版本的 NASNet 可以实现 74% 的准确率,比面向移动平台的同等规模最先进模型提升了 3.1%。大型 NASNet 则可实现最高的准确率,同时将 arxiv.org 上最佳报告结果(即 SENet)的计算开销减半 。
讨论
论文贡献:
(1)设计了新的搜索空间,即NASNet search space,并在实验中搜索得到最优的网络结构NASNet
(2)提出新的正则化技术,ScheduledDropPath,是DropPath方法的改进版,可以大大提高了模型的泛化能力。
DropPath方法在训练过程中以随机概率p进行drop,该概率训练中保持不变。而ScheduledDropPath方法在训练过程线性的提高随机概率p。
文章类似resnet和inception一样,进行基本block的堆叠生成最终网络。因此搜索最优网络的时候,只搜索最优block。这样的好处,
(1)可以极大的加快搜索速度
(2)基础block对其他分类,检测问题都具有很好的泛化能力
参考
论文:Learning Transferable Architectures for Scalable Image Recognition
代码的github链接:https://github.com/tensorflow/models/tree/master/research/slim/nets/nasnet
参考博文:
https://blog.csdn.net/qq_14845119/article/details/83050862
学习过程解读
https://blog.csdn.net/xjz18298268521/article/details/79079008
MobileNetV2
背景(2019)
1、结构问题:
MobileNet V1 的结构其实非常简单,论文里是一个非常复古的直筒结构,类似于VGG一样。这种结构的性价比其实不高,后续一系列的 ResNet, DenseNet 等结构已经证明通过复用图像特征,使用 Concat/Eltwise+ 等操作进行融合,能极大提升网络的性价比。
2、Depthwise Convolution的潜在问题:
Depthwise Conv确实是大大降低了计算量,而且N×N Depthwise +1×1PointWise的结构在性能上也能接近N×N Conv。在实际使用的时候,我们发现Depthwise部分的kernel比较容易训废掉:训练完之后发现Depthwise训出来的kernel有不少是空的。当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim, 加上ReLU的激活影响下,使得神经元输出很容易变为0,所以就学废了。ReLU对于0的输出的梯度为0,所以一旦陷入0输出,就没法恢复了。我们还发现,这个问题在定点化低精度训练的时候会进一步放大。
1、Inverted Residual Block
MobileNet V1没有很好的利用Residual Connection,而Residual Connection通常情况下总是好的,所以MobileNet V2加上。先看看原始的ResNet Block长什么样,下图左边:
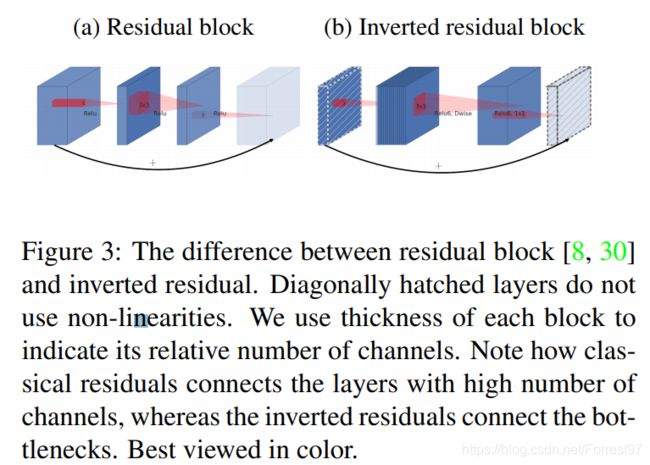
先用1x1降通道过ReLU,再3x3空间卷积过ReLU,再用1x1卷积过ReLU恢复通道,并和输入相加。之所以要1x1卷积降通道,是为了减少计算量,不然中间的3x3空间卷积计算量太大。所以Residual block是沙漏形,两边宽中间窄。
但是,现在我们中间的3x3卷积变为了Depthwise的了,计算量很少了,所以通道可以多一点,效果更好,所以通过1x1卷积先提升通道数,再Depthwise的3x3空间卷积,再用1x1卷积降低维度。两端的通道数都很小,所以1x1卷积升通道或降通道计算量都并不大,而中间通道数虽然多,但是Depthwise 的卷积计算量也不大。作者称之为Inverted Residual Block,两边窄中间宽,像柳叶,较小的计算量得到较好的性能。
2、ReLU6
首先说明一下 ReLU6,卷积之后通常会接一个 ReLU 非线性激活,在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率,如果对 ReLU 的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
本文提出,最后输出的 ReLU6 去掉,直接线性输出,理由是:ReLU 变换后保留非0区域对应于一个线性变换,仅当输入低维时ReLU 能保留所有完整信息。
在看 MobileNet V1的时候,我就疑问为什么没有把后面的 ReLU去掉,因为Xception已经实验证明了 Depthwise 卷积后再加ReLU 效果会变差,作者猜想可能是 Depthwise 输出太浅了, 应用 ReLU会带来信息丢失,而 MobileNet V1还引用了 Xception 的论文,但是在 Depthwise 卷积后面还是加了ReLU。在 MobileNet V2 这个 ReLU终于去掉了,并用了大量的篇幅来说明为什么要去掉。
总之,去掉最后那个 ReLU,效果更好。
网络结构

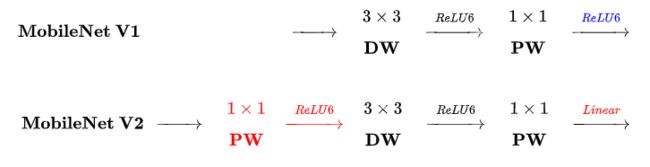
不同点:Linear Bottleneck
V2 在 DW 卷积之前新加了一个 PW 卷积。这么做的原因,是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数,这样不管输入通道数 [公式] 是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维 进行着辛勤工作的。
V2 去掉了第二个 PW 的激活函数。论文作者称其为 Linear Bottleneck。这么 做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个 PW 的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用 ReLU6 了。

ResNet 使用 标准卷积 提特征,MobileNet 始终使用 DW卷积 提特征。
ResNet 先降维 (0.25倍)、卷积、再升维,而 MobileNet V2 则是 先升维 (6倍)、卷积、再降维。直观的形象上来看,ResNet 的微结构是沙漏形,而 MobileNet V2 则是纺锤形,刚好相反。因此论文作者将 MobileNet V2 的结构称为 Inverted Residual Block。这么做也是因为使用DW卷积而作的适配,希望特征提取能够在高维进行。
结果
通过 Inverted residual block这个新的结构,可以用较少的运算量得到较高的精度,适用于移动端的需求,在 ImageNet 上的准确率如下所示:
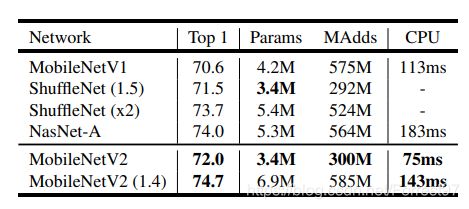
可以说是又小又快又好。另外,应用在目标检测任务上,也能得到很好的效果。
应用在目标检测任务上,基于 MobileNet V2的SSDLite 在 COCO 数据集上超过了 YOLO v2,并且大小小10倍速度快20倍:
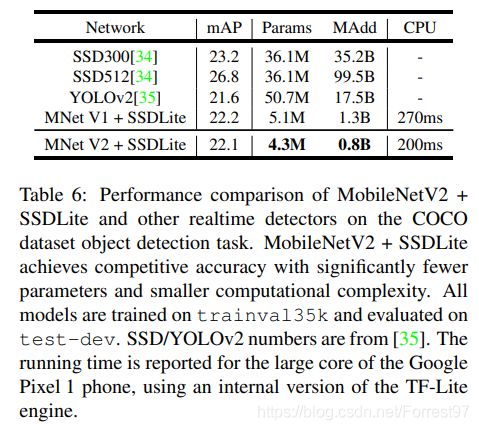
讨论
1、CNN 在 CV 领域不断突破,但是深度模型前端化还远远不够。目前 MobileNet、ShuffleNet参数个位数(单位 M ),在ImageNet 数据集上,依 top-1 而论,比 ResNet-34,VGG19 精度高,比 ResNet-50 精度低。实时性和精度得到较好的平衡。
2、本文最难理解的其实是 Linear Bottlenecks,论文中用了很多公式来描述这个思想,但是实现上非常简单,就是在 MobileNet V2 微结构中第二个PW后去掉 ReLU6。对于低维空间而言,进行线性映射会保存特征,而非线性映射会破坏特征。
TF2.* 代码实现
https://blog.csdn.net/Forrest97/article/details/106223297
参考
论文:MobileNetV2: Inverted Residuals and Linear Bottlenecks.
代码的github链接:https://github.com/shicai/MobileNet-Caffe
参考博文: https://blog.csdn.net/kangdi7547/article/details/81431572
https://zhuanlan.zhihu.com/p/33075914
SENet & CBAM
模型介绍
SENet TF2.*代码实现
CBAM TF2.*代码实现
总结
打个比方,经典卷积神经网络好比一条从输入”图像“(原材料)到输出”特征“(产品)的加工流水线,目标就是提炼出高纯度的加工产品。总结以下不同生成线的关键特征:
| 网络名称 | 发布年份 | 重要突破 | 类比 |
|---|---|---|---|
| VGG | 2014 | 相同大小卷积核尺寸(3x3)和最大池化尺寸(2x2);加深网络结构可以提升性能但很快达到上限 | 最优的标准化工艺反复提炼 |
| ResNet | 2015 | 卷积层的输入和输出之间添加Skip Connection 实现层数回退机制(深) | 因材施施工、区间快车道 |
| Inception系列 | 2015 | 多组不同Size Filter 并行处理(宽),引入 BatchNorm | 分流操作,增加加工工艺 |
| InceptionResNet | 2016 | Inception 架构和残差连接结合 | 双管齐下 |
| Xception | 2017 | “extreme” version of Inception module:卷积操作, 1×1 卷积后的每个channel分别 3×3 卷积 concat | 发挥极致 |
| MobileNet | 2017 | 深度可分离卷积(depthwise separable convolutions) | 精简流程,追求效率 |
| DenseNet | 2018 | 第 l层特征由0到l-1层的输出feature map做concatenation | 融会贯通,洲际高速 |
| NASNet | 2018 | 神经架构搜索技术(Neural Architecture Search technology) | 自动化优化流程 |
| MobileNetV2 | 2019 | Inverted Residuals and Linear Bottlenecks | 引入残差,模块优化 |
迁移学习
使用keras.application代码实现
环境tensorflow 2.*
import tensorflow as tf
from tensorflow import keras
# 加载DenseNet网络模型,并去掉最后一层全连接层,最后一个池化层设置为max pooling
base_model = keras.applications.DenseNet121(weights='imagenet', include_top=False, pooling='max')
# 设计为不参与优化
base_model.trainable = False
newnet = keras.Sequential([
base_model, # 去掉最后一层的DenseNet121
layers.Dense(1024, activation='relu'), # 追加全连接层
layers.BatchNormalization(), # 追加BN层
layers.Dropout(rate=0.5), # 追加Dropout层,防止过拟合
layers.Dense(10) # 根据任务设置最后一层输出节点数
])
newnet.build(input_shape=(4,224,224,3))
newnet.summary()
使用keras team GitHub
https://github.com/fchollet/deep-learning-models/releases/
https://github.com/keras-team/keras-applications/releases

import tensorflow as tf
WEIGHTS_PATH = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5'
weights_path = tf.keras.utils.get_file('vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5',
WEIGHTS_PATH,
cache_subdir='models') #.keras/models
也可直接点击下载需要的版本,响应修改一下路径即可
model.load_weights(weights_path)
使用Tensorflow slim
https://github.com/tensorflow/models/tree/master/research/slim#pre-trained-models
