Spatial and Temporal Mutual Promotion for Video-based Person Re-identification
一、介绍
在这篇文章发表在AAAI2019上,解决的是全监督的视频行人重识别问题。作者没有采取通过每个视频帧特征提取时域特征的方法(RNN/LSTM),而是提出了一个递归精炼单元(refining recurrent unit, RRU),能够根据历史视频帧来恢复当前帧被遮挡和噪声污染的部分(RRU输入和输出的对象是视频帧经过Inception-v3后的特征图)。然后,作者提出了一个时空线索整合模块(spatial-temporal clues integration module, STIM)同时整合空域和时域的信息。作者指出,RNN/LSTM的方法只关注到了特征的时域信息,忽视了特征的空间信息;对特征进行时域池化的方法丢失了视频序列不同区域的运动上下文信息。而作者提出的时空线索整合模块STIM通过三维卷积,能够同时利用到时域和空域的信息。最后,作者提出了一个多层次的损失函数,有针对性的学习,能够进一步提升RRU和STIM的性能。这些模块结合在一起,相互促进,能够学习到更具判别力、更鲁棒的特征表示。
二、作者的方法
2.1 网络整体框架
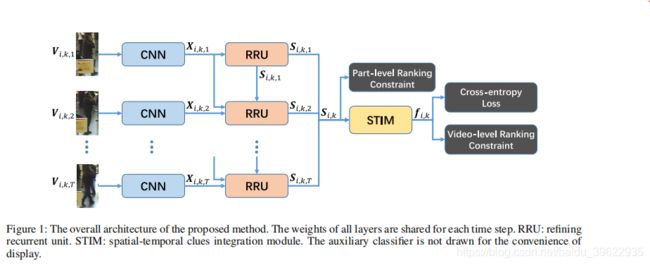
第i个人的第k个视频的T帧送入CNN得到特征图X,然后X经过PRU对特征图X进行精炼修复得到特征图S,S经过时空线索整合模块STIM得到该视频得特征表示f_i,k。训练阶段在batch内进行hard mining,计算整体的三元组损失(video-level ranking constraint)。计算部分间的三元组损失(part-level ranking constraint)。计算分类的cross-entropy loss。然后更新网络。测试阶段用f_i,k计算cosine距离进行匹配。
2.2 递归精炼单元(RRU)
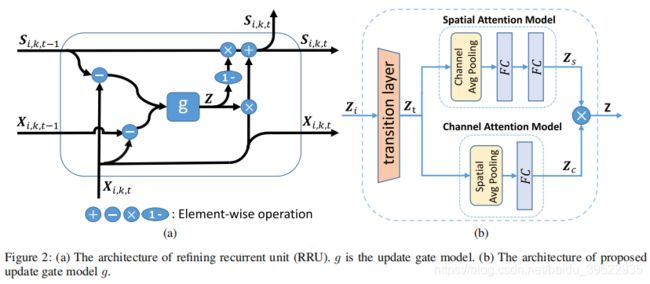
递归精炼单元将X_i,k,t和S_i,k,t-1的差分(CXHXW)作为要精炼修复的内容,将X_i,k,t和X_i,k,t-1的差分作为运动的补充信息,二者在通道上连接(即Z_i)输入到网络g中,输出update gate:Z
![]()
然后按照下式继承一部分S_i,k,t,输入一部分X_i,k,t,获得精炼修复后的特征图s_i,k,t (下式为矩阵点乘)
![]()
下面详细介绍网络g的结构:
对于输入CxHXW的Z_i,经过Conv(1x1,kernels=256)+BN+Relu后变为256XHXW,上路为空间注意力模型,在通道上进行avg pool后变为1XHXW,然后经过FC+Relu+FC后输出1XHXW的空间注意力权重Z_s;下路为通道注意力模型,在空间上进行avg pool变成Cx1x1,然后经过FC后输出CX1X1的通道注意力权重Z_c。然后二者相乘再经过sigmoid非线性激活后得到CXHXW的update gate Z。Z中每个元素值越大,说明位于该位置的特征质量更高,更应该被保留。值越小,说明位于该位置的特征质量越差,用之前精炼过的特征图S在该位置的值代替。
最后,将T帧视频的精炼后的特征图堆叠在一起,得到CXTXHXW的特征图S_i,k。
2.3 时空线索整合模块(STIM)
对每帧的特征进行时域pool的方法没有关注到motion context,作者的时空线索整合模块STIM同时学习appearance representation和motion context,可以很好的解决这个问题。STIM包含两个三维卷积块和一个global avg pool层。CXTXHXW的特征图S_i,k首先经过Conv3d(1x1x1,kernels=256)+BN3d+Relu,进行降维。然后经过Conv3d(3x3x3,kernels=256)得到256XTXHXW的时空特征图O_i,k,然后对时域和空域取平均值得到256维的视频序列的特征f_i,k :、
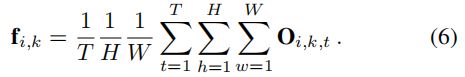
作者指出,3x3x3的卷积块使得STIM能够捕捉行人身体部位的空间移动。同时时空信息的整合也使得STIM能够抵抗空间噪声。
2.4 多层次损失函数
![]()
多层次损失函数由三部分组成, 1)identity classifier and auxiliary classifier of rawInception-v3 model 2)video-level ranking constraint 3)part-level feature representation
其中identity classifier中的fc被换成了fc512+bn+relu+dropout+fc+softmax的classifier block。
video-level ranking constraint和part-level ranking constraint都是通过在一个batch内进行hard mining找到距离最近的不同类样本和距离最远的同类样本计算的。
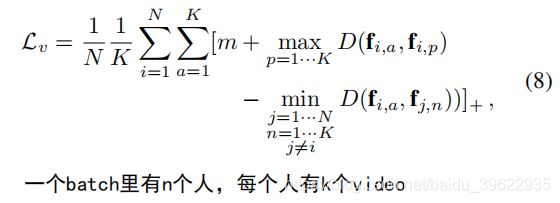
考虑到L_v是基于全局特征f计算的,忽略了局部空间上的差异。而RRU主要功能是精炼局部区域,所以video-level randing constraint不能很好的优化RRU,所以作者提出了part-level ranking constraint来优化RRU。具体来说,L_p就是根据hard mining的结果,计算局部特征间的三元组损失。其中局部特征p_i,k的获得是将S_i,k,t按高分成H个长条,然后对每个长条在宽度、时间上求和得到的。然后再对三元组图片对间对应位置的局部特征计算三元组损失。

作者局部特征获得的方式无需额外参数,更加灵活。同于同样位置的局部特征,同一个人的距离被拉进,不同人的距离被推远。是的RRU能够学的更好,更好地测量不同区域的质量。
三、实施细节
CNN是在ImageNet上预训练的Inception-v3,输入图片被缩放为299x299,没有使用任何数据增强的方法
训练过程中N = 10,K = 2,T = 8 (一个batch总共160张图),identity classifier中dropout设为0.5
使用SGD,学习律0.01,权重衰减5x10^-4,动量0.9。预训练层的学习律乘以0.1
四、实验结果
4.1 成分分析
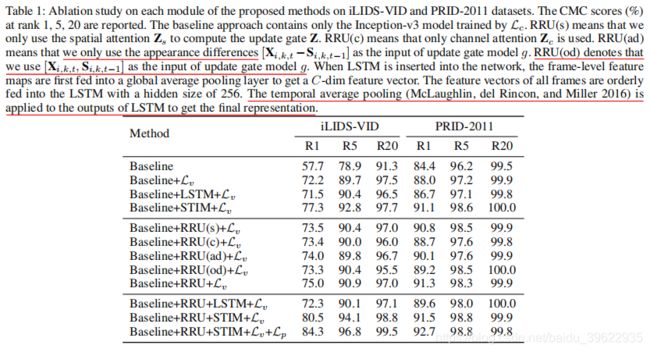

成分分析的实验结果如上图,实验证明RRU、STIM、L_v、L_p以及RRU的输入对提升网络性能都是非常有效的。
4.2 Comparison to the state-of-the-art

iLIDS-VID: 84.3 PRID2011: 92.7 MARS: 84.4 72.7(mAP) 作者的方法在iLIDS-VID和MARS两个数据集上都取得了最好的表现。在PRID2011数据集上取得了略逊于state-of-the-art的表现。作者指出,这是因为PRID2011数据集较简单,遮挡和噪声较少,RRU和SPIM不能完全发挥潜力的缘故。