【NIN】《Network In Network》

arXiv-2013
在 CIFAR-10 上的小实验可以参考博客 【Keras-NIN】CIFAR-10
文章目录
- 1 Background and Motivation
- 2 Advantages / Contributions
- 2.1 Contributions
- 2.2 Advantages
- 3 Innovation
- 4 Method
- 4.1 MLP Convolution Layers
- 4.2 Global Average Pooling
- 5 Dataset
- 6 Experiments
- 6.1 CIFAR-10
- 6.2 CIFAR-100
- 6.3 SVHN
- 6.4 MNIST
- 6.5 FC vs Global average pooling
- 7 Conclusion / Future work
- 8 Code(caffe)
- 8 Pipeline
1 Background and Motivation
先弄清两个 notion
- abstraction:作者指的是 feature is invariant to the variants of the same concept
- latent conception:文章出现多次,我的理解就是 feature representation,参考 《Tensorflow | 莫烦 》learning notes 中的1.4节
CNN filter is a generalized linear model(GLM),GLM 在 latent conception 线性可分的情况下有很好的 abstraction(CNN implicitly 假设了 latent concepts 是线性可分的),但是 data for the same concept often live on a nonlinear manifold. 这样的话 CNN filter 的 abstraction level is low.
因此作者在 CNN filter 中加入了一个 “micro network”,也就是 MLP(叫做mlpconv),引入非线性来提高 abstraction.
2 Advantages / Contributions
2.1 Contributions
- 1x1 conv
- global average pooling 替换 fc
2.2 Advantages
- 在 CIFAR-10 CIFAR-100 上(state-of-art classification performance)
- SVHN、MINST 的结果也相当惊艳
3 Innovation
1x1 conv 引入,添加非线性,提升 abstraction 能力
4 Method
整体结构如下1, mlp(1x1) 后面要接 relu

-
global average pooling vs fully connection(fc)
作者 站边 global average pooling,说很难去解释 how the category level information from the
objective cost layer is passed back to the previous convolution layer due to the fully connected
layers which act as a black box in between. 而且 fc is prone to overfitting,很依赖 drop out -
maxout layer vs mlpconv layer
maxout 2 3 is one of the activation function.优点: Maximization over linear functions makes a piecewise linear approximator which is capable of approximating any convex functions.(linear → convex)
不足:convex还不够,need more non-linear (mlpconv = mlp with relu)
总结- maxout layer:convex function approximator
- mlpconv layer:universal function approximator
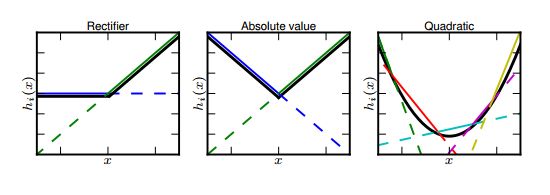
每条线相当于一种线性组合,每段区间取max,能组合成 convex function
4.1 MLP Convolution Layers
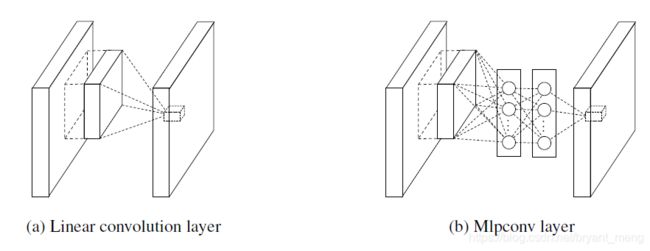
取 patch,然后接 MLP(两层)——micro network,每层的 activation function is Relu,micro network 等价于 1x1 卷积,把 MLP 推倒就非常好理解下面的图了
吴恩达卷积神经网络2.5小节
也就是 Conv x-Conv 1-Conv 1 的堆叠方式,可以参考文章最后的代码,或者 在 CIFAR-10 上的小实验可以参考博客 【Keras-NIN】CIFAR-10
4.2 Global Average Pooling
这个没啥说的,把特征图“九九归一”咯
5 Dataset
- CIFAR-10
- CIFAR-100
- SVHN
The Street View House Numbers (SVHN) Dataset - MNIST
6 Experiments
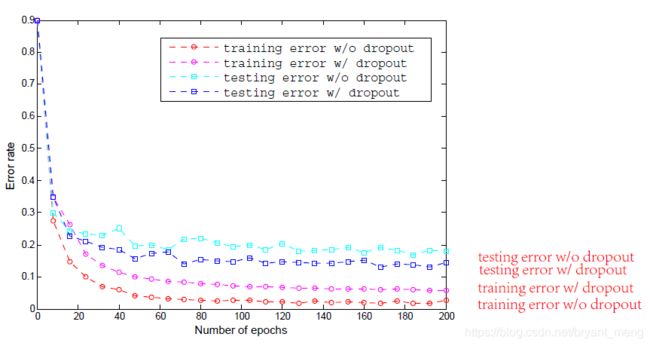
6.1 CIFAR-10

using dropout in between the mlpconv layers
with or without drop out
Visualization of the feature maps from the last mlpconv layer(CIFAR-10)

6.2 CIFAR-100

6.3 SVHN

6.4 MNIST

6.5 FC vs Global average pooling
CIFAR -10

7 Conclusion / Future work
8 Code(caffe)
https://gist.github.com/mavenlin/d802a5849de39225bcc6
name: "NIN_Imagenet"
layers {
top: "data"
top: "label"
name: "data"
type: DATA
data_param {
source: "/home/linmin/IMAGENET-LMDB/imagenet-train-lmdb"
backend: LMDB
batch_size: 64
}
transform_param {
crop_size: 224
mirror: true
mean_file: "/home/linmin/IMAGENET-LMDB/imagenet-train-mean"
}
include: { phase: TRAIN }
}
layers {
top: "data"
top: "label"
name: "data"
type: DATA
data_param {
source: "/home/linmin/IMAGENET-LMDB/imagenet-val-lmdb"
backend: LMDB
batch_size: 89
}
transform_param {
crop_size: 224
mirror: false
mean_file: "/home/linmin/IMAGENET-LMDB/imagenet-train-mean"
}
include: { phase: TEST }
}
layers {
bottom: "data"
top: "conv1"
name: "conv1"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
mean: 0
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "conv1"
top: "conv1"
name: "relu0"
type: RELU
}
layers {
bottom: "conv1"
top: "cccp1"
name: "cccp1"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp1"
top: "cccp1"
name: "relu1"
type: RELU
}
layers {
bottom: "cccp1"
top: "cccp2"
name: "cccp2"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp2"
top: "cccp2"
name: "relu2"
type: RELU
}
layers {
bottom: "cccp2"
top: "pool1"
name: "pool1"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
bottom: "pool1"
top: "conv2"
name: "conv2"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "conv2"
top: "conv2"
name: "relu3"
type: RELU
}
layers {
bottom: "conv2"
top: "cccp3"
name: "cccp3"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 256
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp3"
top: "cccp3"
name: "relu5"
type: RELU
}
layers {
bottom: "cccp3"
top: "cccp4"
name: "cccp4"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 256
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp4"
top: "cccp4"
name: "relu6"
type: RELU
}
layers {
bottom: "cccp4"
top: "pool2"
name: "pool2"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
bottom: "pool2"
top: "conv3"
name: "conv3"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "conv3"
top: "conv3"
name: "relu7"
type: RELU
}
layers {
bottom: "conv3"
top: "cccp5"
name: "cccp5"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 384
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp5"
top: "cccp5"
name: "relu8"
type: RELU
}
layers {
bottom: "cccp5"
top: "cccp6"
name: "cccp6"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 384
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp6"
top: "cccp6"
name: "relu9"
type: RELU
}
layers {
bottom: "cccp6"
top: "pool3"
name: "pool3"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
bottom: "pool3"
top: "pool3"
name: "drop"
type: DROPOUT
dropout_param {
dropout_ratio: 0.5
}
}
layers {
bottom: "pool3"
top: "conv4"
name: "conv4-1024"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 1024
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "conv4"
top: "conv4"
name: "relu10"
type: RELU
}
layers {
bottom: "conv4"
top: "cccp7"
name: "cccp7-1024"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 1024
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp7"
top: "cccp7"
name: "relu11"
type: RELU
}
layers {
bottom: "cccp7"
top: "cccp8"
name: "cccp8-1024"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 1000
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp8"
top: "cccp8"
name: "relu12"
type: RELU
}
layers {
bottom: "cccp8"
top: "pool4"
name: "pool4"
type: POOLING
pooling_param {
pool: AVE
kernel_size: 6
stride: 1
}
}
layers {
name: "accuracy"
type: ACCURACY
bottom: "pool4"
bottom: "label"
top: "accuracy"
include: { phase: TEST }
}
layers {
bottom: "pool4"
bottom: "label"
name: "loss"
type: SOFTMAX_LOSS
include: { phase: TRAIN }
}
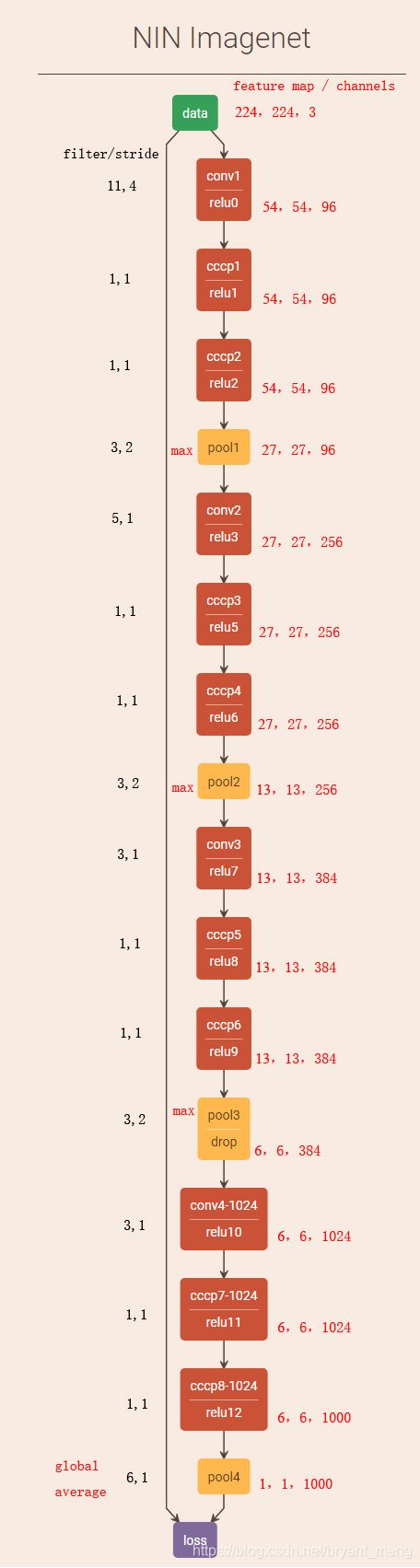
8 Pipeline
http://ethereon.github.io/netscope/#/editor 可视化 caffe代码的工具,代码放入左边运行下即可
深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling ↩︎
深度学习笔记–激活函数:sigmoid,maxout ↩︎
https://arxiv.org/pdf/1302.4389.pdf ↩︎