Python操作泄露的QQ群数据库
之前没有一点儿操作数据库的实际经验,python也没有实现过完整的程序。几乎是走一步搜一步,学到的倒也挺多,对数据库没有那么陌生了。遇到的最大问题却是编码问题……
2、安装SQL Server,采用的2005。计算机为Win7.
3、安装pymssql模块。使用的Python2.7,windows下没有官方发布的针对python2.7的pymssql,从这里得到的 猛点。
最好使用pyodbc,因为pymssql有中文编码问题。
① 可以在SQL Server Management Studio中手动添加。数据库--右键附加--添加--选择MDF。会自动添加LDF信息,因为没有LDF,需要手动将其删除,不然会报错。
② 采用SQL语句批量附加:EXEC sp_attach_db DBName, FilePath
如 EXEC sp_attach_db "GroupData1", "H:\QQ数据库\QunData\GroupData1_Data.MDF"
每个GroupData数据库包含100个表,格式相同,存有QQ号与QQ群的对应关系,以及年龄昵称等信息。每个QQInfo数据库包含10张表,包含QQ群的标题,描述等信息。
主要思路是将查询操作分发到各个数据库的各个表,并收集结果,格式化输出,写入文件。
若保存中文,char(20)只能保存10个汉字,而nchar(20)才可保存20个汉字。因为char(20)表明占用20个字节,然而,数据库中求字符串长度、截取子串等操作是以字符个数为基准的,需要注意。
QQ数据库中采用的varchar保存字符串。
'''UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1: ordinal not in range(128)'''
因为python系统默认编码是ascii,可用sys.getdefaultencoding()查看
将所有地方指定为utf8。
控制台默认为gbk编码,utf8直接打印乱码。但我用的sublime text,utf8是可以正常显示的。
不过,还是尝试重新编码为gbk,同样乱码。
尝试使用charset="gbk"连接数据,查询时直接报错。
…………
…………
山穷水尽时,在另一台XP上使用python远程连接数据库,不做任何编码解码,使用gbk保存,连接,打印。没问题。
理论上,XP与Win7只要语言及区域都是中文,所才有的cp936不会有差别啊……
② 使用Win7,返回结果提取字符串s,s = s.encode("latin1")。然后s就可以正常显示打印写入文件了。
很奇葩啊!不知为何,总之是一大神说的 猛点
更奇葩的是,这样就不能在XP上执行了……
③ 使用pyodbc,指定gbk,什么问题都没有了。开始就用这个,便不会如此虐心了……
还是回到解决编码的正经途径上吧……
减小日志的方法:
① a、 dump transaction DBname with no_log
b、 backup log DBname with no_log
c、收缩数据库
d、设定自动收缩
② 分离数据库,删除日志文件,再附加,OK!
分离数据库的sql语句:EXEC sp_detach_db DBName
2、查询最大ID select top1 * from TableName order by ID desc
或者 select * from TableName where ID in (select max(ID) from TableName)
但是貌似没有第一种效率高
3、查询数据库所有表 select name from sysobjects where xtype='U'
4、python可用 int(strnum) str(intnum) 快捷的在字符串与数字之间转换
5、python格式化输出 "%-15s%s" % (...) 其中表示第一个参数占据15个空间,左对齐,若无-号右对其
5、python实现 进度百分比,关键在于sys.stdout.write("%s%%\r" % (percentage))上。
sys.stdout.write(s)与file.write(s)类似,只不过是写到标准输出上。
--------------------------------------------------------------------------------------
一、准备
1、下载泄漏的QQ数据库。7z格式压缩24.5G,解压后100G。包含11个GroupData.MDF与11个QQInfo.MDF。2、安装SQL Server,采用的2005。计算机为Win7.
3、安装pymssql模块。使用的Python2.7,windows下没有官方发布的针对python2.7的pymssql,从这里得到的 猛点。
最好使用pyodbc,因为pymssql有中文编码问题。
二、添加数据库
只有MDF,没有LDF。MDF是数据库主文件,LDF是日志文件。① 可以在SQL Server Management Studio中手动添加。数据库--右键附加--添加--选择MDF。会自动添加LDF信息,因为没有LDF,需要手动将其删除,不然会报错。
② 采用SQL语句批量附加:EXEC sp_attach_db DBName, FilePath
如 EXEC sp_attach_db "GroupData1", "H:\QQ数据库\QunData\GroupData1_Data.MDF"
每个GroupData数据库包含100个表,格式相同,存有QQ号与QQ群的对应关系,以及年龄昵称等信息。每个QQInfo数据库包含10张表,包含QQ群的标题,描述等信息。
三、Python连接数据库
# 采用pyssql:
conn = pymssql.connect(host='localhost', user='user', password='passwd', database='dbname')
# 采用pydobc:
conn = pyodbc.connect("DRIVER={SQL Server}; SERVER=127.0.0.1; DATABASE=dbname; UID=user; PWD=passwd")
cur = conn.cursor()
cur.execute("select QQNum from Group1 where QunNum = 100010")
rows = cur.fetchall() # 返回的是列表主要思路是将查询操作分发到各个数据库的各个表,并收集结果,格式化输出,写入文件。
四、人机交互:cmd模块
import cmd
from QQDBTools import *
class QQDB(cmd.Cmd):
def __init__(self):
cmd.Cmd.__init__(self)
self.prompt = 'QQDB >>> '
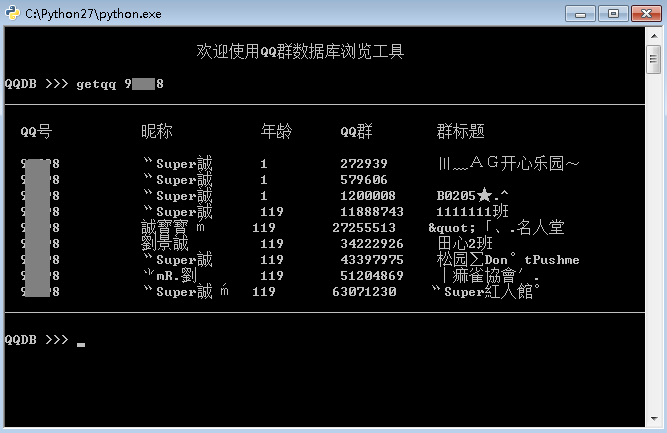
print "\n\t\t\t欢迎使用QQ群数据库浏览工具\n"
def help_getqq(self):
print "如果只显示请输入: getqq 10010101"
print "如果想保存请输入: getqq 10010101 w"
def do_getqq(self, arg):
getQQInfo(arg)
def help_getqun(self):
print "如果只显示请输入: getqun 100010"
print "如果想保存请输入:getqun 100010 w"
def do_getqun(self, arg):
getQunData(arg)
def default(self, line): # 输入无法识别执行该函数
print "无法识别"
def emptyline(self): # 输入为空执行该函数
pass
def help_quit(self):
print "退出程序"
def do_quit(self, line):
sys.exit()
if __name__ == '__main__':
qqdb = QQDB()
qqdb.cmdloop()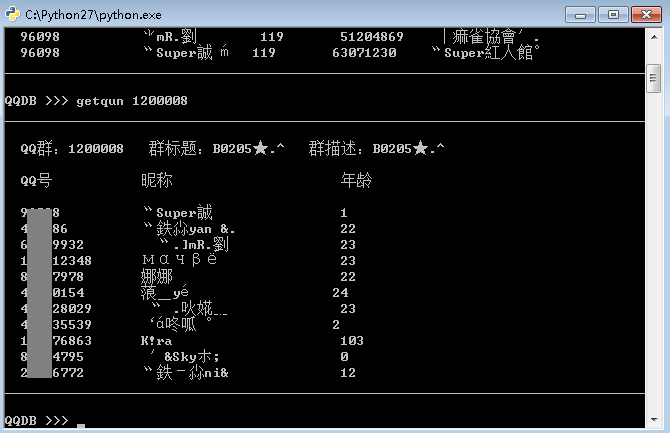
这牛8的QQ号不是本人的,随便找了一个
五、中文编码
1、预备知识
数据库中一般非Unicode字符串类型包括char、varchar、text,Unicode字符串类型包括nchar、nvarchar、ntext。(可在 具体数据库--可编程性--类型--系统数据类型 查看)若保存中文,char(20)只能保存10个汉字,而nchar(20)才可保存20个汉字。因为char(20)表明占用20个字节,然而,数据库中求字符串长度、截取子串等操作是以字符个数为基准的,需要注意。
QQ数据库中采用的varchar保存字符串。
use master select * from syscharsets # 查询数据库支持的字符集,及windows支持的字符集
sp_helpsort # 查询数据库当前排序规则,前半部分即为当前字符集,为Chinese-PRC
select collationproperty('chinese_prc_stroke_ci_ai_ks_ws', 'codepage') # 查询编码格式
# 结果为cp936,此为微软的表示方式,与国标GBK近乎相同pymssql.connect()时,可指定字符集,charset="utf8"。而且只能是utf8这样写,若写作utf-8竟然出错~~~
2、尝试
在任何地方都不指定编码格式,连接后提示某些字符无法解析。'''UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1: ordinal not in range(128)'''
因为python系统默认编码是ascii,可用sys.getdefaultencoding()查看
将所有地方指定为utf8。
# coding: utf8 # 并将文件保存为utf8格式
pymssql.connect(..., charset='utf8') # 使用utf8连接数据库
reload(sys)
sys.setdefaultencoding('utf8') # 将python系统内部编码格式置为utf8控制台默认为gbk编码,utf8直接打印乱码。但我用的sublime text,utf8是可以正常显示的。
不过,还是尝试重新编码为gbk,同样乱码。
尝试使用charset="gbk"连接数据,查询时直接报错。
…………
…………
山穷水尽时,在另一台XP上使用python远程连接数据库,不做任何编码解码,使用gbk保存,连接,打印。没问题。
理论上,XP与Win7只要语言及区域都是中文,所才有的cp936不会有差别啊……
3、解决方法
① 使用XP,不必做特殊转换,或者明确指定gbk就行② 使用Win7,返回结果提取字符串s,s = s.encode("latin1")。然后s就可以正常显示打印写入文件了。
很奇葩啊!不知为何,总之是一大神说的 猛点
更奇葩的是,这样就不能在XP上执行了……
③ 使用pyodbc,指定gbk,什么问题都没有了。开始就用这个,便不会如此虐心了……
六、数据库优化
1、建立索引
QQ数据库除了ID外,只对GroupData的QunNum即群号建立了索引。QQ号查询时,所有数据库扫描一遍至少需要10分钟。对QQNum简历索引。if exists (select name from sysindexes where name=IndexName) # 如果已经存在索引
drop index TableName.IndexName # 删除该索引
create nonclustered index IndexName # 建立非聚集索引 # 另有聚集索引 适用场景不同
on TableName(ColumnName) # 在某个表的某列上
with fillfactor=90 # 填充因子,表示占用空间百分比
# 因为不会对该数据库再增添新数据,所以不必留有太多剩余空间
2、更改列数据类型
实在不知道如何解决乱码问题时,尝试将varchar改为nvarchar,即用unicode存储。试验时不会出现中文乱码了。
可打算将所有数据库更改时,发现太慢,数据库有向200G进军的趋势,并且一个数据库日志LDF就45G多……还是回到解决编码的正经途径上吧……
alter table TableName
alter column ColumnName nvarchar(20)
3、减小日志
经过上一步操作,部分数据太大了减小日志的方法:
① a、 dump transaction DBname with no_log
b、 backup log DBname with no_log
c、收缩数据库
d、设定自动收缩
② 分离数据库,删除日志文件,再附加,OK!
分离数据库的sql语句:EXEC sp_detach_db DBName
七、杂七杂八
1、查询表索引 sp_helpindex TableName2、查询最大ID select top1 * from TableName order by ID desc
或者 select * from TableName where ID in (select max(ID) from TableName)
但是貌似没有第一种效率高
3、查询数据库所有表 select name from sysobjects where xtype='U'
4、python可用 int(strnum) str(intnum) 快捷的在字符串与数字之间转换
5、python格式化输出 "%-15s%s" % (...) 其中表示第一个参数占据15个空间,左对齐,若无-号右对其
5、python实现 进度百分比,关键在于sys.stdout.write("%s%%\r" % (percentage))上。
sys.stdout.write(s)与file.write(s)类似,只不过是写到标准输出上。
'\r'表示回车,即回到行首,'\n'表示换行到下一行。不能用print()因为print表示打印一行。详见 猛点
--------------------------------------------------------------------------------
简陋代码 莫笑
http://download.csdn.net/detail/efeics/6695873