nltk.download('punkt') False
下面是使用NLTK进行分词,然后去除stop_words的操作,但是运行的时候,提示需要下载punkt。
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = "This is a sample sentence, showing off the stop words filtration."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
Our output here:
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing', 'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop', 'words', 'filtration', '.']可是下载一直显示False,尝试了好几次之后,确定不是断网的问题。
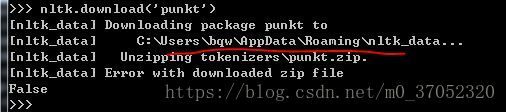
换了别人的机子,就好了。。。。
我想要在我这台机子就将目录复制到对应的失败的目录:
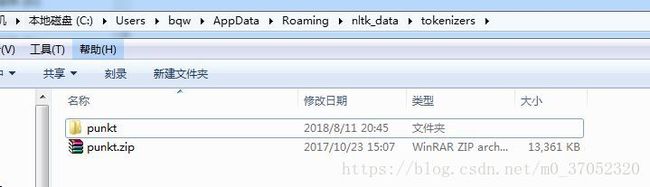
然后就成功了。。。。
最后给出百度盘的下载链接,以防以后下载不下来。
punkt.zip密码:mema