hadoop的单机版测试
一、了解Hadoop
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS为海量的数据提供了存储,
MapReduce为海量的数据提供了计算。而两者只是理论基础,不是具体可使用的高级应用。
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
MapReduce:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
通俗说MapReduce是一套从海量源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
MapReduce的基本原理就是:
将大的数据分析分成小块逐个分析,最后再将提取出来的数据汇总分析,最终获得我们想要的内容。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。
二、Hadoop部署
1、创建hadoop用户及密码
[root@server1 ~]# useradd -u 800 hadoop ##创建hadoop用户uid为:800
[root@server1 ~]# ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[root@server1 ~]# mv * /home/hadoop/ ##将hadoop相关安装包都放在hadoop用户家目录下
[root@server1 ~]# passwd hadoop ##给hadoop用户设置密码
2、切换到hadoop用户安装jdk环境
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ ln -s jdk1.7.0_79/ java ##软连接方便操作
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz java jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd java/
[hadoop@server1 java]$ cd bin/
[hadoop@server1 bin]$ pwd
/home/hadoop/java/bin ##java命令的绝对路径
[hadoop@server1 bin]$ cd
[hadoop@server1 ~]$ vim .bash_profile ##写入java命令绝对路径方便命令使用
PATH=$PATH:$HOME/bin:/home/hadoop/java/bin
[hadoop@server1 ~]$ source .bash_profile ##刷新系统配置
[hadoop@server1 ~]$ jps ##显示当前所有java进程pid的命令
1353 Jps
3、安装hadoop
[hadoop@server1 ~]$ tar zxf hadoop-2.7.3.tar.gz
[hadoop@server1 ~]$ cd hadoop-2.7.3/etc/hadoop
[hadoop@server1 hadoop]$ vim hadoop-env.sh ##声明java

4、独立操作debug
[hadoop@server1 hadoop-2.7.3]$ mkdir input
[hadoop@server1 hadoop-2.7.3]$ cp etc/hadoop/*.xml input/
[hadoop@server1 hadoop-2.7.3]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce
-examples-2.7.3.jar grep input output 'dfs[a-z.]+'

三、伪分布集群搭建
1.配置core-site.xml ###配置Hadoop的核心属性
[hadoop@server1 hadoop-2.7.3]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml
fs.defaultFS
hdfs://172.25.245.1:9000

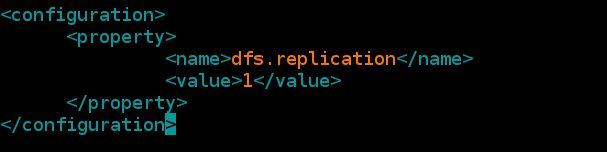
2.配置hdfs-site.xml ##定义hdfs的属性
[hadoop@server1 hadoop]$ vim hdfs-site.xml
dfs.replication
1
3.设置免密登陆
[hadoop@server1 hadoop]$ ssh-keygen ##enter-->enter-->enter
[hadoop@server1 hadoop]$ ssh-copy-id 172.25.45.1 ##把本地的ssh公钥文件安装到远程主机对应的账户

[hadoop@server1 ~]$ cd .ssh/
[hadoop@server1 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@server1 .ssh]$ diff authorized_keys id_rsa.pub ##对比是两个文件是否由不同
若不同在删除authorized_keys文件,并将id_rsa.pub文件复制一份命名为authorized_keys

免密连接:
[hadoop@server1 .ssh]$ ssh 172.25.254.1
[hadoop@server1 ~]$ exit
logout
Connection to server1 closed.
[hadoop@server1 .ssh]$ ssh server1
[hadoop@server1 ~]$ exit
logout
Connection to server1 closed.
[hadoop@server1 .ssh]$ ssh localhost
[hadoop@server1 ~]$ exit
logout
Connection to localhost closed.
[hadoop@server1 .ssh]$ ssh 0.0.0.0
[hadoop@server1 ~]$ exit
logout
Connection to 0.0.0.0 closed.
4.启动hdf
格式化名称节点
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop-2.7.3/etc/hadoop
[hadoop@server1 hadoop]$ vim slaves ##Hadoop集群的slave主机列表,master启动时会通过SSH
连接至此列表中的所有主机并为其启动DataNode和taskTracker进程;
172.25.245.1 ##将localhost改为本机ip
[hadoop@server1 hadoop-2.7.3]$ bin/hdfs namenode -format ##格式化

通过脚本启动
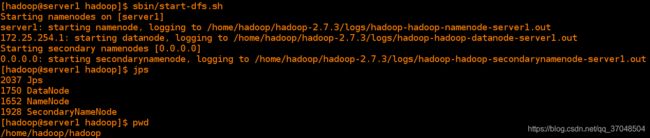
[hadoop@server1 hadoop-2.7.3]$ sbin/start-dfs.sh
[hadoop@server1 hadoop-2.7.3]$ jps 如果jps查看不存在,只要进程或者端口开启说明服务也启动成功了
5.查看服务端口是否开启(50070):

在浏览器中测试:172.25.245.1:50070

测试:创建目录
[hadoop@server1 hadoop-2.7.3]$ bin/hdfs dfs -mkdir /user
[hadoop@server1 hadoop-2.7.3]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop-2.7.3]$ bin/hdfs dfs -ls /user 查看目录下内容,包括文件名,权限,所有者,大小和修改时间
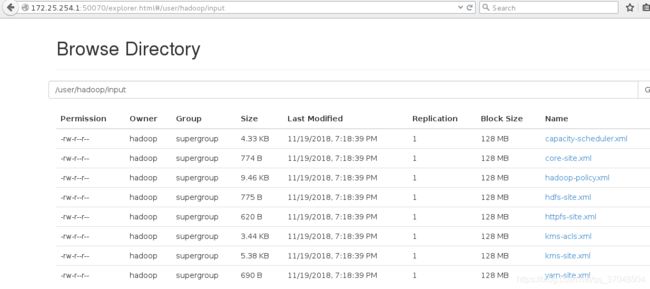
[hadoop@server1 hadoop-2.7.3]$ bin/hdfs dfs -put input/ 将input目录上传到/user/hadoop/下
在浏览器查看,点击utilities,在点击browse file system:
四 YARN单节点
1、 配置mapred-site.xml
[hadoop@server1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@server1 hadoop]$ vim mapred-site.xml
mapreduce.framework
yarn

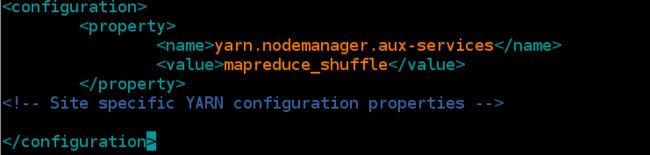
2. 配置yarn-site.xml
[hadoop@server1 hadoop]$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
3.启动yarn
[hadoop@server1 hadoop-2.7.3]# sbin/start-yarn.sh ###停止的话把start换成stop即可
