基于自编码器的协同过滤(论文翻译)
摘要:
本文提出了AutoRec,一个效果非常棒的以自编码器为框架的用于协同过滤的模型。通过实验验证,AutoRec的简洁而有效的可训练模型在Movielens和Netflix数据集上的表现要胜过当前最先进的协同过滤算法(如偏置矩阵分解,限制玻尔兹曼机协同过滤RBM,局部低秩矩阵逼近算法LLORMA)。
关键词:推荐系统; 协同过滤; 自动编码器
1.介绍
协同过滤模型的主要目的是利用用户对商品的偏好等相关信息(比如用户对商品的评分)来提供针对某一用户的个性化推荐。由于Netflix竞赛,至今为止有许多种不同的协同过滤模型被提出,其中最为流行的算法是矩阵分解算法[1,2]和最临近邻居模型[5]。本文提出了AutoRec模型,一个基于自动编码器算法的新型协同过滤模型,由于近年来深度神经网络模型在视觉和语音任务领域的活跃,我们开始对自编码器模型产生了兴趣。我们认为,AutoRec模型比现有的协同过滤模型[4]更具有代表性和计算方面的优势,并且我们通过实验证明了它确实要比现有的最先进的算法更胜一筹。
2.AutoRec模型
在基于用户对商品打分的协同过滤推荐算法中,我们假设有m个用户,n件商品,和一个部分数据不为零的用户-商品打分矩阵R∈Rmxn,在用户数据集中的每一个用户可以用一个部分数据不为零的向量r(u)=(Ru1,...,Run)∈Rn来表示,同样,在商品集中的每一个商品也可以用一个部分数据不为零的向量r(m)=(R1i,...,Rmi)∈Rm。在这项工作中,我们的目标是设计一个将上述的部分数据不为零的向量r(i)(r(u))作为输入数据的基于商品的(或是基于用户的)自动编码器模型,将这个输入的向量映射到一个低维的隐特征向量空间,然后再在输出的向量空间中对这个输入向量进行重构,以此来预测在输入向量中原本等于零的值,这样就可以达到个性化推荐的效果。
算法的具体步骤为,给定一个r∈Rd的向量集S和某些正整数k,训练一个自动编码器需要解决的问题是找到自动编码器的对应参数使得下式成立:
![]() (1)
(1)
其中,h(r;θ)是对输入向量r∈Rd的重构函数,具体表达式如下:
![]() (2)
(2)
在上式中,f(·)和g(·)在均为神经网络的激活函数。构成自编码器模型的参数θ={W,V,μ,b},其中W∈Rdxk,V∈Rkxd是变换矩阵,μ∈Rk和b∈Rd分别是偏差向量。训练这些参数的目的是构建一个具有单个k维隐藏层的自相关神经网络,并通过反向传播的方法学习到参数θ。
基于商品的AutoRec模型如图1所示,但是根据式(1)的自动编码器在具体应用于向量集做个性化推荐时,会有两个很重要的改动。
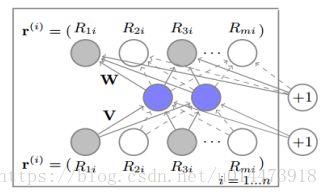
图1 基于商品的AutoRec模型。
我们使用平面图来表示神经网络中共有n个节点,W和V将所有的节点进行全连接的权值
第一,我们考虑到了由于每一个向量r(i)都是只有部分数据是已知不为零的,其余的都是零,即未知数据,所以第一个变化是在通过反向传播进行参数更新的时候,只对那些与不为零的数据连接的权值做更新操作。
由于学习到的参数很有可能对那些不为零的数据过拟合,所以第二个改动就是正则化学习到的参数。
具体做法是基于商品的AutoRec模型的目标函数如下:
![]() (2)
(2)
其中,正则化参数λ>0,表示仅考虑向量中数据不为零的部分。
同理,基于用户的AutoRec模型是以自动编码器为基础,作用于用户的向量集生成。总的来说,基于商品的AutoRec模型一共需要建2mk+m+k个参数。通过这些学习到的参数,基于商品的AutoRec模型所预测到的用户u对商品i的打分函数为:
![]() (3)
(3)
图1清楚的描绘出了整个模型,那些阴影节点对应已知的分数,实现对应的则是通过训练不断更新的和已知分数连接的权值。
AutoRec模型的效果明显要优于现有的协同过滤方法。该模型和基于波兹曼限定机的协同过滤模型[4]相比有几个不同之处。首先,基于波兹曼限定机的协同过滤模型提出了一个基于受限的波兹曼机的一个生成概率模型,然而AutoRec模型是一个基于自编码器的具有识别能力的模型。第二,基于波兹曼限定机的协同过滤模型通过最大化对数相似性来构建参数,而AutoRec模型直接通过最小化均方根误差这个得分预测任务中的表现标准来学习网络参数。第三,训练基于波兹曼限定机的协同过滤模型需要对比分歧,但是训练AuoRec模型需要的用到的方法是相对较快的基于梯度的反向传播。最后,基于波兹曼限定机的协同过滤模型只是用于离散额定分数,并且为每一个分数值单独构建一组参数。这就意味着对于有r个分数的数据集来说,为了构建基于波兹曼限定机的协同过滤模型,需要用nkr(或者mkr)个参数。而AutoRec模型与r无关并且因此构建模型所需要的参数会更少。更少的参数使得AutoRec模型可以占用更小的内存空间并且减少了过拟合的风险。相较于将用户和商品都嵌入到一个共同的隐特征向量空间的矩阵分解协同过滤算法,基于商品的AutoRec模型只需要将商品嵌入到隐特征空间中。此外,相较于通过矩阵分解可以学习到的线性的隐特征表示,AutoRec模型可以通过激活函数g(·)学习到一个非线性的隐特征表示,具有更强的表现力。
3.实验评价
在本节中,我们在Movielens 1M,10M和Netflix数据集上对AutoRec模型和基于波兹曼限定机的协同过滤模型[4],带偏置的矩阵分解协同过滤模型[1]和局部低秩矩阵分解模型[2]的表现进行了实验并比较和评估它们的效果。接下来,我们在测试集中使用一个默认的评分3填在训练集中没有出现的用户或商品的评分中。我们将数据集中的评分信息按照90%-10%的比例划分,90%的数据是训练集,10%的部分是测试集,并且取出了训练集中10%的数据集用于超参数调整。我们重复这个划分步骤5次并且记录平均的均方根误差。每个实验中的均方根误差的95%置信区间为0.003或者更小。对于所有基线,我们调整正则化参数λ∈{0.001,0.01,0.1,1,100,1000}并且调整隐特征维度k∈{10,20,40,80,100,200,300,400,500}。
但是训练自动编码器的一个挑战是它的目标函数是非凸的,我们发现弹性传播(RProp)[3]可以得到与L-BFGS相当的表现效果,但是弹性传播的计算速度更快。因此,我们对所有的后续实验都使用了RProp进行训练:
实验一:基于商品的波兹曼限定机协同过滤模型,基于商品的AutoRec模型,基于用户的波兹曼限定机协同过滤模型和基于用户的AutoRec模型究竟哪一个效果更好?表1a显示基于商品的波兹曼限定机协同过滤模型和基于商品的AutoRec模型总体上来说效果更好;这大概是因为平均每个商品的有评分的数量要远远超过了每个用户的评分数。用户评分数量的习惯上的差异(有人喜欢给高分有人喜欢给低分)导致了基于用户的方法预测的可靠性更低。基于商品的AutoRec模型要比基于波兹曼限定机的协同过滤模型的表现更好。
实验二:AutoRec模型的表现效果随着线性和非线性的激活函数f(·)和g(·)的变化是如何变化的?表1b表明在基于商品的AutoRec模型中,隐藏层使用非线性函数(g(·))会有更好的表现效果,并且还表明了它比矩阵分解方法更有潜在优势。不用sigmoids函数而是使用整流线性单元(ReLU)时,它的表现效果就会变差。所有其它的AutoRec模型的实验都将f(·)函数设置为identity函数,同时将g(·)函数设置为sigmoid函数。
实验三:AutoRec模型的效果是如何随着隐藏层的单元数的变化而变化的?如图2所示,我们在不同的隐藏层的数目设置条件下评估了AutoRec模型的表现效果。根据我们的实验记录,我们发现随着隐藏层的单元数目的增长,AutoRec模型的表现效果在稳定提升,但是提升的速度也在递减。所有其它的实验中,AutoRec的隐藏层的数目都设为k=500。
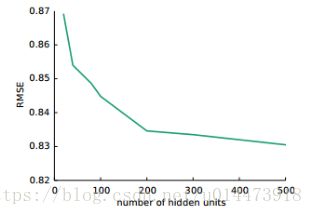
图2 基于商品的AutoRec模型在Movielens 1M上得到的均方根误差随隐层单元数变化的曲线图
实验四:AutoRec模型和其它的经典算法相比较效果如何?表1c显示AutoRec模型除了在Movielens 10M上比LLORMA的表现要差一些,它比所有其它的算法在实验数据集上的表现都更好。LLORMA在Movielens上卓越的表现是令人感兴趣的,因为后者通过加权将50个不同的局部矩阵分解模型结合在一起,而AutoRec仅通过一个神经网络自动编码器对用户或者商品计算隐特征向量表示。



表1:(a)基于用户的AutoRec模型,基于商品的AutoRec模型,
基于用户的波兹曼限定机模型和基于商品的波兹曼限定机模型的均方根误差对比
(b)选择不同的激活函数的AutoRec模型的均方根误差对比
(c)基于商品的AutoRec模型和其它的协同过滤模型在Movielens 1M,Movielens 10M和Netflix数据集上的均方根误差的对比
实验五:加深网络结构对AutoRec的表现有影响吗?我们加深了基于商品的AutoRec模型的网络结构,它的三个隐层的单元数分别为500,250,500,对每一个隐层单元都使用sigmoid函数进行激活。我们使用了贪婪预训练的方法接下来通过梯度下降的方法训练网络得到最佳的参数。在Movielens 1M数据集中,均方根误差从0.831降到了0.827就说明了通过加深网络结构可以提升AutoRec模型的效果。
原文:
Sedhain S, Menon A K, Sanner S, et al. AutoRec:Autoencoders MeetCollaborative Filtering[C]// 2015:111-112.