Kesci:Tensorflow 实现 LSTM——时间序列预测(超详细)
云脑项目3 -真实业界数据的时间序列预测挑战
https://www.kesci.com/home/project/5a391c670e1fc52691fde623
这篇文章将讲解如何使用lstm进行时间序列方面的预测,重点讲lstm的应用,原理部分可参考以下两篇文章:
Understanding LSTM Networks LSTM学习笔记
编程环境:python3.7,tensorflow 1.14
本文所用的数据集来自于kesci平台,由云脑机器学习实战训练营提供:真实业界数据的时间序列预测挑战
本项目的目标是建立内部与外部特征结合的多时序协同预测系统。数据集采用来自业界多组相关时间序列(约40组)与外部特征时间序列(约5组)。课题通过进行数据探索,特征工程,传统时序模型探索,机器学习模型探索,深度学习模型探索(RNN,LSTM等),算法结合,结果分析等步骤来学习时序预测问题的分析方法与实战流程。
# 加载数据分析常用库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
% matplotlib inline
import os
import tensorflow as tf
1 数据导入
# 文件路径
trian_path = '../input/industry/industry_timeseries/timeseries_train_data/'
test_path = '../input/industry/industry_timeseries/timeseries_predict_data/'
1.1 先看一下数据大概长什么样
!head -n 2 ../input/industry/industry_timeseries/timeseries_train_data/11.csv
!head -n 2 ../input/industry/industry_timeseries/timeseries_predict_data/11.csv
2015,2,1,1.900000,-0.400000,0.787500,75.000000,814.155800
2015,2,2,6.200000,-3.900000,1.762500,77.250000,704.251112
2016,9,1,31.900000,20.400000,26.237500,65.500000
2016,9,2,34.300000,19.300000,26.200000,67.750000
1.2 数据格式说明
训练数据有8列:
日期 - 年: int
日期 - 月: int
日期 - 日: int, 时间跨度为2015年2月1日 - 2016年8月31日
当日最高气温 - 摄氏度(下同): float
当日最低气温: float
当日平均气温: float
当日平均湿度: float
输出 - float
预测数据没有输出部分,其他与预测一样。时间跨度为2016年9月1日 - 2016年11月30日
训练与预测都各自包含46组数据,每组数据代表不同数据源,组之间的温度与湿度信息一样而输出不同.
1.3 预期目标
对于训练集和测试集内部而言,表格的时间、温度以及湿度都是相同的,唯一不同的就是target输出,也就是说我们可以用这些属性来对不同的输出做预测
对于训练集和测试集的任一个表格而言,它的时间跨度都是一样的,训练集是从2015年2月1日 - 2016年8月31日,测试集是从2016年9月1日 - 2016年11月30日
我们的目的就是要用训练集中的数据去学习模型,然后用模型去预测同名测试集中的target
可以假设有关联进行建模,也可以视作独立事件建模
我们可以对每一个train和test同名文件单独建立模型预测,分别单独学习46个模型
也可以把数据融合到一块建立一个模型,但不是简单的叠加,涉及multi-task的内容:
1.多组数据汇总后学习一个模型
2.对于每组数据再单独学习一个模型。即有一部分是共性模型,共性模型的基础上又存在个性模型
参考文档:http://ruder.io/multi-task/
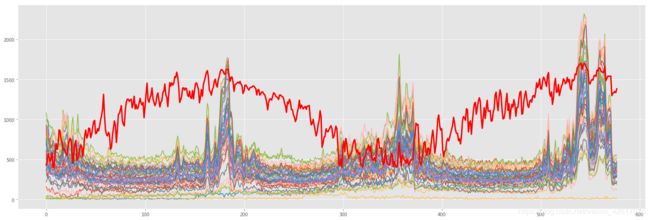
1.4 总体可视化举例
将每日的平均气温这一个指标和46个不同输出值target进行比较。 红色粗线为scale之后的每日平均气温,多条不同的灰色细线为不同地区分别的输出数据。
data = []
name = []
for file_name in os.listdir(trian_path):
file_path = os.path.join(trian_path, file_name)
name.append(file_name.split('.')[0])
d = np.genfromtxt(file_path, delimiter=',', dtype=float)
data.append(abs(d.transpose()))
target_COL = 7
avgC_COL = 5
# plot the output vs. avgC
plt.style.use('ggplot')
plt.figure(figsize=(24,8))
for i, d in enumerate(data):
plt.plot(d[target_COL])
# add scaled average daily temperature to the plot
plt.plot((data[0][avgC_COL] + 10) * 40, linewidth=3, color='r')
plt.show()
2 先取第1个CSV的文件建立一个模型看看
2.1 数据导入
时间已经按照从过去到现在的顺序排列好了,不需要再做调整,同时在做时间序列预测时主要涉及到5个属性,我们的目标是用其余4个属性去预测给定日期的下一天的target。
df11 = pd.read_csv(trian_path+'11.csv',header=None,names=['year','month','day','maxC','minC','avgC','avgH','target'])
test11 = pd.read_csv(test_path+'11.csv',header=None,names=['year','month','day','maxC','minC','avgC','avgH'])
data = df11.ix[:,3:8]
test = test11.ix[:,3:8]
data.head()
maxC minC avgC avgH target
0 1.9 -0.4 0.7875 75.000 814.155800
1 6.2 -3.9 1.7625 77.250 704.251112
2 7.8 2.0 4.2375 72.750 756.958978
3 8.5 -1.2 3.0375 65.875 640.645401
4 7.9 -3.6 1.8625 55.375 631.725130
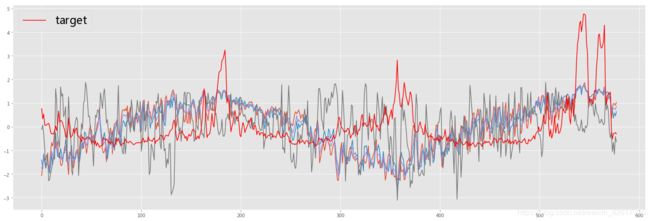
2.2 Z-Score标准化后对数据进行可视化大体看看分布情况
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
data_sd = ss.fit_transform(data)
plt.figure(figsize=(24,8))
plt.plot(data_sd[:,:4])
plt.plot(data_sd[:,4],label = 'target',color='red')
plt.legend(loc = 'upper left',fontsize = 24)
plt.show()
3 LSTM模型
data = np.array(df11.ix[:,3:8])
test = np.array(test11.ix[:,3:8])
3.1 设置常量
rnn_unit = 10 # 隐层数量
input_size = 4
output_size = 1
lr = 0.0006 # 学习率
epochs = 500
3.2 获取训练集
# 获取训练集
def get_train_data(batch_size=60, time_step=20,train_begin=0, train_end=len(data)):
batch_index = []
data_train = data[train_begin:train_end]
normalized_train_data = (
data_train-np.mean(data_train, axis=0))/np.std(data_train, axis=0) # 标准化
train_x, train_y = [], [] # 训练集
for i in range(len(normalized_train_data)-time_step):
if i % batch_size == 0:
batch_index.append(i)
x = normalized_train_data[i:i+time_step, :4]
y = normalized_train_data[i:i+time_step, 4, np.newaxis]
train_x.append(x.tolist())
train_y.append(y.tolist())
batch_index.append((len(normalized_train_data)-time_step))
return batch_index, train_x, train_y
3.3 获取测试集
def get_test_data(time_step=20,data=data,test_begin=0):
data_test = data[test_begin:]
mean = np.mean(data_test, axis=0)
std = np.std(data_test, axis=0)
normalized_test_data = (data_test-mean)/std # 标准化
size = (len(normalized_test_data)+time_step-1)//time_step # 有size个sample
test_x, test_y = [], []
for i in range(size-1):
x = normalized_test_data[i*time_step:(i+1)*time_step, :4]
y = normalized_test_data[i*time_step:(i+1)*time_step, 4]
test_x.append(x.tolist())
test_y.extend(y)
test_x.append((normalized_test_data[(i+1)*time_step:, :4]).tolist())
test_y.extend((normalized_test_data[(i+1)*time_step:, 4]).tolist())
return mean, std, test_x, test_y
3.4 神经网络变量定义
# 输入层、输出层权重、偏置
weights = {
'in': tf.Variable(tf.random_normal([input_size, rnn_unit])),
'out': tf.Variable(tf.random_normal([rnn_unit, 1]))
}
biases = {
'in': tf.Variable(tf.constant(0.1, shape=[rnn_unit, ])),
'out': tf.Variable(tf.constant(0.1, shape=[1, ]))
}
3.5 建立lstm模型
def lstm(X):
batch_size = tf.shape(X)[0]
time_step = tf.shape(X)[1]
w_in = weights['in']
b_in = biases['in']
input = tf.reshape(X, [-1, input_size]) # 需要将tensor转成2维进行计算,计算后的结果作为隐藏层的输入
input_rnn = tf.matmul(input, w_in)+b_in
# 将tensor转成3维,作为lstm cell的输入
input_rnn = tf.reshape(input_rnn, [-1, time_step, rnn_unit])
cell = tf.contrib.rnn.BasicLSTMCell(rnn_unit)
init_state = cell.zero_state(batch_size, dtype=tf.float32)
output_rnn, final_states = tf.nn.dynamic_rnn(
cell, input_rnn, initial_state=init_state, dtype=tf.float32)
output = tf.reshape(output_rnn, [-1, rnn_unit])
w_out = weights['out']
b_out = biases['out']
pred = tf.matmul(output, w_out)+b_out
return pred, final_states
3.6 训练模型
def train_lstm(batch_size=60, time_step=20,epochs=epochs, train_begin=0, train_end=len(data)):
X = tf.placeholder(tf.float32, shape=[None, time_step, input_size])
Y = tf.placeholder(tf.float32, shape=[None, time_step, output_size])
batch_index, train_x, train_y = get_train_data(batch_size, time_step, train_begin, train_end)
with tf.variable_scope("sec_lstm"):
pred, _ = lstm(X)
loss = tf.reduce_mean(
tf.square(tf.reshape(pred, [-1])-tf.reshape(Y, [-1])))
train_op = tf.train.AdamOptimizer(lr).minimize(loss)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=15)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(epochs): # 这个迭代次数,可以更改,越大预测效果会更好,但需要更长时间
for step in range(len(batch_index)-1):
_, loss_ = sess.run([train_op, loss], feed_dict={X: train_x[batch_index[
step]:batch_index[step+1]], Y: train_y[batch_index[step]:batch_index[step+1]]})
if (i+1)%50==0:
print("Number of epochs:", i+1, " loss:", loss_)
print("model_save: ", saver.save(sess, 'model_save/modle.ckpt'))
# 我是在window下跑的,这个地址是存放模型的地方,模型参数文件名为modle.ckpt
# 在Linux下面用 'model_save2/modle.ckpt'
print("The train has finished")
train_lstm()
Number of epochs: 50 loss: 0.973022
model_save: model_save/modle.ckpt
Number of epochs: 100 loss: 0.502242
model_save: model_save/modle.ckpt
Number of epochs: 150 loss: 0.400849
model_save: model_save/modle.ckpt
Number of epochs: 200 loss: 0.323891
model_save: model_save/modle.ckpt
Number of epochs: 250 loss: 0.27513
model_save: model_save/modle.ckpt
Number of epochs: 300 loss: 0.245793
model_save: model_save/modle.ckpt
Number of epochs: 350 loss: 0.215545
model_save: model_save/modle.ckpt
Number of epochs: 400 loss: 0.195946
model_save: model_save/modle.ckpt
Number of epochs: 450 loss: 0.178385
model_save: model_save/modle.ckpt
Number of epochs: 500 loss: 0.162249
model_save: model_save/modle.ckpt
The train has finished
4 模型性能评估
# 预测模型
def prediction(time_step=20):
X=tf.placeholder(tf.float32, shape=[None,time_step,input_size])
mean,std,test_x,test_y=get_test_data(time_step,test_begin=0)
with tf.variable_scope("sec_lstm",reuse=True):
pred,_=lstm(X)
saver=tf.train.Saver(tf.global_variables())
with tf.Session() as sess:
#参数恢复
module_file = tf.train.latest_checkpoint('model_save')
saver.restore(sess, module_file)
test_predict=[]
for step in range(len(test_x)-1):
prob=sess.run(pred,feed_dict={X:[test_x[step]]})
predict=prob.reshape((-1))
test_predict.extend(predict)
test_y=np.array(test_y)*std[4]+mean[4]
test_predict=np.array(test_predict)*std[4]+mean[4]
acc=np.average(np.abs(test_predict-test_y[:len(test_predict)])) #mean absolute error
print("The MAE of this predict:",acc)
#以折线图表示结果
plt.figure(figsize=(24,8))
plt.plot(list(range(len(test_predict))), test_predict, color='b',label = 'prediction')
plt.plot(list(range(len(test_y))), test_y, color='r',label = 'origin')
plt.legend(fontsize=24)
plt.show()
prediction()
The MAE of this predict: 43.9676934085
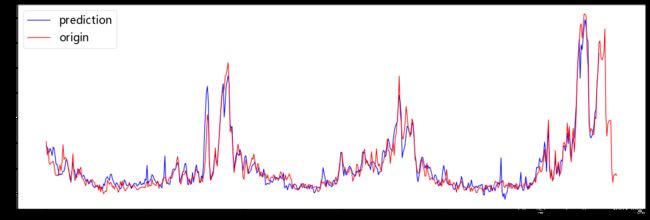
这个结果是我之前把target也作为一个属性加进去的结果: 从图形的趋势来看,预测的结果还是很好的,并且平均绝对误差只有6.29587688429
用来预测的test数据集是没有target这个属性的,所以后来用4个属性来建立模型时,可见效果确实差不少,趋势大致符合,但是MAE增加到了43.9676934085,epochs如果再适当增加的话应该还能提高一些模型的性能。
5 在测试集上进行预测
# 获取测试集
def test_get_test_data(time_step=20,data=test,test_begin=0):
data_test = data[test_begin:]
mean = np.mean(data_test, axis=0)
std = np.std(data_test, axis=0)
normalized_test_data = (data_test-mean)/std # 标准化
size = (len(normalized_test_data)+time_step-1)//time_step # 有size个sample
test_x = []
for i in range(size-1):
x = normalized_test_data[i*time_step:(i+1)*time_step, :4]
test_x.append(x.tolist())
test_x.append((normalized_test_data[(i+1)*time_step:, :4]).tolist())
return test_x
# 预测模型
def test_prediction(time_step=20):
X=tf.placeholder(tf.float32, shape=[None,time_step,input_size])
test_x=test_get_test_data(time_step,test_begin=0)
mean,std,_,_=get_test_data(time_step,test_begin=0)
with tf.variable_scope("sec_lstm",reuse=True):
pred,_=lstm(X)
saver=tf.train.Saver(tf.global_variables())
with tf.Session() as sess:
#参数恢复
module_file = tf.train.latest_checkpoint('model_save')
saver.restore(sess, module_file)
test_predict=[]
for step in range(len(test_x)-1):
prob=sess.run(pred,feed_dict={X:[test_x[step]]})
predict=prob.reshape((-1))
test_predict.extend(predict)
test_predict=np.array(test_predict)*std[4]+mean[4]
#以折线图表示结果
plt.figure(figsize=(24,8))
plt.plot(list(range(len(test_predict))), test_predict, color='b',label = 'prediction')
plt.legend(fontsize=24)
plt.show()
return test_predict
test11_predict = test_prediction()

timeseries_predict_data/11.csv 的预测结果大致是这样的趋势,因为前面在建立模型时都对输入和输出进行了标准化处理,但是后来在对test做预测时,test中target的均值和方差是未知的,所以只能退而求其次用训练集的均值和方差来替代,这样会带来一些误差。这样的话前面就不应该做标准化,标准化对结果的影响到底多大以后需要实际建立模型进一步分析一下。
test11_predict[:10]
array([ 779.84606934, 908.08032227, 891.70629883, 929.58239746,
927.7890625 , 902.19372559, 819.25695801, 911.3416748 ,
969.91503906, 1041.61035156], dtype=float32)
6 按照之前方法继续对其他数据建立模型看看效果怎么样
df17 = pd.read_csv(trian_path+'17.csv',header=None,names=['year','month','day','maxC','minC','avgC','avgH','target'])
test17 = pd.read_csv(test_path+'17.csv',header=None,names=['year','month','day','maxC','minC','avgC','avgH'])
data = np.array(df17.ix[:,3:8])
test = np.array(test17.ix[:,3:8])
train_lstm()
prediction()
Number of epochs: 50 loss: 1.20456
model_save: model_save/modle.ckpt
Number of epochs: 100 loss: 0.605511
model_save: model_save/modle.ckpt
Number of epochs: 150 loss: 0.397395
model_save: model_save/modle.ckpt
Number of epochs: 200 loss: 0.348534
model_save: model_save/modle.ckpt
Number of epochs: 250 loss: 0.30729
model_save: model_save/modle.ckpt
Number of epochs: 300 loss: 0.278667
model_save: model_save/modle.ckpt
Number of epochs: 350 loss: 0.254374
model_save: model_save/modle.ckpt
Number of epochs: 400 loss: 0.237127
model_save: model_save/modle.ckpt
Number of epochs: 450 loss: 0.22857
model_save: model_save/modle.ckpt
Number of epochs: 500 loss: 0.237186
model_save: model_save/modle.ckpt
The train has finished
The MAE of this predict: 33.8511291865

从图像上来看效果还算不错。
7 简单总结
本文对timeseries_train_data/11.csv建立了LSTM预测模型,并在训练集上评估了模型的性能
本文利用LSTM模型给出了timeseries_predict_data/11.csv的预测结果并绘制了趋势图
本文同样对timeseries_train_data/17.csv建立了LSTM预测模型,并评估了效果,但是没有再对其他的44个数据集建立模型了,只要数据导入运行即可,都是重复性的工作
由于时间的关系,本文只建立了LSTM模型,没有与传统的时间序列模型以及其他的深度学习模型进行对比