【李宏毅2020 ML/DL】P51 Network Compression - Knowledge Distillation | 知识蒸馏两大流派
我已经有两年 ML 经历,这系列课主要用来查缺补漏,会记录一些细节的、自己不知道的东西。
已经有人记了笔记(很用心,强烈推荐):https://github.com/Sakura-gh/ML-notes
本节内容综述
- 本节课由助教
Arvin Liu补充一些前沿的技术,李老师讲的,其实有些老了。 - 首先复习模型压缩的四个流派。
- Why learn 'em all? Mix it! 助教举了一个混合的例子。
- 接下来进入本节课正题,讲知识蒸馏的两个流派:Distill what?
Logits(输出值),或Feature(中间值)。可以直接学习 Feature ,或者学习如何做转换。此外,其实还有个Relational KD。 - 在介绍 Logits KD 前,要介绍一下 soften label 是有用的。提到了
Label Refinery,并且提到,学生网络的表现是有可能超过教师网络的。 - 进入第一部分,
Logits Distillation。 - 之后是另一部分,
Feature Distillation。 - Can we learn something from batch? 引出
Relational KD。 - Why not distill relational information between feature?
Similarity-Preserving KD
文章目录
- 本节内容综述
- 小细节
-
-
- 四个流派
-
- Network Pruning
- Knowledge Distillation
- Architecture Design
- Parameter Quantization
- 混合这些技术举例
- Magic of Soften Label
- Logits Distillation
-
- Deep Mutual Learning
- Born Again Neural Networks
- Hidden Problem in Pure Logits KD
- TAKD
- Feature Distillation
-
- FitNet
- Hidden Problem in FitNet
- Attention
- Relational KD
-
- Similarity-Preserving KD
-
小细节
四个流派
Network Pruning
方法:将 Network不重要的 weight 或 neuron 进行删除,再重 train 一次。
原因:大 NN 有很多冗参数,而小 NN 很难 train ,那就用大 NN 删成小 NN 就好了。
应用:只要他是 NN(?) 就可以。
Knowledge Distillation
方法:利用一个已经学好的大 model,来教小 model 如何做好任務。
原因:让学生直接做对题目太难了,可以让他偷看老师是怎想/解出题目的。
应用:通常只用在 Classification,而且学生只能从头学起。
Architecture Design
方法:利用更少的参数来达到原本某些 Layer 的效果。
原因:有些 Layer 可能参数就是很冗余,例如DNN 就是个明显例子。
应用:就是直接套新的 model,或是利用新的 Layer 來模拟的 player 。
Parameter Quantization
方法:将原本 NN 常用的计算单位:foat32 / float64 压缩成更小的单位。
原因:对 NN 來说,LSB 可能不是那么的重要。
应用:对所有已经 train 好的 model 使用,或者边 train 边引诱 model 去 quantize 。
LSB:Least-Significant Bit,在这里指小数点的后面其实很冗。
混合这些技术举例

Magic of Soften Label
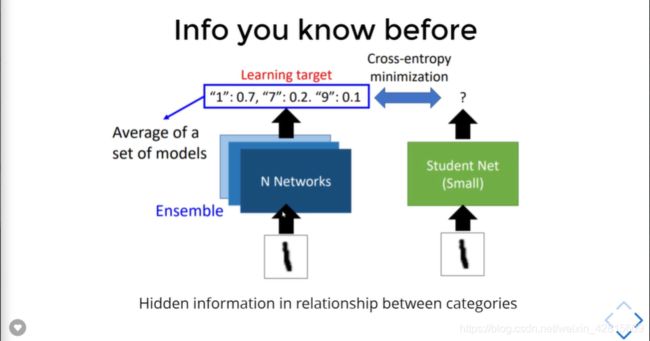
Hidden information in relationship between categories.

如上,这张照片中不仅仅只有猫(还有球与牛仔裤),如果只查看模型的输出的最终结果,实际上是对模型的理解不全面的。
可以使用“精细化标签(Label Refinery)”。
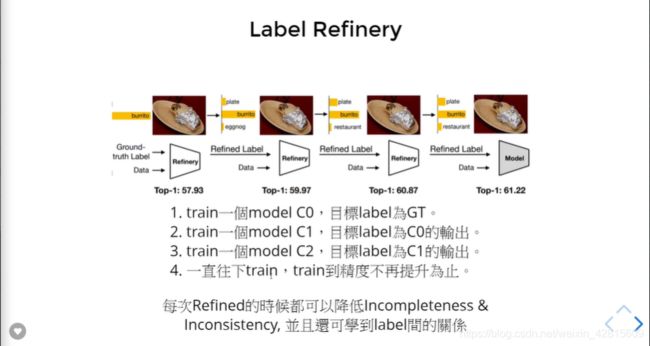
如上,依次训练“精细化”的模型,直到不再提升进度为止。
Logits Distillation

Deep Mutual Learning

1学2,2学1。

上为1学2。

上为2学1。
Born Again Neural Networks

第一个模型用知识蒸馏,之后使用交叉熵迭代。最后集成学习所有的学生网络。
Hidden Problem in Pure Logits KD
可能学生网络“不够深”,无法学习教师网络进行的“思考”。
如何解决呢?
TAKD

如上,另请一个“中间人”,作为过渡,“教”学生网络学习目标网络。
Feature Distillation
FitNet
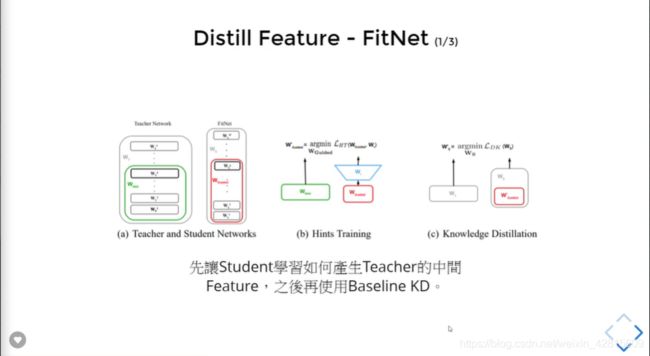
如果让 Student 产生的 feature 与 teacher 的 feature 一样,那之后是不是可以直接用 Baseline KD 来做了呢?
因此 FitNet 有两个目标:
- 学 feature;
- Baseline 。
如何做呢?
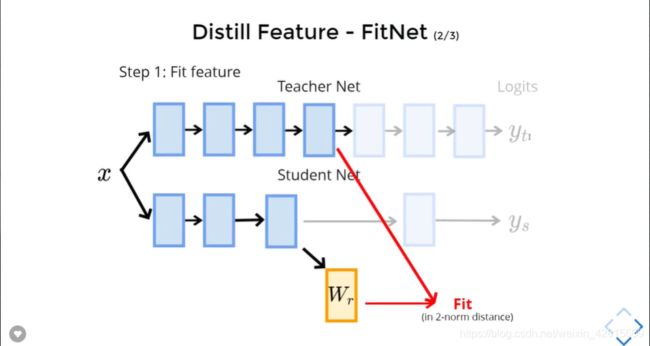
如上,要注意,不同的网络两层互相学习前,要多加一层 Layer ,转换成相同的 size 。

如上,之后进行 Baseline KD 。
Hidden Problem in FitNet

如上,可能由于网络容量原因,学生网络注定无法学到教师网络的内容。
此外,教师网络的很多 feature 可能知识密度并不够,有很多冗余。
因此,我们可以提出,讲教师网络的 feature 压缩,以提取精华。
Attention

如上,让网络意识到,哪部分是重要的。
如何得到 attention map 呢?

如上,可以对特征值进行压缩。
Relational KD

上图中,t代表教师网络的输出,s代表学生网络的输出。
Relational KD 将样本间的关系进行知识蒸馏。

如上,如何设置 ψ \psi ψ 函数值得讨论(衡量输入数据是否相像的函数)。

如上,可以从举例、角度的方式进行衡量。
Similarity-Preserving KD

如上,不同的输入有不同的特征值,可以基于 Cosine 这样的运算绘制一个 Similarity Table 。
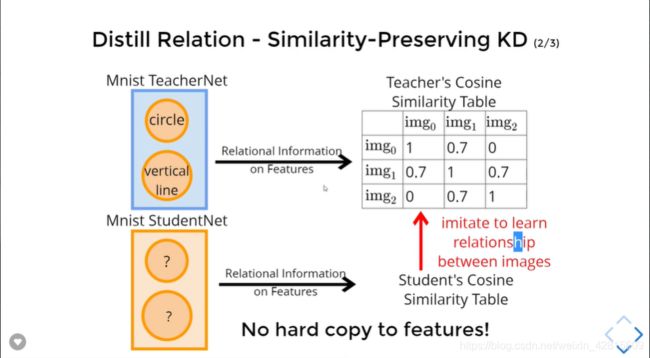
如上,让学生也产生一个自己的Similarity Table,然后依照表去学习教师的表。由此,学生不止可以学到特征,还可以学到特征间的关系。
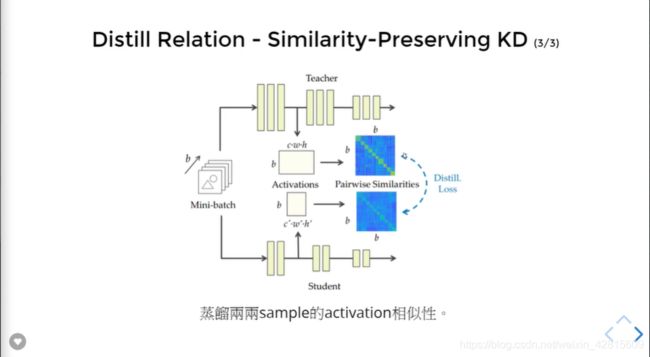
如上,在训练中,争取让学生网络与教师网络的Similarity Table进行相近。