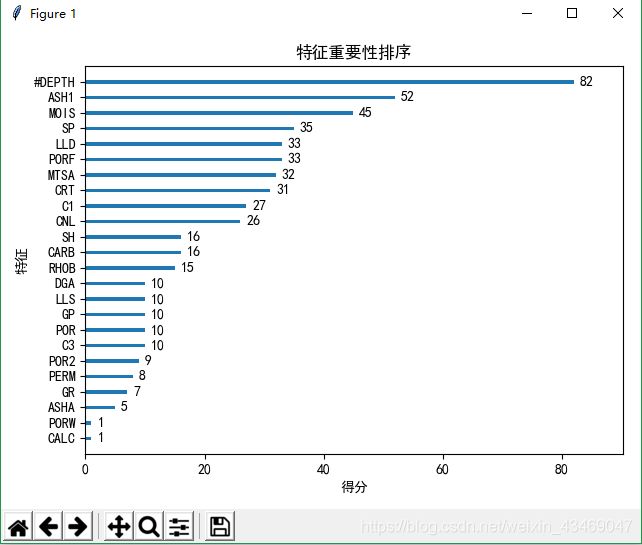
使用XGboost模块XGBClassifier、plot_importance来做特征重要性排序——修改f1,f2等字段
如果你还不知道如何使用XGboost模块XGBClassifier、plot_importance来做特征重要性排序,戳这个网址即可。
下面我们讲一个全网都没好好讲的问题:如何修改f1,f2成对应的特征名称。(我它喵了个咪的找了起码5天,都是回答不全或者不清楚对应数据格式,最后终于慢慢试出来了)
一、首先,plot_importance()方法是可以自定义title(默认feature importance)、xlabel(默认F score)、ylabel(默认features)和是否网格grid的,更具体的可以使用help()命令或者查看官方文档的。
之前不知道如何改一直以为是xgboost库的问题,现在才发现原来有很多是pyplot子库可以做的,而且plot_importance()方法也确实提供了这些方法,眼拙眼拙。
二、其次,解决中文、负号和自适应的显示问题,可以用如下代码进行设置
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 使显示图标自适应
plt.rcParams['figure.autolayout'] = True
三、再次,看一下数据格式和读取方式
- 我选择的数据格式类似于下面这样csv文件(无index,分类结果就是level)
- 使用的读取数据方式是numpy.loadtxt() (np.load_txt使用方法:戳这儿)
这种读取的特点是只能读取纯数据,也就是表头(表头包含feature名称和分类结果label\level)下面的所有数据。 - 要想得到满意的结果,数据还需要一个转换
# x是我的features列表
x = ['#DEPTH', 'SP', 'GR', 'LLS', 'LLD', 'BS', 'RHOB', 'CNL', 'TC', 'NPHI', 'C1', 'C3', 'CALC', 'MTSA',
'MTSC', 'DGA', 'PERM', 'POR', 'POR2', 'PORF', 'RWA', 'PORT', 'PORW', 'CRT', 'SAND', 'SH', 'MOIS', 'CARB', 'ASHA',
'GC', 'GP', 'WP', 'ASH1']
# 中间省略很多步...
# dtrain是我的训练数据(自变量矩阵是X,分类结果即因变量矩阵是y,特征字段重命名成我设置的features列表)
dtrain = xgb.DMatrix(X, label=y, feature_names=x)
四、最后,关于模型训练
你会发现使用的方法跟使用XGboost模块XGBClassifier、plot_importance来做特征重要性排序这篇文章所述已经不一样啦哈哈!
因为我们使用的是
# 构建参数字典
param = {}
# use softmax multi-class classification
param['objective'] = 'multi:softmax'
# scale weight of positive examples
param['eta'] = 0.1
param['max_depth'] = 6
param['silent'] = 1
param['nthread'] = 4
param['num_class'] = 9
# 训练模型的方式有点不一样哦,这个是直接传入打包好的训练数据(同时含自变量、因变量矩阵)
model = xgb.train(param, dtrain)
五、大一统代码!
from numpy import loadtxt
import xgboost as xgb
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot as plt
import matplotlib as mpl
import pandas as pd
from sklearn.feature_selection import SelectFromModel
import warnings
warnings.filterwarnings("ignore")
# 加载数据集
path = "label_csv.csv"
dataset = loadtxt(path, skiprows=1, delimiter=",") # 以','为分割符,跳过1行(标features那一行)
x = ['#DEPTH', 'SP', 'GR', 'LLS', 'LLD', 'BS', 'RHOB', 'CNL', 'TC', 'NPHI', 'C1', 'C3', 'CALC', 'MTSA',
'MTSC', 'DGA', 'PERM', 'POR', 'POR2', 'PORF', 'RWA', 'PORT', 'PORW', 'CRT', 'SAND', 'SH', 'MOIS', 'CARB', 'ASHA',
'GC', 'GP', 'WP', 'ASH1']
print(len(x))
# X:自变量矩阵(特征对应的数据) y:因变量矩阵(根据数据得出的分类结果)
X = dataset[:,0:-1]
y = dataset[:,-1]
dtrain = xgb.DMatrix(X, label=y, feature_names=x)
param = {}
# use softmax multi-class classification
param['objective'] = 'multi:softmax'
# scale weight of positive examples
param['eta'] = 0.1
param['max_depth'] = 6
param['silent'] = 1
param['nthread'] = 4
param['num_class'] = 9
model = xgb.train(param, dtrain)
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 使显示图标自适应
plt.rcParams['figure.autolayout'] = True
plot_importance(model, title='特征重要性排序', xlabel='得分', ylabel='特征', grid=False)
plt.show()
# 参考文章:http://www.huaxiaozhuan.com/%E5%B7%A5%E5%85%B7/xgboost/chapters/xgboost_usage.html
# https://xbuba.com/questions/46943314
# https://blog.csdn.net/leo_xu06/article/details/52424924
# https://stackoverflow.com/questions/46943314/xgboost-plot-importance-doesnt-show-feature-names
# https://blog.csdn.net/hao5335156/article/details/81173452
# https://www.cnblogs.com/wj-1314/p/9402324.html