Image Generation from Scene Graph
写一点看过的论文和code的感悟
首先看一下论文的总体实现:
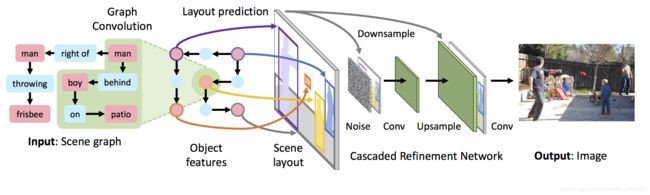
我觉得这个模型与传统模型主要的两个创新点就是Graph Convolution和Cascaded Refinement Network
Graph Convolution
按论文上说,他处理scene graph 是通过graph的边来传递信息的,也就是所本来一个单词向量(obj_vecs)代表graph中的一个节点对象,但是通过图卷积之后每个obj_vecs包含了所有和它相邻的节点对象的信息(也就是有边相连的节点),这样通过获得的new_obj_vecs用来预测mask和bounding_box时就能较好的区分开来。相对于StackGAN++中直接用一个sentence_vecs预测一张图像就能更好低区分途中的不同对象,使每个对象尽可能的精细。
比如我们有这样一张scene graph:

这是一张有三个object 三个relationship的graph,可以得到如下关系对:
o–> p --> s
elephant --> inside --> tree
elephant --> above --> grass
tree --> surrounding --> elephat
然后将其通过nn.embedding()转换之后得到(3, 3 x 128)(假设每个单词的dim为128)
(3, 3 x 128 ) --> net1 --> (3, 1152): net1 就是一个简单的MLP网络,1152 = 512(o) + 128(p) + 512(s)
将得到512 dim表示的obj_vec(即o, s) ,调用scatter_add()函数将写入到new_obj_vecs(3,512)。
(3, 3 x 512 ) --> net2 --> (3, 128): net2 也是一个简单的MLP网络
这样新的到的节点对象向量就包含了相邻节点的信息,这就是这篇论文中的Graph Convolutional Networks,通过graph 的边传递信息。
Scene Layout
先看一下论文中是怎么预测 scene layout的。
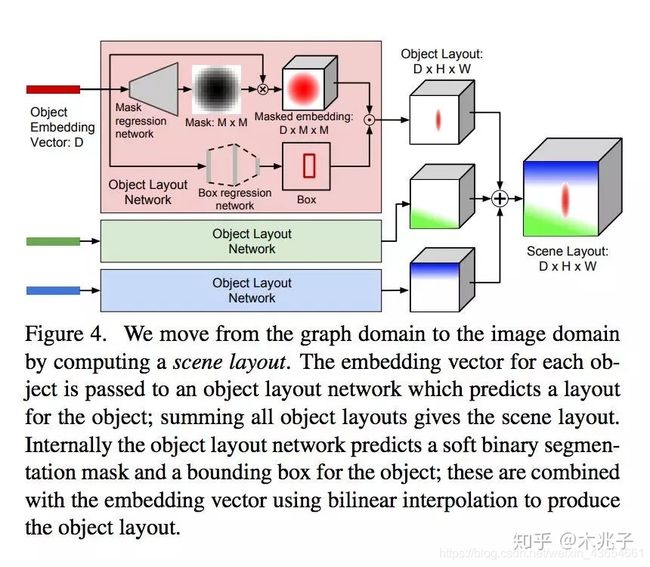
obj_vecs–> MaskNet–>Mask
(3,128) --> Mask Net --> (3, 16, 16) : mask net 可以看成是一个Upsample,mask size = (M, M) = (16, 16)
obj_vecs * Mask --> layout_masks
(3, 128) * (3 , 16, 16) --> (3, 128, 16, 16): obj_vecs * mask = masked_embeding。
obj_vecs -->layout_boxes
(3, 128) --> Box Net --> (3, 4): box net 也是一个简单的MLP网络
当我们得到Mask 和Box的时候就能用于预测sence layout 了。
layout = masks_to_layout(obj_vecs, layout_boxes, layout_masks, obj_to_img, H, W)
"""
obj_to_img: 这个节点对象对应与哪张图片
image size = (H, W)
"""
其中实现的关键函数是nn.function.grid_samples(input, grid),output根据grid存储的坐标在input中选点,将选中点的值作为输出保存到output中。很明显,在这篇文章中,input由我们的layout mask 产生,而grid则通过对layout_box处理得到。input.shape=(3, 128, 64, 64) ,grid.shape=(3, 64, 64, 2)
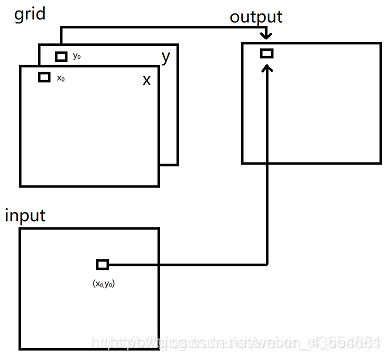
最终得到layout.shape = (1, 128, 64, 64)
CRN
得到layout加上一个随机噪声之后放入到一个级联细化网络就能得到一张输出图像了,关于级联喜欢网络具体可以在后面介绍。