机器学习之基本概述
1、基本概念
- Machine Learning(ML) is a scientific discipline that deals with theconstruction and study of algorithms that can learn from data.
- 机器学习是一门从数据中研究算法的科学学科。
- 机器学习直白来讲,是根据已有的数据,进行算法选择,并基于算法和数据构建模型,最终对未来进行预测
- 鲁棒性:也就是健壮性、稳健性、强健性,是系统的健壮性;当存在异常数据的时候,算法也会拟合数据
- 过拟合:算法太符合样本数据的特征,对于实际生产中的数据特征无法拟合
- 欠拟合:算法不太符合样本的数据特征
2、分类,聚类,回归,降维

https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
分类和回归
- 给定一个样本特征 , 我们希望预测其对应的属性值 , 如果 是离散的, 那么这就是一个分类问题,反之,如果 是连续的实数, 这就是一个回归问题。
- 分类(classification)有监督学习的两大应用之一,产生离散的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。(即有目标和标签,能判断目标特征是属于哪一个类型)
- 回归(regression)有监督学习的两大应用之一,产生连续的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断此人20年后今后的经济能力”的结果,结果是连续的,往往得到一条回归曲线。当输入自变量不同时,输出的因变量非离散分布(不仅仅是一条线性直线,多项曲线也是回归曲线)。
分类:SVM (支持向量机) , SGD (随机梯度下降算法), Bayes (贝叶斯估计), Ensemble, KNN 等
回归:SVR, SGD, Ensemble 等算法,以及其它线性回归算法。
聚类
- 如果给定一组样本特征 , 我们没有对应的属性值 , 而是想发掘这组样本在二维空间的分布,比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
- 聚类(clustering)无监督学习的结果。聚类的结果将产生一组集合,集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异。
没有标准参考的学生给书本分的类别,表示自己认为这些书可能是同一类别的(具体什么类别不知道,没有标签和目标,即不是判断书的好坏(目标,标签),只能凭借特征而分类)。
聚类也是分析样本的属性, 有点类似classification, 不同的就是classification 在预测之前是知道 的范围, 或者说知道到底有几个类别, 而聚类是不知道属性的范围的。classification 也常常被称supervised learning(有监督学习)分类和回归都是监督学习, 而clustering就被称为unsupervised learning(无监督学习)常见的有聚类和关联规则。 clustering 事先不知道样本的属性范围,只能凭借样本在特征空间的分布来分析样本的属性。这种问题一般更复杂。而常用的算法包括 k-means (K-均值), GMM (高斯混合模型) 等。
降维
如果我们想用维数更低的子空间来表示原来高维的特征空间, 那么这就是降维问题。降维是机器学习另一个重要的领域, 降维有很多重要的应用, 特征的维数过高, 会增加训练的负担与存储空间, 降维就是希望去除特征的冗余, 用更加少的维数来表示特征.降维算法最基础的就是PCA了, 后面的很多算法都是以PCA为基础演化而来。
3、机器学习、数据分析、数据挖掘区别与联系

4、机器学习分类

有监督学习
- 判别式模型(Discriminative Model):直接对条件概率p(y|x)进行建模,常见判别模型有:
线性回归、决策树、支持向量机SVM、k近邻、神经网络等; - 生成式模型(Generative Model):对联合分布概率p(x,y)进行建模,常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
- 生成式模型更普适;判别式模型更直接,目标性更强
- 生成式模型关注数据是如何产生的,寻找的是数据分布模型;判别式模型关注的数据的差异性,寻找的是
分类面。 - 由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型
无监督学习
- 无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
- 无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出必要的标签信息。
半监督模型
- 主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。
- SSL的成立依赖于模型假设,主要分为三大类:平滑假设、聚类假设、流行假设;其中流行假设更具有普片性。
- SSL类型的算法主要分为四大类:半监督分类、半监督回归、半监督聚类、半监
督降维。
缺点:抗干扰能力弱,仅适合于实验室环境,其现实意义还没有体现出来;未来的发展主要是聚焦于新模型假设的产生。
5、机器学习十大算法

6、评估标准
指标


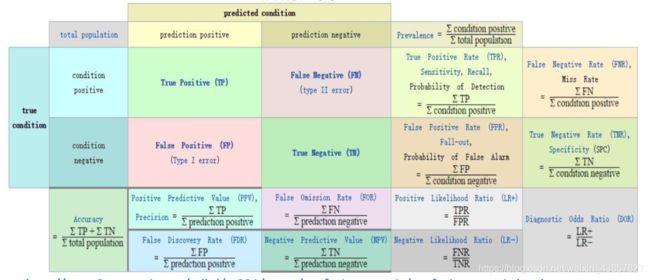
混淆矩阵:
http://www2.cs.uregina.ca/~dbd/cs831/notes/confusion_matrix/confusion_matrix.html
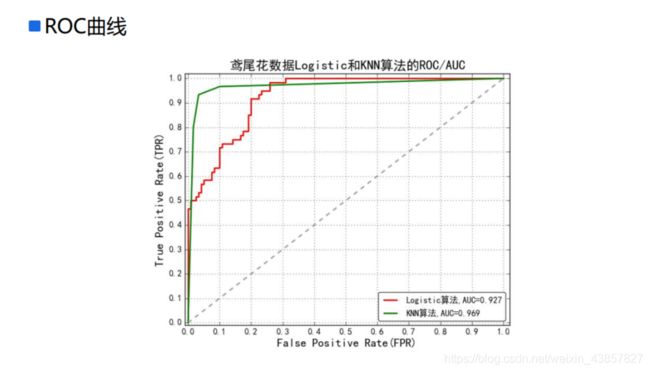
ROC曲线
ROC(Receiver Operating Characteristic)最初源于20世纪70年代的信号检测理论,描述的是分类混淆矩阵中FPR-TPR两个量之间的相对变化情况,ROC曲线的纵轴是“真正例率”(True Positive Rate 简称TPR),横轴是“假正例率” (False Positive Rate 简称FPR)。
如果二元分类器输出的是对正样本的一个分类概率值,当取不同阈值时会得到不同的混淆矩阵,对应于ROC曲线上的一个点。那么ROC曲线就反映了FPR与TPR之间权衡的情况,通俗地来说,即在TPR随着FPR递增的情况下,谁增长得更快,快多少的问题。TPR增长得越快,曲线越往上屈,AUC就越大,反映了模型的分类性能就越好。当正负样本不平衡时,这种模型评价方式比起一般的精确度评价方式的好处尤其显著。
AUC值
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。**0.5 < AUC < 1,优于随机猜测。**这个分类器(模型)妥善设定阈值的话,能有预测价值。AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。

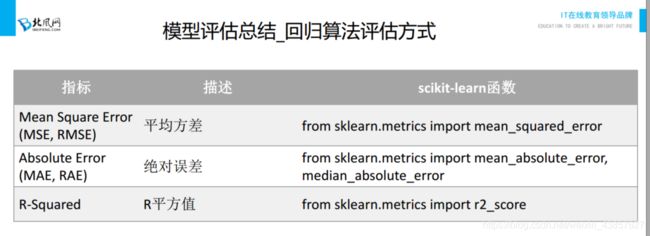


7、文本样本抽取

