Python数据处理工具 ——Pandas(数据的预处理)
0、前言
本文将介绍强大的数据处理模块Pandas,该模块可以帮助数据分析师轻松地解决数据的预处理问题,如数据类型的转换、缺失值的处理、描述性统计分析、数据的汇总等。
通过本章内容的学习,读者将会掌握如下知识点,进而在数据处理过程中做到游刃有余,为后续的数据分析或机器学习做准备:
- 两种重要的数据结构,即序列和数据框;
- 如何读取外部数据(如文本文件、电子表格或数据库中的数据);
- 数据类型转换及描述性统计分析;
- 字符型与日期型数据的处理;
- 常见的数据清洗方法;
- 如何应用iloc、loc、与ix完成数据子集的生成;
- 实现Excel中的透视表操作;
- 多表之间的合并与连接;
- 数据集的分组聚合操作。
1、序列与数据框的构造
Pandas模块的核心操作对象就是序列(Series)和数据框(DataFrame)。序列可以理解为数据集中的一个字段,数据框是指含有至少两个字段(或序列)的数据集。首先需要向读者说明哪些方式可以构造序列和数据框,之后才能实现基于序列和数据框的处理和操作。
1.1 构造序列
构造一个序列可以使用如下方式实现:
- 通过同质的列表或元组构建。
- 通过字典构建。
- 通过Numpy中的一维数组构建。
- 通过数据框DataFrame中的某一列构建。
为了使读者能够理解上面所提到的四种构造方法,这里通过具体的代码案例加以解释和说明:
# 导入模块
import pandas as pd
import numpy as np
# 构造序列
gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])
gdp2 = pd.Series({
'北京':2.8,'上海':3.01,'广东':8.99,'江苏':8.59,'浙江':5.18})
gdp3 = pd.Series(np.array((2.8,3.01,8.99,8.59,5.18)))
print(gdp1)
print(gdp2)
print(gdp3)
结果:
0 2.80
1 3.01
2 8.99
3 8.59
4 5.18
dtype: float64
北京 2.80
上海 3.01
广东 8.99
江苏 8.59
浙江 5.18
dtype: float64
0 2.80
1 3.01
2 8.99
3 8.59
4 5.18
dtype: float64
由于数据框的知识点还没有介绍到,上面的代码展示的是通过Series函数将列表、字典和一维数组转换为序列的过程。不管是列表、元组还是一维数组,构造的序列结果都是第一个打印的样式。该样式会产生两列,第一列属于序列的行索引(可以理解为行号),自动从0开始,第二列才是序列的实际值。通过字典构造的序列就是第二个打印样式,仍然包含两列,所不同的是第一列不再是行号,而是具体的行名称(label),对应到字典中的键,第二列是序列的实际值,对应到字典中的值。
序列与一维数组有极高的相似性,获取一维数组元素的所有索引方法都可以应用在序列上,而且数组的数学和统计函数也同样可以应用到序列对象上,不同的是,序列会有更多的其他处理方法。下面通过几个具体的例子来加以测试:
# 取出gdp1中的第一、第四和第五个元素
print('行号风格的序列:\n',gdp1[[0,3,4]])
# 取出gdp2中的第一、第四和第五个元素
print('行名称风格的序列:\n',gdp2[[0,3,4]])
# 取出gdp2中上海、江苏和浙江的GDP值
print('行名称风格的序列:\n',gdp2[['上海','江苏','浙江']])
# 数学函数--取对数
print('通过numpy函数:\n',np.log(gdp1))
# 平均gdp
print('通过numpy函数:\n',np.mean(gdp1))
print('通过序列的方法:\n',gdp1.mean())
结果:
行号风格的序列:
0 2.80
3 8.59
4 5.18
dtype: float64
行名称风格的序列:
北京 2.80
江苏 8.59
浙江 5.18
dtype: float64
行名称风格的序列:
上海 3.01
江苏 8.59
浙江 5.18
dtype: float64
通过numpy函数:
0 1.029619
1 1.101940
2 2.196113
3 2.150599
4 1.644805
dtype: float64
通过numpy函数:
5.714
通过序列的方法:
5.714
针对上面的代码需要说明几点,如果序列是行名称风格,既可以使用位置(行号)索引,又可以使用标签(行名称)索引;如果需要对序列进行数学函数的运算,一般首选numpy模块,因为Pandas模块在这方面比较缺乏;如果是对序列做统计运算,既可以使用numpy模块中的函数,也可以使用序列的“方法”,作者一般首选序列的“方法”,因为序列的“方法”更加丰富,如计算序列的偏度、峰度等,而Numpy是没有这样的函数的。
1.2 构造数据框
前面提到,数据框实质上就是一个数据集,数据集的行代表每一条观测,数据集的列则代表各个变量。在一个数据框中可以存放不同数据类型的序列,如整数型、浮点型、字符型和日期时间型,而数组和序列则没有这样的优势,因为它们只能存放同质数据。构造一个数据库可以应用如下方式:
- 通过嵌套的列表或元组构造。
- 通过字典构造。
- 通过二维数组构造。
- 通过外部数据的读取构造。
接下来通过几个简单的例子来说明数据框的构造:
# 构造数据框
df1 = pd.DataFrame([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']])
df2 = pd.DataFrame({
'姓名':['张三','李四','王二'],'年龄':[23,27,26],'性别':['男','女','女']})
df3 = pd.DataFrame(np.array([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']]))
print('嵌套列表构造数据框:\n',df1)
print('字典构造数据框:\n',df2)
print('二维数组构造数据框:\n',df3)
结果:
嵌套列表构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
字典构造数据框:
姓名 年龄 性别
0 张三 23 男
1 李四 27 女
2 王二 26 女
二维数组构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
构造数据框需要使用到Pandas模块中的DataFrame函数,如果通过嵌套列表或元组构造数据框,则需要将数据框中的每一行观测作为嵌套列表或元组的元素;如果通过二维数组构造数据框,则需要将数据框的每一行写入到数组的行中;如果通过字典构造数据框,则字典的键构成数据框的变量名,对应的值构成数据框的观测。尽管上面的代码都可以构造数据框,但是将嵌套列表、元组或二维数组转换为数据框时,数据框是没有具体的变量名的,只有从0到N的列号。所以,如果需要手工构造数据框的话,一般首选字典方法。剩下一种构造数据框的方法并没有在代码中体现,那就是外部数据的读取,这个内容将在下一节中重点介绍。
2、外部数据的读取
很显然,每次通过手工构造数据框是不现实的,在实际工作中,更多的情况则是通过Python读取外部数据集,这些数据集可能包含在本地的文本文件(如csv、txt等)、电子表格Excel和数据库中(如MySQL、SQL Server等)。本节内容就是重点介绍如何基于Pandas模块实现文本文件、电子表格和数据库数据的读取。
2.1 文本文件的读取
如果读者需要使用Python读取txt或csv格式中的数据,可以使用Pandas模块中的read_table函数或read_csv函数。这里的“或”并不是指每个函数只能读取一种格式的数据,而是这两种函数均可以读取文本文件的数据。由于这两个函数在功能和参数使用上类似,因此这里仅以read_table函数为例,介绍该函数的用法和几个重要参数的含义。
pd.read_table(filepath_or_buffer, sep='/t', header='infer', names=None, index_col=None,
usecols=None, dtype=None, converters=None, skiprows=None,
skipfooter=None, nrows=None, na_values=None, skip_blank_lines=True,
parse_dates=False, thousands=None, comment=None, encoding=None)
- filepath_or_buffer:指定txt文件或csv文件所在的具体路径。
- sep:指定原数据集中各字段之间的分隔符,默认为Tab制表符。
- header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称。
- names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头。
- index_col:指定原数据集中的某些列作为数据框的行索引(标签)。
- usecols:指定需要读取原数据集中的哪些变量名。
- dtype:读取数据时,可以为原数据集的每个字段设置不同的数据类型。
- converters:通过字典格式,为数据集中的某些字段设置转换函数。
- skiprows:数据读取时,指定需要跳过原数据集开头的行数。
- skipfooter:数据读取时,指定需要跳过原数据集末尾的行数。
- nrows:指定读取数据的行数。
- na_values:指定原数据集中哪些特征的值作为缺失值。
- skip_blank_lines:读取数据时是否需要跳过原数据集中的空白行,默认为True。
- parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
- thousands:指定原始数据集中的千分位符。
- comment:指定注释符,在读取数据时,如果碰到行首指定的注释符,则跳过改行。
- encoding:如果文件中含有中文,有时需要指定字符编码。
为了说明read_table函数中一些参数所起到的作用,这里构造一个稍微复杂点的数据集用于测试,数据存放在txt中,具体如图1所示。
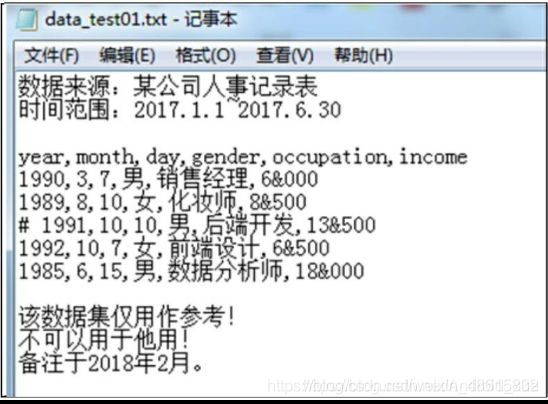
图1所呈现的txt格式数据集存在一些常见的问题,具体如下:
- 数据集并不是从第一行开始,前面几行实际上是数据集的来源说明,读取数据时需要注意什么问题。
- 数据集的末尾3行仍然不是需要读入的数据,如何避免后3行数据的读入。
- 中间部分的数据,第四行前加了#号,表示不需要读取该行,该如何处理。
- 数据集中的收入一列,千分位符是&,如何将该字段读入为正常的数值型数据。
- 如果需要将year、month和day三个字段解析为新的birthday字段,该如何做到。
- 数据集中含有中文,一般在读取含中文的文本文件时都会出现编码错误,该如何解决。
针对这样一个复杂的数据集,该如何通过read_table函数将数据正常读入到Python内存中,并构成一个合格的数据框呢?这里给出具体的数据读入代码,希望读者能够理解其中每一个参数所起到的作用:
# 读取文本文件中的数据
user_income = pd.read_table(r'C:\Users\Administrator\Desktop\data_test01.txt', sep = ',',
parse_dates={
'birthday':[0,1,2]},skiprows=2, skipfooter=3,
comment='#', encoding='utf8', thousands='&',engine='python')
user_income
说明:后面的engine='python’是系统提示让加的,如果不加,就会提醒,让加:
D:\developtools\software\anaconda\lib\site-packages\ipykernel_launcher.py:4: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support skipfooter; you can avoid this warning by specifying engine='python'.
after removing the cwd from sys.path.
结果:

读取的数据如表1所示。代码说明:由于read_table函数在读取数据时,默认将字段分隔符sep设置为Tab制表符,而原始数据集是用逗号分割每一列,所以需要改变sep参数;parse_dates参数通过字典实现前三列的日期解析,并合并为新字段birthday;skiprows和skipfooter参数分别实现原数据集开头几行和末尾几行数据的跳过;由于数据部分的第四行前面加了#号,因此通过comment参数指定跳过的特殊行;这里仅改变字符编码参数encoding是不够的,还需要将原始的txt文件另存为UTF-8格式;最后,对于收入一列,由于千分位符为&,因此为了保证数值型数据的正常读入,需要设置thousands参数为&。
2.2 电子表格的读取
还有一种常见的本地数据格式,那就是Excel电子表格,如果读者在学习或工作中需要使用Python分析某个Excel表格数据,该如何完成第一步的数据读取工作呢?本节将运用Pandas模块中的read_excel函数,教读者完美地读取电子表格数据。首先,介绍该函数的用法及几个重要参数的含义:
pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0,
index_col=None, name=None, parse_cols=None, parse_dates=False,
na_valuses=None, thousands=None, convert_float=True)
- io:指定电子表格的具体路径。
- sheetname:指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体的Sheet名称。
- header:是否需要将数据集的第一行用作表头,默认为是需要的。
- skiprows:读取数据时,指定跳过的开始行数。
- skip_footer:读取数据时,指定跳过的末尾行数。
- index_col:指定哪些列用作数据框的行索引(标签)。
- names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头。
- parse_cols:指定需要解析的字段。
- parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
- na_values:指定原始数据中哪些特殊值代表了缺失值。
- thousands:指定原始数据集中的千分位符。
- convert_float:默认将所有的数值型字段转换为浮点型字段。
- converters:通过字典的形式,指定某些列需要转换的形式。
如图2所示,该数据集反映的是儿童类服装的产品信息。在读取数据时需要注意两点:一点是该表没有表头,如何读数据的同时就设置好具体的表头;另一点是数据集的第一列实际上是字符型的字段,如何避免数据读入时自动变成数值型字段。

child_cloth = pd.read_excel(io = r'C:\Users\Administrator\Desktop\data_test02.xlsx', header = None,
names = ['Prod_Id','Prod_Name','Prod_Color','Prod_Price'], converters = {
0:str})
child_cloth
结果:

这里需要重点说明的是converters参数,通过该参数可以指定某些变量需要转换的函数。很显然,原始数据集中的商品ID是字符型的,如果不将该参数设置为{0:str},读入的数据与原始的数据集就不一致了(结果就会变为如下表:)。

2.3 数据库数据的读取
绝大多数公司都会选择将数据存入数据库中,因为数据库既可以存放海量数据,又可以非常便捷地实现数据的查询。本节将以MySQL和SQL Server为例,教会读者如何使用Pandas模块和对应的数据库模块(分别是pymysql模块和pymssql模块,如果读者的Python没有安装这两个模块,需要通过cmd命令输入pip install pymysql和pip install pysmsql)实现数据的连接与读取。
首先需要介绍pymysql模块和pymssql模块中的连接函数connect,虽然两个模块中的连接函数名称一致,但函数的参数并不完全相同,所以需要分别介绍函数用法和几个重要参数的含义:
(1)pymysql中的connect
pymysql.connect(host=None, user=None, password='', database=None, port=0, charset='')
- host:指定需要访问的MySQL服务器。
- user:指定访问MySQL数据库的用户名。
- password:指定访问MySQL数据库的密码。
- database:指定访问MySQL数据库的具体库名。
- port:指定访问MySQL数据库的端口号。
- charset:指定读取MySQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为“utf8”或“gbk”。
(2)pymssql中的connect
pymssql.connect(server=None, user=None, password=None, database=None, charset=None)
从两个模块的connect函数看,两者几乎没有差异,而且参数含义也是一致的,所不同的是pymysql模块中connect函数的host参数表示需要访问的服务器,而pymssql函数中对应的参数是server。为了简单起见,以本地电脑中的MySQL和SQL Server为例,演示一遍如何使用Python连接数据库的操作(如果读者需要在自己电脑上操作,必须确保你的电脑中已经安装了这两种数据库)。图3、图4所示分别是MySQL和SQL Server数据库中的数据表。


# 导入模块
import pymysql
# 连接MySQL数据库
conn = pymysql.connect(host='localhost', user='root', password='1q2w3e4r',
database='test', port=3306, charset='utf8')
# 读取数据
user = pd.read_sql('select * from topy', conn)
# 关闭连接
conn.close()
# 数据输出
user

如上结果所示,将数据库中的数据读入到了Python中。由于MySQL的原数据集中含有中文,为了避免乱码的现象,将connect函数中的chartset参数设置为utf8。读取数据时,需要用到Pandas模块中的read_sql函数,该函数至少传入两个参数,一个是读取数据的查询语句(sql),另一个是连接桥梁(con);在读取完数据之后,请务必关闭连接conn,因为它会一直占用电脑的资源,影响电脑的运行效率。
# 导入第三方模块
import pymssql
# 连接SQL Server数据库
connect = pymssql.connect(server = 'localhost', user = '', password = '',
database = 'train', charset = 'utf8')
# 读取数据
data = pd.read_sql("select * from sec_buildings where direction = '朝南'", con=connect)
# 关闭连接
connect.close()
# 数据输出
data.head()

如上所示,连接SQL Server的代码与MySQL的代码基本相同,由于访问SQL Server不需要填入用户名和密码,因此user参数和password参数需要设置为空字符;在读取数据时,可以写入更加灵活的SQL代码,如上代码中的SQL语句附加了数据的筛选功能,即所有朝南的二手房;同样,数据导入后,仍然需要关闭连接。
3、数据类型转换及描述统计
也许读者通过第2节的学习掌握了如何将常用的外部数据读入到Python中的技能,但是你可能并不了解该数据,所以需要进一步学习Pandas模块中的其他知识点。本节内容主要介绍如何了解数据,例如读入数据的规模如何、各个变量都属于什么数据类型、一些重要的统计指标对应的值是多少、离散变量各唯一值的频次该如何统计等。下面以某平台二手车信息为例:
# 数据类型转换及描述统计
# 数据读取
sec_cars = pd.read_table(r'D:\PyProject\Pandas测试\sec_cars.csv', sep = ',')
# 预览数据的前五行
sec_cars.head()
# 查看数据的行列数
print('数据集的行列数:\n',sec_cars.shape)
# 查看数据集每个变量的数据类型
print('各变量的数据类型:\n',sec_cars.dtypes)
忽然报错了:
OSError: Initializing from file failed
原因:
路径中包含了中文
解决方法(这两种方式都可以):
1、修改为英文路径
2、f = open(‘我的文件.csv’)
res = pd.read_table(f)
# 数据类型转换及描述统计
# 数据读取
sec_cars = pd.read_table(r'D:\PyProject\pandas\sec_cars.csv', sep = ',')
# 预览数据的前五行
sec_cars.head()
结果:
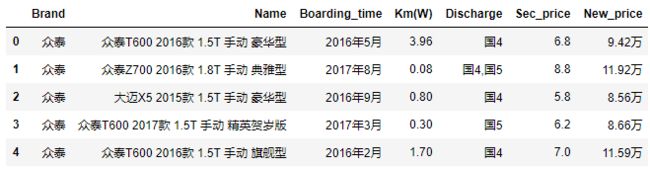
表5所示就是读入的二手车信息,如果读者只需要预览数据的几行信息,可以使用head方法和tail方法。如上代码中,head方法可以返回数据集的开头5行;如果读者需要查看数据集的末尾5行,可以使用tail方法。进一步,如果还想知道数据集有多少观测和多少变量,以及每个变量都是什么数据类型,可以按如下代码得知:
# 查看数据的行列数
print('数据集的行列数:\n',sec_cars.shape)
# 查看数据集每个变量的数据类型
print('各变量的数据类型:\n',sec_cars.dtypes)
结果:
数据集的行列数:
(10984, 7)
各变量的数据类型:
Brand object
Name object
Boarding_time object
Km(W) float64
Discharge object
Sec_price float64
New_price object
dtype: object
结果如上,该数据集一共包含了10 948条记录和7个变量,除二手车价格Sec_price和行驶里程数Km(W)为浮点型数据之外,其他变量均为字符型变量。但是,从表5-5来看,二手车的上牌时间Boarding_time应该为日期型,新车价格New_price应该为浮点型,为了后面的数据分析,需要对这两个变量进行类型的转换,具体操作如下:
# 修改二手车上牌时间的数据类型
sec_cars.Boarding_time = pd.to_datetime(sec_cars.Boarding_time, format = '%Y年%m月')
# 修改二手车新车价格的数据类型
sec_cars.New_price = sec_cars.New_price.str[:-1].astype('float')
# 重新查看各变量数据类型
sec_cars.dtypes
结果:
Brand object
Name object
Boarding_time datetime64[ns]
Km(W) float64
Discharge object
Sec_price float64
New_price float64
dtype: object
如上结果所示,经过两行代码的处理,上牌时间Boarding_time更改为了日期型数据,新车价格New_price更改为了浮点型数据。需要说明的是,Pandas模块中的to_datetime函数可以通过format参数灵活地将各种格式的字符型日期转换成真正的日期数据;由于二手车新车价格含有“万”字,因此不能直接转换数据类型,为达到目的,需要三步走,首先通过str方法将该字段转换成字符串,然后通过切片手段,将“万”字剔除,最后运用astype方法,实现数据类型的转换。
接下来,需要对数据做到心中有数,即通过基本的统计量(如最小值、均值、中位数、最大值等)描述出数据的特征。关于数据的描述性分析可以使用describe方法:
# 数据的描述性统计
sec_cars.describe()
结果:

如上结果所示,通过describe方法,直接运算了数据框中所有数值型变量的统计值,包括非缺失个数、平均值、标准差、最小值、下四分位数、中位数、上四分位数和最大值。以二手车的售价Sec_price为例,平均价格为25.7万(很明显会受到极端值的影响)、中位数价格为10.2万(即一半的二手车价格不超过10.2万)、最高售价为808万、最低售价为0.65万、绝大多数二手车价格不超过23.8万(上四分位数75%对应的值)。
以上都是有关数据的统计描述,但并不能清晰地知道数据的形状分布,如数据是否有偏以及是否属于“尖峰厚尾”的特征,为了一次性统计数值型变量的偏度和峰度,读者可以参考如下代码:
# 数据的形状特征
# 挑出所有数值型变量
num_variables = sec_cars.columns[sec_cars.dtypes !='object'][1:]
# 自定义函数,计算偏度和峰度
def skew_kurt(x):
skewness = x.skew()
kurtsis = x.kurt()
# 返回偏度值和峰度值
return pd.Series([skewness,kurtsis], index = ['Skew','Kurt'])
# 运用apply方法
sec_cars[num_variables].apply(func = skew_kurt, axis = 0)
结果:

如上结果所示正是每个数值型变量的偏度和峰度,这三个变量都属于右偏(因为偏度值均大于0),而且三个变量也是尖峰的(因为峰度值也都大于0)。代码说明:columns方法用于返回数据集的所有变量名,通过布尔索引和切片方法获得所有的数值型变量;在自定义函数中,运用到了计算偏度的skew方法和计算峰度的kurt方法,然后将计算结果组合到序列中;最后使用apply方法,该方法的目的就是对指定轴(axis=0,即垂直方向的各列)进行统计运算(运算函数即自定义函数)。
以上的统计分析全都是针对数值型变量的,对于数据框中的字符型变量(如二手车品牌Brand、排放量Discharge等)该如何做统计描述呢?仍然可以使用describe方法,所不同的是,需要设置该方法中的include参数,具体代码如下:
# 离散型变量的统计描述
sec_cars.describe(include = ['object'])
结果:

如上结果包含离散变量的四个统计值,分别是非缺失观测数、唯一水平数、频次最高的离散值和具体的频次。以二手车品牌为例,一共有10 984辆二手车,包含104种品牌,其中别克品牌最多,高达1 346辆。需要注意的是,如果对离散型变量作统计分析,需要将“object”以列表的形式传递给include参数。
对于离散型变量,运用describe方法只能得知哪个离散水平属于“明星”值。如果读者需要统计的是各个离散值的频次,甚至是对应的频率,该如何计算呢?这里直接给出如下代码(以二手车品的标准排量Discharge为例):
# 离散变量频次统计
Freq = sec_cars.Discharge.value_counts()
Freq_ratio = Freq/sec_cars.shape[0]
Freq_df = pd.DataFrame({
'Freq':Freq,'Freq_ratio':Freq_ratio})
Freq_df.head()
结果:

如上结果所示,构成的数据框包含两列,分别是二手车各种标准排量对应的频次和频率,数据框的行索引(标签)就是二手车不同的标准排量。如果读者需要把行标签设置为数据框中的列,可以使用reset_index方法,具体操作如下:
# 将行索引重设为变量
Freq_df.reset_index(inplace = True)
Freq_df.head()

reset_index方法的使用还是比较频繁的,它可以非常方便地将行标签转换为数据框的变量。在如上代码中,将reset_index方法中的inplace参数设置为True,表示直接对原始数据集进行操作,影响到原数据集的变化,否则返回的只是变化预览,并不会改变原数据集。
4、字符与日期数据的处理
在本节中将会向读者介绍如何基于数据框操作字符型变量,希望对读者在后期的学习和工作中处理字符串时有所帮助。同时,本节也会介绍有关日期型数据的处理,比方说,如何从日期型变量中取出年份、月份、星期几等,如何计算两个日期间的时间差。 为了简单起见,这里就以自己手工编的数据为例,展示如何通过Pandas模块中的知识点完成字符串和日期数据的处理。表11所示就是即将处理的数据。

针对如上数据,读者可以在不看下方代码的情况下尝试着回答这些关于字符型及日期型的问题:
- 如何更改出生日期birthday和手机号tel两个字段的数据类型。
- 如何根据出生日期birthday和开始工作日期start_work两个字段新增年龄和工龄两个字段。
- 如何将手机号tel的中间四位隐藏起来。 如何根据邮箱信息新增邮箱域名字段。
- 如何基于other字段取出每个人员的专业信息。
# 数据读入
df = pd.read_excel(r'D:\PyProject\pandas\data_test03.xlsx')
# 各变量数据类型
print(df.dtypes)
# 将birthday变量转换为日期型
df.birthday = pd.to_datetime(df.birthday, format = '%Y/%m/%d')
# 将手机号转换为字符串
df.tel = df.tel.astype('str')
# 新增年龄和工龄两列
df['age'] = pd.datetime.today().year - df.birthday.dt.year
df['workage'] = pd.datetime.today().year - df.start_work.dt.year
# 将手机号中间四位隐藏起来
df.tel = df.tel.apply(func = lambda x : x.replace(x[3:7], '****'))
# 取出邮箱的域名
df['email_domain'] = df.email.apply(func = lambda x : x.split('@')[1])
# 取出用户的专业信息
df['profession'] = df.other.str.findall('专业:(.*?),')
# 去除birthday、start_work和other变量
df.drop(['birthday','start_work','other'], axis = 1, inplace = True)
df.head()
结果:
name object
gender object
birthday object
start_work datetime64[ns]
income int64
tel int64
email object
other object
dtype: object

如上结果所示,回答了上面提到的5个问题。为了使读者理解上面的代码,接下来对代码做详细的解释:
- 通过dtypes方法返回数据框中每个变量的数据类型,由于出生日期birthday为字符型、手机号tel为整型,不便于第二问和第三问的回答,所以需要进行变量的类型转换。这里通过Pandas模块中的to_datetime函数将birthday转换为日期型(必须按照原始的birthday格式设置format参数);使用astype方法将tel转换为字符型。
- 对于年龄和工龄的计算,需要将当前日期与出生日期和开始工作日期进行减法运算,而当前日期的获得,则使用了Pandas子模块datetime中的today函数。由于计算的是相隔的年数,所以还需进一步取出日期中的年份(year方法)。需要注意的是,对于birthday和start_work变量,使用year方法之前,还需使用dt方法,否则会出错。
- 隐藏手机号的中间四位和衍生出邮箱域名变量,都是属于字符串的处理范畴,两个问题的解决所使用的方法分布是字符串中的替换法(replace)和分割法(split)。由于替换法和分割法所处理的对象都是变量中的每一个观测,属于重复性工作,所以考虑使用序列的apply方法。需要注意的是,apply方法中的func参数都是使用匿名函数,对于隐藏手机号中间四位的思路就是用星号替换手机号的中间四位;对于邮箱域名的获取,其思路就是按照邮箱中的@符风格,然后取出第二个元素(列表索引为1)。
- 从other变量中获取人员的专业信息,该问题的解决使用了字符串的正则表达式,不管是字符串“方法”还是字符串正则,在使用前都需要对变量使用一次str方法。由于findall返回的是列表值,因此衍生出的email_domain字段值都是列表类型,如果读者不想要这个中括号,可以参考第三问或第四问的解决方案,这里就不再赘述了。
- 如果需要删除数据集中的某些变量,可以使用数据框的drop方法。该方法接受的第一个参数,就是被删除的变量列表,尤其要注意的是,需要将axis参数设置为1,因为默然drop方法是用来删除数据框中的行记录。
关于更多数据框中字符型变量的处理“方法”可以参考numpy那一章,最后,再针对日期型数据罗列一些常用的“方法”,见表13,希望对读者的学习和记忆有所帮助。

接下来,挑选几个日期处理“方法”用以举例说明:
# 常用日期处理方法
dates = pd.to_datetime(pd.Series(['1989-8-18 13:14:55','1995-2-16']), format = '%Y-%m-%d %H:%M:%S')
print('返回日期值:\n',dates.dt.date)
print('返回季度:\n',dates.dt.quarter)
print('返回几点钟:\n',dates.dt.hour)
print('返回年中的天:\n',dates.dt.dayofyear)
print('返回年中的周:\n',dates.dt.weekofyear)
print('返回星期几的名称:\n',dates.dt.weekday_name)
print('返回月份的天数:\n',dates.dt.days_in_month)
结果:
返回日期值:
0 1989-08-18
1 1995-02-16
dtype: object
返回季度:
0 3
1 1
dtype: int64
返回几点钟:
0 13
1 0
dtype: int64
返回年中的天:
0 230
1 47
dtype: int64
返回年中的周:
0 33
1 7
dtype: int64
返回星期几的名称:
0 Friday
1 Thursday
dtype: object
返回月份的天数:
0 31
1 28
dtype: int64
5、常用的数据清洗方法
在数据处理过程中,一般都需要进行数据的清洗工作,如数据集是否存在重复、是否存在缺失、数据是否具有完整性和一致性、数据中是否存在异常值等。当发现数据中存在如上可能的问题时,都需要有针对性地处理,本节将重点介绍如何识别和处理重复观测、缺失值和异常值。
5.1 重复观测处理
重复观测,顾名思义是指观测行存在重复的现象,重复观测的存在会影响数据分析和挖掘结果的准确性,所以在数据分析和建模之前需要进行观测的重复性检验,如果存在重复观测,还需要进行重复项的删除。
在搜集数据过程中,可能会存在重复观测的出现,例如通过网络爬虫,就比较容易产生重复数据。如表14所示,就是通过爬虫获得某APP市场中电商类APP的下载量数据(部分),通过肉眼,是能够发现这10行数据中的重复项的,例如,唯品会出现了两次、当当出现了三次。如果搜集上来的数据不是10行,而是10万行,甚至更多时,就无法通过肉眼的方式检测数据是否存在重复项了。下面将介绍如何运用Python对读入的数据进行重复项检查,以及如何删除数据中的重复项。

# 数据清洗
# 数据读入
df = pd.read_excel(r'D:\PyProject\pandas\data_test04.xlsx')
# 重复观测的检测
print('数据集中是否存在重复观测:\n',any(df.duplicated()))
结果:
数据集中是否存在重复观测:
True
检测数据集的记录是否存在重复,可以使用duplicated方法进行验证,但是该方法返回的是数据集每一行的检验结果,即10行数据会返回10个bool值。很显然,这样也不能直接得知数据集的观测是否重复,为了能够得到最直接的结果,可以使用any函数。该函数表示的是在多个条件判断中,只要有一个条件为True,则any函数的结果就为True。正如结果所示,any函数的运用返回True值,说明该数据集是存在重复观测的。接下来,删除数据集中的重复观测:
# 删除重复项
df.drop_duplicates(inplace = True)
df
结果:
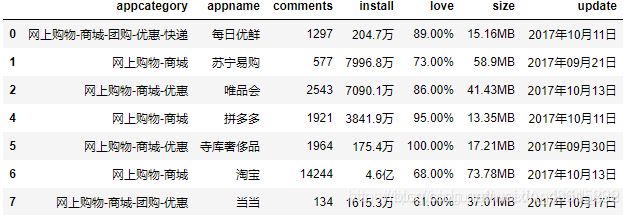
如表15所示,原先的10行观测在排重后得到7行,被删除的行号为3、8和9。同样,该方法中也有inplace参数,设置为True就表示直接在原始数据集上做操作。
5.2 缺失值处理
缺失值是指数据集中的某些观测存在遗漏的指标值,缺失值的存在同样会影响到数据分析和挖掘的结果。导致观测的缺失可能有两方面原因,一方面是人为原因(如记录过程中的遗漏、个人隐私而不愿透露等),另一方面是机器或设备的故障所导致(如断电或设备老化等原因)。
一般而言,当遇到缺失值(Python中用NaN表示)时,可以采用三种方法处置,分别是删除法、替换法和插补法。删除法是指当缺失的观测比例非常低时(如5%以内),直接删除存在缺失的观测,或者当某些变量的缺失比例非常高时(如85%以上),直接删除这些缺失的变量;替换法是指用某种常数直接替换那些缺失值,例如,对连续变量而言,可以使用均值或中位数替换,对于离散变量,可以使用众数替换;插补法是指根据其他非缺失的变量或观测来预测缺失值,常见的插补法有回归插补法、K近邻插补法、拉格朗日插补法等。
为了简单起见,本节就重点介绍删除法和替换法,采用的数据来自于某游戏公司的用户注册信息(仅以10行记录为例),见表16。

从表16展现的数据可知,该数据集存在4条缺失观测,行号分别是4、5、7和9,表中的缺失值用NaN表示。接下来要做的是如何判断数据集是否存在缺失值(尽管记录数少的时候可以清楚地发现):
# 数据读入
df = pd.read_excel(r'D:\PyProject\pandas\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
结果:
数据集中是否存在缺失值:
True
检测数据集是否存在重复观测使用的是isnull方法,该方法仍然是基于每一行的检测,所以仍然需要使用any函数,返回整个数据集中是否存在缺失的结果。从代码返回的结果看,该数据集确实是存在缺失值的。接下来分别使用两种方法实现数据集中缺失值的处理:
# 删除法之记录删除
df.dropna()

# 删除法之变量删除
df.drop('age', axis = 1)

如表17所示,左表(上面的表)为行删除法,即将所有含缺失值的行记录全部删除,使用dropna方法;右表(下面的)为变量删除法,由于原数据集中age变量的缺失值最多,所以使用drop方法将age变量删除。
# 替换法之前向替换
df.fillna(method = 'ffill')
结果:

# 替换法之后向替换
df.fillna(method = 'bfill')

缺失值的替换需要借助于fillna方法,该方法中的method参数可以接受’ffill’和’bfill’两种值,分别代表前向填充和后向填充。前向填充是指用缺失值的前一个值替换(如左表所示),而后向填充则表示用缺失值的后一个值替换(如右表所示)。右表中的最后一个记录仍包含缺失值,是因为后向填充法找不到该缺失值的后一个值用于替换。缺失值的前向填充或后向填充一般适用于时间序列型的数据集,因为这样的数据前后具有连贯性,而一般的独立性样本并不适用该方法。
# 替换法之常数替换
df.fillna(value = 0)

# 替换法之统计值替换
df.fillna(value = {
'gender':df.gender.mode()[0], 'age':df.age.mean(), 'income':df.income.median()})

另一种替换手段仍然是使用fillna方法,只不过不再使用method参数,而是使用value参数。左表是使用一个常数0替换所有的缺失值(有些情况是有用的,例如某人确实没有工作,故收入为0),但是该方法就是典型的“以点概面”,非常容易导致错误,例如结果中的性别莫名多出异样的0值;右表则是采用了更加灵活的替换方法,即分别对各缺失变量使用不同的替换值(需要采用字典的方式传递给value参数),性别使用众数替换,年龄使用均值替换,收入使用中位数替换。
需要说明的是,如上代码并没有实际改变df数据框的结果,因为dropna、drop和fillna方法并没有使inplace参数设置为True。读者可以在实际的学习和工作中挑选一个适当的缺失值处理方法,然后将该方法中的inplace参数设置为True,进而可以真正地改变你所处理的数据集。
5.3 异常值处理
异常值是指那些远离正常值的观测,即“不合群”观测。导致异常值的出现一般是人为的记录错误或者是设备的故障等,异常值的出现会对模型的创建和预测产生严重的后果。当然异常值也不一定都是坏事,有些情况下,通过寻找异常值就能够给业务带来良好的发展,如销毁“钓鱼”网站、关闭“薅羊毛”用户的权限等。
对于异常值的检测,一般采用两种方法,一种是n个标准差法,另一种是箱线图判别法。标准差法的判断公式是,其中为样本均值,σ为样本标准差,当n=2时,满足条件的观测就是异常值,当n=3时,满足条件的观测就是极端异常值;箱线图的判断公式是outlinear>Q3+nIQR或者outlinear
这两种方法的选择标准如下,如果数据近似服从正态分布时,优先选择n个标准差法,因为数据的分布相对比较对称;否则优先选择箱线图法,因为分位数并不会受到极端值的影响。当数据存在异常时,一般可以使用删除法将异常值删除(前提是异常观测的比例不能太大)、替换法(可以考虑使用低于判别上限的最大值或高于判别下限的最小值替换、使用均值或中位数替换等)。下面将以年为单位的太阳黑子个数为例(时间范围:1700—1988),识别并处理异常值:
# 数据读入
sunspots = pd.read_table(r'D:\PyProject\pandas\sunspots.csv', sep = ',')
# 异常值检测之标准差法
xbar = sunspots.counts.mean()
xstd = sunspots.counts.std()
print('标准差法异常值上限检测:\n',any(sunspots.counts > xbar + 2 * xstd))
print('标准差法异常值下限检测:\n',any(sunspots.counts < xbar - 2 * xstd))
# 异常值检测之箱线图法
Q1 = sunspots.counts.quantile(q = 0.25)
Q3 = sunspots.counts.quantile(q = 0.75)
IQR = Q3 - Q1
print('箱线图法异常值上限检测:\n',any(sunspots.counts > Q3 + 1.5 * IQR))
print('箱线图法异常值下限检测:\n',any(sunspots.counts < Q1 - 1.5 * IQR))
结果:
标准差法异常值上限检测:
True
标准差法异常值下限检测:
False
箱线图法异常值上限检测:
True
箱线图法异常值下限检测:
False
如上结果所示,不管是标准差检验法还是箱线图检验法,都发现太阳黑子数据中存在异常值,而且异常值都是超过上限临界值的。接下来,通过绘制太阳黑子数量的直方图和核密度曲线图,用于检验数据是否近似服从正态分布,进而选择一个最终的异常值判别方法:
# 导入绘图模块
import matplotlib.pyplot as plt
# 设置绘图风格
plt.style.use('ggplot')
# 绘制直方图
sunspots.counts.plot(kind = 'hist', bins = 30, density = True)
# 绘制核密度图
sunspots.counts.plot(kind = 'kde')
# 图形展现
plt.show()

如图6所示,不管是直方图还是核密度曲线,所呈现的数据分布形状都是有偏的,并且属于右偏。基于此,这里选择箱线图法来判定太阳黑子数据中的那些异常值。接下来要做的就是选用删除法或替换法来处理这些异常值,由于删除法的Python代码已经在5.2节的缺失值处理中介绍过,这里就使用替换法来处理异常值,即使用低于判别上限的最大值或高于判别下限的最小值替换,代码如下:
# 替换法处理异常值
print('异常值替换前的数据统计特征:\n',sunspots.counts.describe())
# 箱线图中的异常值判别上限
UL = Q3 + 1.5 * IQR
print('判别异常值的上限临界值:\n',UL)
# 从数据中找出低于判别上限的最大值
replace_value = sunspots.counts[sunspots.counts < UL].max()
print('用以替换异常值的数据:\n',replace_value)
# 替换超过判别上限异常值
sunspots.counts[sunspots.counts > UL] = replace_value
print('异常值替换后的数据统计特征:\n',sunspots.counts.describe())
结果:
异常值替换前的数据统计特征:
count 289.000000
mean 48.613495
std 39.474103
min 0.000000
25% 15.600000
50% 39.000000
75% 68.900000
max 190.200000
Name: counts, dtype: float64
判别异常值的上限临界值:
148.85000000000002
用以替换异常值的数据:
141.7
异常值替换后的数据统计特征:
count 289.000000
mean 48.066090
std 37.918895
min 0.000000
25% 15.600000
50% 39.000000
75% 68.900000
max 141.700000
Name: counts, dtype: float64
如果使用箱线图法判别异常值,则认定太阳黑子数目一年内超过148.85时即为异常值年份,对于这些年份的异常值使用141.7替换。为了比较替换前后的差异,将太阳黑子数量的统计值汇总到表20中。

由表20可知,对于异常值的替换,改变了原始数据的均值、标准差和最大值,并且这些值改变后都降低了,这是显而易见的,因为是将所有超过148.85的异常值改为了较低的141.7。
6、数据子集的获取
有时数据读入后并不是对整体数据进行分析,而是数据中的部分子集,例如,对于地铁乘客量可能只关心某些时间段的流量、对于商品的交易可能只需要分析某些颜色的价格变动、对于医疗诊断数据可能只对某个年龄段的人群感兴趣等。所以,该如何根据特定的条件实现数据子集的获取将是本节的主要内容。
通常,在Pandas模块中实现数据框子集的获取可以使用iloc、loc和ix三种“方法”,这三种方法既可以对数据行进行筛选,也可以实现变量的挑选,它们的语法可以表示成[rows_select,cols_select]。
iloc只能通过行号和列号进行数据的筛选,读者可以将iloc中的“i”理解为“integer”,即只能向[rows_select, cols_select]指定整数列表。该索引方式与数组的索引方式类似,都是从0开始,可以间隔取号,对于切片仍然无法取到上限。
loc要比iloc灵活一些,读者可以将loc中的“l”理解为“label”,即可以向[rows_select, cols_select]指定具体的行标签(行名称)和列标签(字段名)。注意,这里是标签不再是索引。而且,还可以将rows_select指定为具体的筛选条件,在iloc中是无法做到的。
ix是iloc和loc的混合,读者可以将ix理解为“mix”,该“方法”吸收了iloc和loc的优点,使数据框子集的获取更加灵活。为了使读者理解这三种方法的使用和差异,接下来通过具体的代码加以说明:
# 数据子集的获取
# 构造数据集
df1 = pd.DataFrame({
'name':['张三','李四','王二','丁一','李五'],
'gender':['男','女','女','女','男'],
'age':[23,26,22,25,27]}, columns = ['name','gender','age'])
df1
# 取出数据集的中间三行(即所有女性),并且返回姓名和年龄两列
df1.iloc[1:4,[0,2]]
df1.loc[1:3, ['name','age']]
df1.ix[1:3,[0,2]]
注意:ix方法已经过时了,建议使用前两个
结果:

如上结果所示,如果原始数据的行号与行标签(名称)一致,iloc、loc和ix三种方法都可以取出满足条件的数据子集。所不同的是,iloc运用了索引的思想,故中间三行的表示必须用1:4,因为切片索引取不到上限,同时,姓名和年龄两列也必须用数值索引表示;loc是指获取行或列的标签(名称),由于该数据集的行标签与行号一致,所以1:3就表示对应的3个行名称,而姓名和年龄两列的获取就不能使用数值索引了,只能写入具体的变量名称;ix则混合了iloc与loc的优点,如果数据集的行标签与行号一致,则ix对观测行的筛选与loc的效果一样,但是ix对变量名的筛选既可以使用对应的列号(如代码所示),也可以使用具体的变量名称。
假如数据集没有行号,而是具体的行名称,该如何使用这三种方法实现中间三行数据的获取?代码如下:
# 将员工的姓名用作行标签
df2 = df1.set_index('name')
df2
# 取出数据集的中间三行
df2.iloc[1:4,:]
df2.loc[['李四','王二','丁一'],:]
df2.ix[1:4,:]
结果:

注意,这时的数据集是以员工姓名作为行名称,不再是之前的行号,对于目标数据的返回同样可以使用iloc、loc和ix三种方法。对于iloc来说,不管什么形式的数据集都可以使用,始终表示行索引,即取哪些行下标的观测;loc就不能使用数值表示行标签了,因为此时数据集的行标签是姓名,所以需要写入中间三行对应的姓名;通过ix方法,既可以用行索引(如代码所示)表示,也可以用行标签表示,可根据读者的喜好选择。由于并没有对数据集的变量做任何限制,所以cols_select用英文冒号表示,代表取出数据集的所有变量。
很显然,在实际的学习和工作中,观测行的筛选很少是通过写入具体的行索引或行标签,而是对某些列做条件筛选,进而获得目标数据。例如,在上面的df1数据集中,如何返回所有男性的姓名和年龄,代码如下:
# 使用筛选条件,取出所有男性的姓名和年龄
# df1.iloc[df1.gender == '男',]
df1.loc[df1.gender == '男',['name','age']]
df1.ix[df1.gender == '男',['name','age']]
结果:
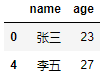
如果是基于条件的记录筛选,只能使用loc和ix两种方法。正如代码所示,对iloc方法的那行代码做注释,是因为iloc不允许使用条件筛选,这行代码是无法运行成功的。对变量名的筛选,loc必须指定具体的变量名,而ix既可以使用变量名,也可以使用字段的数值索引。
综上所述,ix方法几乎可以实现所有情况中数据子集的获取,是iloc和loc两种方法的优点合成体,而且对于行号与行名称一致的数据集来说(如df1数据集),名称索引的优先级在位置索引之前(如本节第一段代码中的df1.ix[1:3,[0,2]])。
7、透视表功能
相信读者在平时的学习或工作中经常会使用到Excel的透视表功能,该功能的主要目的就是实现数据的汇总统计。例如,按照某个分组变量统计商品的平均价格、销售数量、最大利润等,或者按照某两个分组变量构成统计学中的列联表(计数统计),甚至是基于多个分组变量统计各组合下的均值、中位数、总和等。如果你使用Excel,只需要简单的托拉拽就可以迅速地形成一张统计表,如图7所示(数据是关于珠宝的重量、颜色、纯度、价格、面积等)。

图7所呈现的就是基于单个分组变量实现的均值统计,读者只需将分组变量color拖入“行标签”框中、数值变量price拖入到“数值”框中,然后下拉“数值”单击“值字段设置”选择“平均值”的计算类型就可以实现均值的分组统计(因为默认是统计总和)。如果需要构造列联表(如图8所示),可以按照下方的步骤实现。

图8是关于频次的列联表,将分组变量clarity和cut分别拖至“行标签”框和“列标签”框,然后将其他任意一个变量拖入“数值”框中,接下来就是选择“计数”的计算类型。同理,如果需要生成多个分组变量的汇总表,只需将这些分组变量根据实际情况分散到“行标签”和“列标签”框中。
如果这样的汇总过程不是在Excel中,而是在Python中,该如何实现呢?Pandas模块提供了实现透视表功能的pivot_table函数,该函数简单易用,与Excel的操作思想完全一致,相信读者一定可以快速掌握函数的用法及参数含义。接下来,向读者介绍一下有关该函数的参数含义:
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None,
margins=False, dropna=True, margins_name='All')
- data:指定需要构造透视表的数据集。
- values:指定需要拉入“数值”框的字段列表。
- index:指定需要拉入“行标签”框的字段列表。
- columns:指定需要拉入“列标签”框的字段列表。
- aggfunc:指定数值的统计函数,默认为统计均值,也可以指定numpy模块中的其他统计函数。
- fill_value:指定一个标量,用于填充缺失值。
- margins:bool类型参数,是否需要显示行或列的总计值,默认为False。
- dropna:bool类型参数,是否需要删除整列为缺失的字段,默认为True。
- margins_name:指定行或列的总计名称,默认为All。
为了说明该函数的灵活功能,这里以上面的珠宝数据为例,重现Excel制作成的透视表。首先来尝试一下单个分组变量的均值统计,具体代码如下:
# 数据读取
diamonds = pd.read_table(r'D:\PyProject\pandas\diamonds.csv', sep = ',')
# 单个分组变量的均值统计
pd.pivot_table(data = diamonds, index = 'color', values = 'price', margins = True, margins_name = '总计')

如上结果所示就是基于单个分组变量color的汇总统计(price的均值),返回结果属于Pandas模块中的序列类型,该结果与Excel形成的透视表完全一致。接下来看看如何构造两个分组变量的列联表,代码如下所示:
# 两个分组变量的列联表
# 导入numpy模块
import numpy as np
pd.pivot_table(data = diamonds, index = 'clarity', columns = 'cut', values = 'carat',
aggfunc = np.size,margins = True, margins_name = '总计')

如表24所示,对于列联表来说,行和列都需要指定某个分组变量,所以index参数和columns参数都需要指定一个分组变量,并且统计的不再是某个变量的均值,而是观测个数,所以aggfunc参数需要指定numpy模块中的size函数。通过这样的参数设置,返回的是一个数据框对象,结果与Excel透视表完全一样。
8、表之间的合并与连接
在学习或工作中可能会涉及多张表的操作,例如将表结构相同的多张表纵向合并到大表中,或者将多张表的字段水平扩展到一张宽表中。如果你对数据库SQL语言比较熟悉的话,那表之间的合并和连接就非常简单了。对于多张表的合并,只需要使用UNION或UNION ALL关键词;对于多张表之间的连接,只需要使用INNER JOIN或者LEFT JOIN即可。
如果读者对表的合并和连接并不是很熟悉的话,可以查看图10。上图为两表之间的纵向合并,下图为两表之间的水平扩展并且为左连接操作。

需要注意的是,对于多表之间的纵向合并,必须确保多表的列数和数据类型一致;对于多表之间的水平扩展,必须保证多表要有共同的匹配字段(如图10中的ID变量)。图10中的NaN代表缺失,表示3号用户没有对应的考试科目和成绩。
Pandas模块同样提供了关于多表之间的合并和连接操作函数,分别是concat函数和merge函数,首先介绍一下这两个函数的用法和重要参数含义。
(1)合并函数concat
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None)
- objs:指定需要合并的对象,可以是序列、数据框或面板数据构成的列表。
- axis:指定数据合并的轴,默认为0,表示合并多个数据的行,如果为1,就表示合并多个数据的列。
- join:指定合并的方式,默认为outer,表示合并所有数据,如果改为inner,表示合并公共部分的数据。
- join_axes:合并数据后,指定保留的数据轴。
- ignore_index:bool类型的参数,表示是否忽略原数据集的索引,默认为False,如果设为True,就表示忽略原索引并生成新索引。
- keys:为合并后的数据添加新索引,用于区分各个数据部分。
针对合并函数concat,需要强调两点。一点是,如果纵向合并多个数据集,即使这些数据集都含有“姓名”变量,但变量名称不一致,如Name和name,通过合并后,将会得到错误的结果。另一点是join_axes参数的使用,例如纵向合并两个数据集df1和df2,可以写成pd.concat([df1,df2]),如果该参数等于[df1.index],就表示保留与df1行标签一样的数据,但需要配合axis=1一起使用;如果等于[df1.columns],就保留与df1列标签一样的数据,但不需要添加axis=1的约束。下面举例说明concat函数的使用:
# 构造数据集df1和df2
df1 = pd.DataFrame({
'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']})
df2 = pd.DataFrame({
'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']},)
# 数据集的纵向合并
pd.concat([df1,df2], keys = ['df1','df2'], )

# 如果df2数据集中的“姓名变量为Name”
df2 = pd.DataFrame({
'Name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
# 数据集的纵向合并
pd.concat([df1,df2])
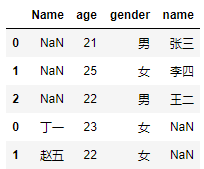
如上结果所示,为了区分合并后的df1数据集和df2数据集,代码中的concat函数使用了keys参数,如果再设置参数ignore_index为True,此时keys参数将不再有效。如上右表所示,就是由两个数据集的变量名称不一致(name和Name)所致,最终产生错误的结果。
(2)连接函数merge
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'))
- left:指定需要连接的主表。
- right:指定需要连接的辅表。
- how:指定连接方式,默认为inner内连,还有其他选项,如左连left、右连right和外连outer。
- on:指定连接两张表的共同字段。
- left_on:指定主表中需要连接的共同字段。
- right_on:指定辅表中需要连接的共同字段。
- left_index:bool类型参数,是否将主表中的行索引用作表连接的共同字段,默认为False。
- right_index:bool类型参数,是否将辅表中的行索引用作表连接的共同字段,默认为False。
- sort:bool类型参数,是否对连接后的数据按照共同字段排序,默认为False。
- suffixes:如果数据连接的结果中存在重叠的变量名,则使用各自的前缀进行区分。
该函数的最大缺点是,每次只能操作两张数据表的连接,如果有n张表需要连接,则必须经过n-1次的merge函数使用。接下来,为了读者更好地理解merge函数的使用,这里举例说明:
# 构造数据集
df3 = pd.DataFrame({
'id':[1,2,3,4,5],'name':['张三','李四','王二','丁一','赵五'],'age':[27,24,25,23,25],'gender':['男','男','男','女','女']})
df4 = pd.DataFrame({
'Id':[1,2,2,4,4,4,5],'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1'],'score':[83,81,87,75,86,74,88]})
df5 = pd.DataFrame({
'id':[1,3,5],'name':['张三','王二','赵五'],'income':[13500,18000,15000]})
# 三表的数据连接
# 首先df3和df4连接
merge1 = pd.merge(left = df3, right = df4, how = 'left', left_on='id', right_on='Id')
merge1
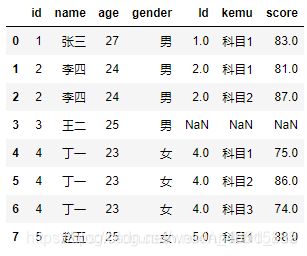
# 再将连接结果与df5连接
merge2 = pd.merge(left = merge1, right = df5, how = 'left')
merge2

如表26所示,就是构造的三个数据集,虽然df3和df4都用共同的字段“编号”,但是一个为id,另一个为Id,所以在后面的表连接时需要留意共同字段的写法。
如果需要将这三张表横向扩展到一张宽表中,需要经过两次merge操作。如上代码所示,第一次merge连接了df3和df4,由于两张表的共同字段不一致,所以需要分别指定left_on和right_on的参数值;第二次merge连接了首次的结果和df5,此时并不需要指定left_on和right_on参数,是因为第一次的merge结果就包含了id变量,所以merge时会自动挑选完全一致的变量用于表连接。如表27所示,就是经过两次merge之后的结果,结果中的NaN为缺失值,表示无法匹配的值。
9、分组聚合操作
在数据库中还有一种非常常见的操作就是分组聚合,即根据某些分组变量,对数值型变量进行分组统计。以珠宝数据为例,统计各颜色和刀工组合下的珠宝数量、最小重量、平均价格和最大面宽。如果读者对SQL比较熟悉的话,可以写成下方的SQL代码,实现数据的统计:
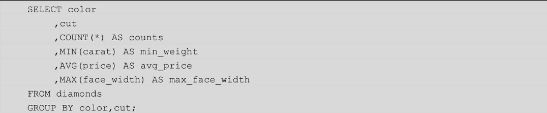
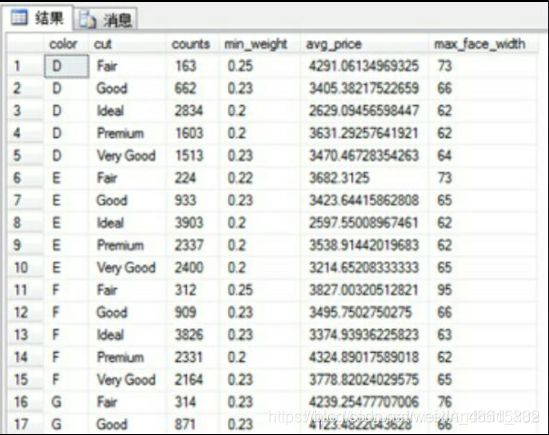
如上结果所示,就是通过SQL Server完成的统计,在每一种颜色和刀工的组合下,都会对应4种统计值。读者如果对SQL并不是很熟悉,该如何运用Python实现数据的分组统计呢?其实也很简单,只需结合使用Pandas模块中的groupby“方法”和aggregate“方法”,就可以完美地得到统计结果。详细的Python代码如下所示:
# 通过groupby方法,指定分组变量
grouped = diamonds.groupby(by = ['color','cut'])
# 对分组变量进行统计汇总
result = grouped.aggregate({
'color':np.size, 'carat':np.min, 'price':np.mean, 'face_width':np.max})
# 调整变量名的顺序
result = pd.DataFrame(result, columns=['color','carat','price','face_width'])
# 数据集重命名
result.rename(columns={
'color':'counts','carat':'min_weight','price':'avg_price','face_width':'max_face_width'}, inplace=True)
# 将行索引变量数据框的变量
result.reset_index(inplace=True)
result
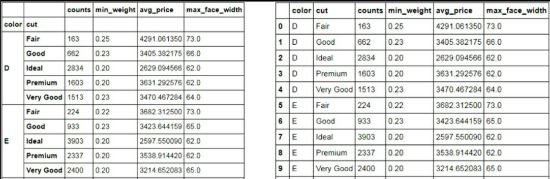
如上结果所示,与SQL Server形成的结果完全一致,使用Pandas实现分组聚合需要分两步走,第一步是指定分组变量,可以通过数据框的groupby“方法”完成;第二步是对不同的数值变量计算各自的统计值。在第二步中,需要跟读者说明的是,必须以字典的形式控制变量名称和统计函数(如上代码所示)。
通过这样的方式可以实现数值变量的聚合统计,但是最终的统计结果(如代码中的第一次返回result)可能并不是你所预期的,例如数据框的变量顺序发生了改动,变量名应该是统计后的别名;为了保证与SQL Server的结果一致,需要更改结果的变量名顺序(如代码中的第二次返回result)和变量名的名称(如代码中的第三次返回result)。
通过几次的修改就可以得到如上结果中的左半部分。细心的读者一定会发现,分组变量color和cut成了数据框的行索引。如果需要将这两个行索引转换为数据框的变量名,可以使用数据框的reset_index方法(如倒数第二行代码所示),这样就可以得到右半部分的最终结果。
10、本章小结
本章重点介绍了有关数据处理过程中应用到的Pandas模块,内容涉及序列与数据框的创建、外部数据的读取、变量类型的转换与描述性分析、字符型和日期型数据的处理、常用的数据清洗方法、数据子集的生成、如何制作透视表、多表之间的合并与连接以及数据集的分组聚合。通过本章的学习,读者可以掌握数据预处理过程中的绝大部分知识点,进而为之后的数据分析和挖掘做铺垫。
由于内容比较多,为了使读者清晰地掌握本章所涉及的函数和“方法”,这里将这些函数和“方法”重新梳理一下,以便读者查阅和记忆。
