Python 深度学习--学习笔记(十四)
用一维卷积神经网络处理序列
对于处理imdb评价正负面判断的模型,其实不是严格按照时间循序学习的,而是寻找样本中的关键词,因此用其他网络构建的模型同样对处理imdb评论有着很好的效果。
今天,我们将学习到用一维卷积理解序列数据。
一维卷积的卷积核是 (n,1) 的形状。这里需要注意的一点是,我们在二维卷积是大部分时间用到的卷积核为(3,3)(3x3=9),在一维卷积层,卷积窗口的大小可以提升到 (7, ) 或 (9, ).
一维卷积处理的思路与二维的大致相同,这里直接贴上代码实例:
- 处理数据
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 10000
max_len = 500
print('Loading data...')
(x_train,y_train),(x_test,y_test) = imdb.load_data(num_words=max_features)
print(len(x_train),'train sequences')
print(len(x_test),'test sequences')
print('Pad sequences (sample x time)')
x_train = sequence.pad_sequences(x_train,maxlen=max_len)
x_test = sequence.pad_sequences(x_test,maxlen=max_len)
print('x_train shape:',x_train.shape)
print('x_test shape:',x_test.shape)
输出:

- 构建模型
#每个单词对应一个128维的向量
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Embedding(max_features,128,input_length=max_len))
model.add(layers.Conv1D(32,(7,),activation='relu'))
#卷积核为 7
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32,(7,),activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1,activation='sigmoid'))
model.summary()
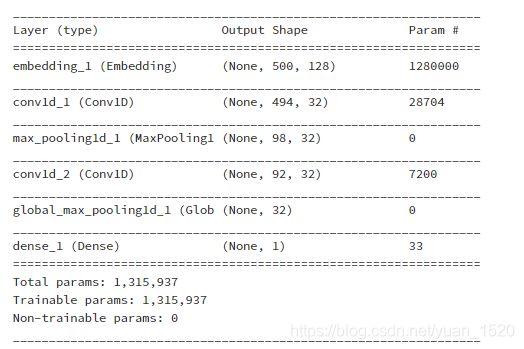
这里特别注意,Global_max_pooling1D就是对每个层做 最大值池化,从而使 三维—>二维( 也可以用Flatten() 展平)
- 编译,训练模型
model.compile(optimizer=RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train,y_train,
epochs=10,
batch_size=128,
validation_split=0.2)

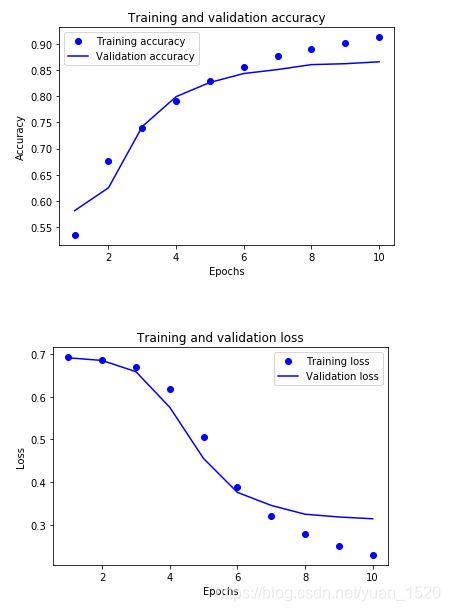
验证集精确度也达到0.86,说明一维卷积的方法是完全可行的,想要再提高精确度需要对模型超参数进行调整,同时还要控制防止过拟合情况。
- 绘图
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,11)
plt.plot(epochs,acc,'bo',label="Training accuracy")
plt.plot(epochs,val_acc,'b',label="Validation accuracy")
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.figure()
plt.plot(epochs,loss,'bo',label="Training loss")
plt.plot(epochs,val_loss,'b',label="Validation loss")
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()