bs4有感
@BeautifulSoup 的基础相关内容
1.1 BeautifulSoup 的安装
2.1 认识BeatifulSoup
3.1 学习心得
1.1 BeautifulSoup 的安装
我这里介绍一下:pip install BeautifulSoup(1、在doc命令2、在pycharm 的控制的 Terminal 中安装。
检测是否安装成功:
这样的显示,就代表你安装成功!
那如果说,没成功:
你可能还需要先下载其他的包:比如lxml、又或者是wheel ,再这里小编只是已在表明,安装些会增加你安装的成功率,并不是说你安装了这些,就一定能成功。
2.1 认识BeautifulSoup
2.1.1 使用这个包的条件:
1、from bs4 import BeautifulSoup -------导包
2.2.1 认识到BeautifulSoup 属于 bs4 包 的一部分。详情请到相关网站自行查询。
2.3.1 Beautiful 的使用
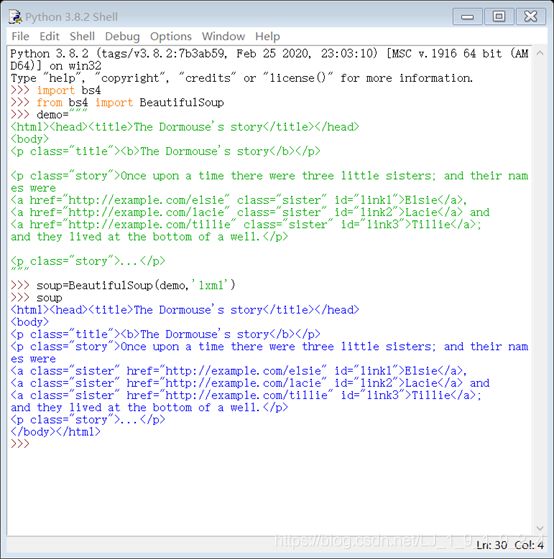
demo 元素
大家请看上面这样一个列子,小编直接跳过了发请求的环节,找了一个网页代码过来使用,另它赋值给一个变量 demo ,demo 只是方便我的使用,大家也可以看到,这个文本有点长,所以为了方便,才引入。
使用 BeautifulSoup(demo,‘lxml’)使用过后的效果如上图。
了解web开发的,都知道, 等其实是有一个树型关系,一代一代的,就好比,祖父、父母、孩子的关系,一个牵扯这一个,但又有自己的特点,大家不信,可以再看一下上图,为更好看这关系,大家可以使用soup.prettify() ,建议最好使用pycharm来看效果,python的交互环境,则会没那么明显。
2.4 遍历 查找 修改
依旧使用上图的几个元素:
访问父节点:
1、soup.a.parent
2、soup.a.parents
访问子节点:
1、soup.p.children
2、[soup.a]
3、soup.a.contents
访问同胞(兄弟)节点:
1、soup.a.next_sibling soup.a.siblings
2、soup.a.previous_sibling soup.a.previous.siblings
请看效果图:
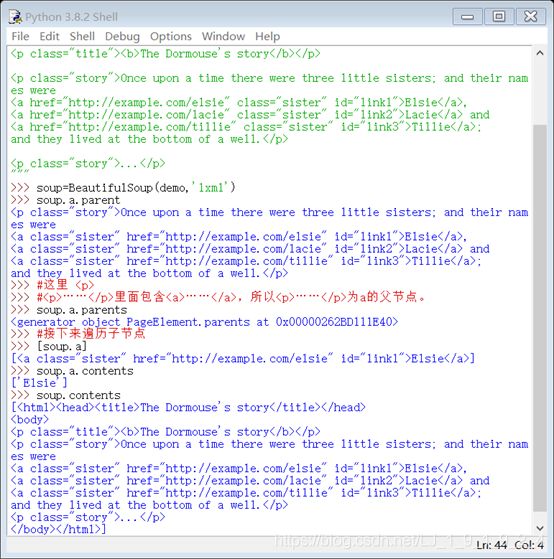
兄弟节点,我就不演示了,有兴趣的自行去试试,demo的文本内容我放在文末。
当然上面是基础,也是然我们更好理解标签间的关系:
也有快速访问的:find 与 find_all
1、使用格式:soup.find(‘a’) soup.find_all(‘a’)
2、列表形式:soup.find_all([‘p’,‘a’])
请看效果图:
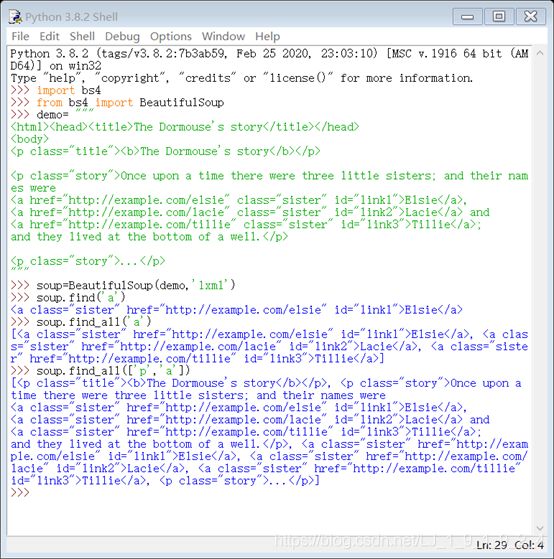
这里的所有,一般看见末尾加’s’的,它所访问出来的都都是多个数,而没有加‘s’ 的则一般只访问一个元素。这里只说了访问标签,如果说,我们想要访问之里面的内容,我们又该如何?这时,请考虑一下,soup.a.string 可以试试。
3.1 心得:
在这里,我们见识了web网页的结构组成,我们形象的称他们为父节点(parent)、子节点(children)以及同胞节点(sibling)。这就好比一个四世同堂的大家族,这个大家族里,你的祖父祖母,你的父母,就好比是父节点,而祖父母也是你的父节点,所以说,一个节点的父节点可能不止一个,但记住,这些父节点,并不是同辈,就好比,你父亲的哥哥,不能是你父亲(医学上的),对吧,但你父亲的父亲,就可以也是你的父节点。一个家族,首先有自己的大的标签,而web里是……包含了所有标签。
如果说,你想要访问一个标签,请牢记soup.a soup.find(‘a’)的格式,这种方式,访问出来的一般是第一个标签元素。而如果你想把它的同辈份的访问出来,记住:soup.a.siblings soup.find_all(‘a’) 就好了。如果有明确表明,访问出来的需要是 列表格式:那么请记住 [ soup.a.siblings] 或 soup.find([‘a’],…………),其他还有一些我没介绍了,等我熟悉后,我会再和大家一起分享我的学习成果。
@
demo="""
The Dormouse's story
Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well.
...
"""