决策树 随机森林
目录
-
- 决策树
-
-
- 信息熵
- 条件熵
- 信息增益
- 基尼系数
- 信息增益率
- 决策树预剪枝和后剪枝
-
- 预剪枝
- 后剪枝
-
- 随机森林
- 应用代码 jupyter notebook
- 应用代码 源码
决策树和随机森林都是非线性有监督的分类模型。
随机森林是由多个决策树组成,随机森林中每一棵决策树之间没有关联,在得到一个随机森林后,当有新的样本进入的时候,会使用每一棵决策进行判断,分析,分析出该样本属于哪一类,然后最后看哪一类被选择最多,就预测该样本属于这一类。
-
决策树
-
信息熵
-
公式
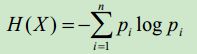
- 解释
其中,n代表当前类别有多少类别,代表当前类别中某一类别的概率。
- 计算举例
计算“是否购买电脑”这列的信息熵,当前类别“是否购买电脑”有2个类别,分别是“是”和“否”,那么“是否购买电脑”类别的信息熵如下:
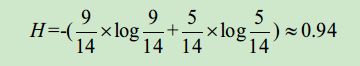
通过以上计算可以得到,某个类别下信息量越多,熵越大,信息量越少,熵越小。假设“是否购买电脑”这列下只有“否”这个信息类别,那么“是否购买电脑”这列的信息熵为:
![]()
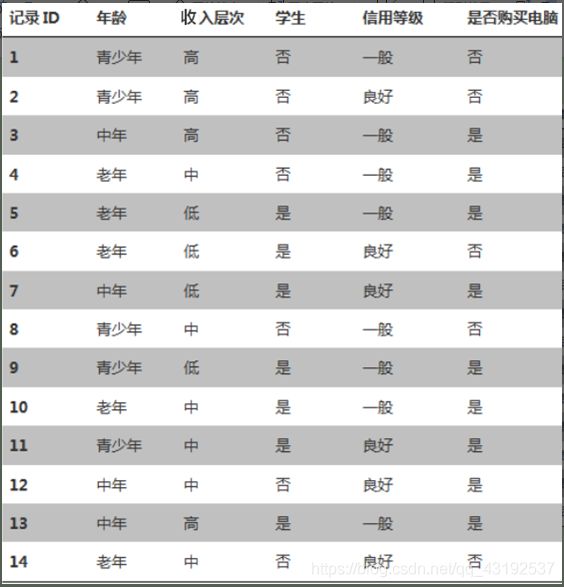
上图中,如果按照“年龄”,“收入层次”,“学生”,“信用等级”列使用决策树来预测“是否购买电脑”。选择决策树的根节点的分类条件,就是要找到合适的某列作为分类条件。即让“是否购买电脑”分类的更彻底,也就是找到在某个列作为分类条件时,“是否购买电脑”信息熵相对于没有这个分类条件时信息熵降低最大,即信息增益最大,这个条件就是分类节点的分类条件。下面来介绍条件熵和信息增益。
-
条件熵
在某个分类条件下某个类别的信息熵叫做条件熵,类似于条件概率。条件熵一般使用H(X | Y) 表示,代表在Y条件下,X的信息熵。
如上图中假设在“年龄”条件下,“是否购买电脑”的信息熵为:“年龄”列每个类别下对应的“是否购买电脑”信息熵的和。
H(是否购买电脑|年龄)=H(是否购买电脑|青少年)+H(是否购买电脑|中年)+H(是否购买电脑|老年)
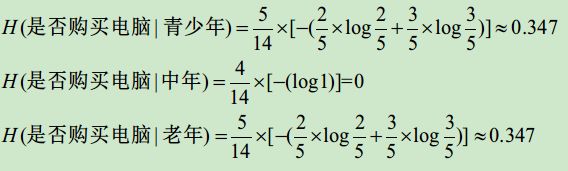
![]()
-
信息增益
分类前的信息熵减去分类后的信息熵。
如特征Y对训练集D的信息增益为。 在“年龄”条件下,“是否购买电脑”的信息增益为: g(是否购买电脑,年龄)=H(是否购买电脑)-H(是否购买电脑,年龄) =0.94-0.694=0.246
在构建决策树时,选择信息增益大的属性作为分类节点的方法也叫ID3分类算法。
-
基尼系数
-
公式
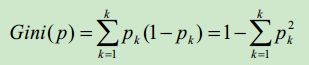
- 解释
其中,k代表当前类别有K个类别。代表当前类别中某一类别的概率,1-代表不是当前这个类别的概率。
上图中计算“是否购买电脑”这列的基尼系数:

基尼系数越小代表信息越纯,类别越少,基尼系数越大,代表信息越混乱,类别越多。基尼增益的计算和信息增益相同。假设某列只有一类值,这列的基尼系数为0。
-
信息增益率
在上图中,假设将“记录ID”也作为分类条件的话,由于“记录ID”对于“是否购买电脑”列的条件熵为0,可以得到“是否购买电脑”在“记录ID”这个分类条件下信息增益最大。如果选择“记录ID”作为分类条件,容易造成分支特别多,对已有记录ID的数据可以分类出结果,对于新的记录ID有可能不能成功的分类出结果。(即过拟合)所以要使用信息增益率来解决这个问题。
- 公式
![]()
例如:在“记录ID”条件下,“是否购买电脑”的信息增益最大,信息熵H(记录ID)也比较大,两者相除就是在“记录ID”条件下的信息增益率,结果比较小,消除了当某些属性比较混杂时,使用信息增益来选择分类条件的弊端。使用信息增益率来构建决策树的算法也叫C4.5算法。一般相对于信息增益来说,选择信息增益率选择分类条件比较合适。
如果决策树最后一个条件依然没能将数据准确分类,那么在这个节点上就可以使用概率来决定。看看哪些情况出现的多,该情况就是该节点的分类结果。
-
决策树预剪枝和后剪枝
-
预剪枝
就是在构建决策树的时候提前停止。比如指定树的深度最大为3,那么训练出来决策树的高度就是3,预剪枝主要是建立某些规则限制决策树的生长,降低了过拟合的风险,降低了建树的时间,但是有可能带来欠拟合问题。
-
后剪枝
后剪枝是一种全局的优化方法,在决策树构建好之后,然后才开始进行剪枝。后剪枝的过程就是删除一些子树,这个叶子节点的标识类别通过大多数原则来确定,即属于这个叶子节点下大多数样本所属的类别就是该叶子节点的标识。选择减掉哪些子树时,可以计算没有减掉子树之前的误差和减掉子树之后的误差,如果相差不大,可以将子树减掉。一般使用后剪枝得到的结果比较好。
-
随机森林
随机森林是由多个决策树组成。是用随机的方式建立一个森林,里面由很多决策树组成。随机森林中每一棵决策树之间都是没有关联的。得到随机森林之后,在一个样本输入时,森林中的每一棵决策树都进行判断,看看这个样本属于哪一类,最终哪一类得到的结果最多,该输入的预测值就是哪一类。
随机森林中的决策树生成过程是对样本数据进行行采样和列采样,可以指定随机森林中的树的个数和属性个数,这样当训练集很大的时候,随机选取数据集的一部分,生成一棵树,重复上面过程,可以生成一堆形态各异的树,这些决策树构成随机森林。
随机森林中的每个决策树可以分布式的训练,解决了单棵决策树在数据量大的情况下预算量大的问题。当训练样本中出现异常数据时,决策树的抗干扰能力差,对于随机森林来说也解决了模型的抗干扰能力。
-
应用代码 jupyter notebook
-
应用代码 源码
"""
决策树
"""
import numpy as np
from sklearn.tree import DecisionTreeClassifier
import sklearn.datasets as datasets
iris = datasets.load_iris()
# 目标值
X = iris['data']
# 特征值
y = iris['target']
from sklearn.model_selection import train_test_split
# 测试集和训练集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
# 实例化决策树
clf = DecisionTreeClassifier() # 默认使用的是geni系数
clf.fit(X_train, y_train)
clf.score(X_test,y_test)
# 使用entropy
clf = DecisionTreeClassifier(criterion='entropy', max_depth = 3)
clf.fit(X_train, y_train)
clf.score(X_test,y_test)
"""
随机森林
"""
from sklearn.ensemble import RandomForestClassifier
# n_estimators森林中树的数目
rf = RandomForestClassifier(n_estimators=100)
rf.fit(X_train, y_train)
rf.score(X_test, y_test)