Java面试题总结(乱序版,2020-09-03)
一、如何实现数组和 List 之间的转换?
String[] arr = {"zs","ls","ww"};
List list = Arrays.asList(arr);
System.out.println(list);
ArrayList list1 = new ArrayList();
list1.add("张三");
list1.add("李四");
list1.add("王五");
String[] arr1 = list1.toArray(new String[list1.size()]);
System.out.println(arr1);
for(int i = 0; i < arr1.length; i++){
System.out.println(arr1[i]);
} 二、什么是锁消除和锁粗化?
1、锁消除
所消除就是虚拟机根据一个对象是否真正存在同步情况,若不存在同步情况,则对该对象的访问无需经过加锁解锁的操作。
比如StringBuffer的append方法,因为append方法需要判断对象是否被占用,而如果代码不存在锁竞争,那么这部分的性能消耗是无意义的。于是虚拟机在即时编译的时候就会将上面的代码进行优化,也就是锁消除。
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}从源码可以看出,append方法用了 synchronized关键字,它是线程安全的。但我们可能仅在线程内部把StringBuffer当做局部变量使用;StringBuffer仅在方法内作用域有效,不存在线程安全的问题,这时我们可以通过编译器将其优化,将锁消除,前提是Java必须运行在server模式,同时必须开启逃逸分析;
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks
其中+DoEscapeAnalysis表示开启逃逸分析,+EliminateLocks表示锁消除。public static String createStringBuffer(String str1, String str2) {
StringBuffer sBuf = new StringBuffer();
sBuf.append(str1);// append方法是同步操作
sBuf.append(str2);
return sBuf.toString();
}
逃逸分析:比如上面的代码,它要看sBuf是否可能逃出它的作用域?如果将sBuf作为方法的返回值进行返回,那么它在方法外部可能被当作一个全局对象使用,就有可能发生线程安全问题,这时就可以说sBuf这个对象发生逃逸了,因而不应将append操作的锁消除,但我们上面的代码没有发生锁逃逸,锁消除就可以带来一定的性能提升。
2、锁粗化
锁的请求、同步、释放都会消耗一定的系统资源,如果高频的锁请求反而不利于系统性能的优化,锁粗化就是把多次的锁请求合并成一个请求,扩大锁的范围,降低锁请求、同步、释放带来的性能损耗。
三、跟 Synchronized 相比,可重入锁 ReentrantLock 其实现原理有什么不同?
1、都是可重入锁;
2、ReentrantLock内部是实现了Sync,Sync继承于AQS抽象类。Sync有两个实现,一个是公平锁,一个是非公平锁,通过构造函数定义。AQS中维护了一个state来计算重入次数,避免频繁的持有释放操作带来的线程问题。
3、ReentrantLock只能定义代码块,而Synchronized可以定义方法和代码块;
4、Synchronized是JVM的一个内部关键字,ReentrantLock是JDK1.5之后引入的一个API层面的互斥锁;
5、Synchronized实现自动的加锁、释放锁,ReentrantLock需要手动加锁和释放锁,中间可以暂停;
6、Synchronized由于引进了偏向锁和自旋锁,所以性能上和ReentrantLock差不多,但操作上方便很多,所以优先使用Synchronized。
四、那么请谈谈 AQS 框架是怎么回事儿?
1、AQS是AbstractQueuedSynchronizer的缩写,它提供了一个FIFO队列,可以看成是一个实现同步锁的核心组件。
AQS是一个抽象类,主要通过继承的方式来使用,它本身没有实现任何的同步接口,仅仅是定义了同步状态的获取和释放的方法来提供自定义的同步组件。
2、AQS的两种功能:独占锁和共享锁。
3、ReentrantLock的类图:
4、AQS的内部实现
AQS的实现依赖内部的同步队列,也就是FIFO的双向队列,如果当前线程竞争失败,那么AQS会把当前线程以及等待状态信息构造成一个Node加入到同步队列中,同时再阻塞该线程。当获取锁的线程释放锁以后,会从队列中唤醒一个阻塞的节点(线程)。
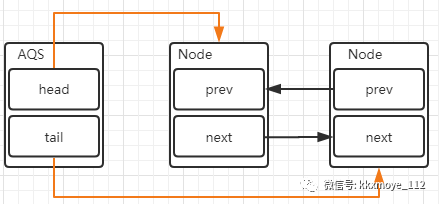
AQS队列内部维护的是一个FIFO的双向链表,这种结构的特点是每个数据结构都有两个指针,分别指向直接的后继节点和直接前驱节点。所以双向链表可以从任意一个节点开始很方便的范文前驱和后继节点。每个Node其实是由线程封装,当线程争抢锁失败后会封装成Node加入到AQS队列中。
五、session 和 cookie 有什么区别?
1、存储位置不同
- cookie在客户端浏览器;
- session在服务器;
2、存储容量不同
- cookie<=4K,一个站点最多保留20个cookie;
- session没有上线,出于对服务器的保护,session内不可存过多东西,并且要设置session删除机制;
3、存储方式不同
- cookie只能保存ASCII字符串,并需要通过编码方式存储为Unicode字符或者二进制数据;
- session中能存储任何类型的数据,包括并不局限于String、integer、list、map等;
4、隐私策略不同
- cookie对客户端是可见的,不安全;
- session存储在服务器上,安全;
5、有效期不同
- 开发可以通过设置cookie的属性,达到使cookie长期有效的效果;
- session依赖于名为JESSIONID的cookie,而cookie JSESSIONID的过期时间默认为-1,只需关闭窗口该session就会失效,因而session达不到长期有效的效果;
6、跨域支持上不同
- cookie支持跨域;
- session不支持跨域;
六、tcp 为什么要三次握手,两次不行吗?为什么?
因为客户端和服务端都要确认连接,①客户端请求连接服务端;②针对客户端的请求确认应答,并请求建立连接;③针对服务端的请求确认应答,建立连接;
两次无法确保A能收到B的数据;
七、使用工厂模式最主要的好处是什么?在哪里使用?
1、工厂模式好处
- 良好的封装性、代码结构清晰;
- 扩展性好,如果想增加一个产品,只需扩展一个工厂类即可;
- 典型的解耦框架;
2、在哪里使用?
- 需要生成对象的地方;
- 不同数据库的访问;
八、什么是 Spring inner beans?
在Spring框架中,无论何时bean被使用时,当仅被调用一个属性。可以将这个bean声明为内部bean。内部bean可以用setter注入“属性”和构造方法注入“构造参数”的方式来实现。比如,在我们的应用程序中,一个Customer类引用了一个Person类,我们要做的是创建一个Person实例,然后再Customer内部使用。
package com;
public class Customer {
private Person person;
}
class Person{
private int id;
private String name;
private int age;
}
九、Spring 框架中的单例 Beans 是线程安全的么?
Spring框架并没有对单例bean进行任何多线程的封装处理。关于单例bean的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的Spring bean并没有可变的状态,所以在某种程度上说Spring的单例bean时线程安全的。如果你的bean有多种状态的话,比如view model,就需要自行保证线程安全啦。
最浅显的解决办法就是将多态bean的作用域由singleton变更为prototype。
十、如何集成 Spring Boot 和 ActiveMQ?
ActiveMQ简介,了解就好,继承暂不做解释了。
MQ是消息中间件,是一种在分布式系统中应用程序借以传递消息的媒介,常用的有ActiveMQ,RabbitMQ,kafka。ActiveMQ是Apache下的开源项目。
(1)特点:
- 支持多种语言编写客户端
- 对spring的支持,很容易和spring整合
- 支持多种传输协议:TCP,SSL,NIO,UDP等
- 支持AJAX
(2)消息形式:
- 点对点(queue)
- 一对多(topic)
十一、如何使用 Spring Boot 实现分页和排序?
使用Spring Data Jpa可以实现将可分页的传递给存储库方法。
十二、hibernate 实体类可以被定义为 final 吗?
可以将hibernate的实体类定义为final,但这种做法不好。
因为hibernate会使用代理模式在延迟关联的情况下提高性能,如果你把实体类定义成final类之后,因为Java不允许对final类进行扩展,所以hibernate就无法再使用代理了,如此一来就限制了使用可以提升性能的手段。
不过,如果你的持久化类实现了一个接口,而且在该接口中声明了所有定义于实体类中的所有public的方法的话,就能避免出现前面所说的不利后果。
十三、mybatis 有哪些执行器(Executor)?
1、mybatis有三种基本的Executor执行器:
(1)、SimpleExecutor
每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
(2)、PauseExecutor
执行update或select,以sql做为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而且放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
(3)、BatchExecutor
执行update,将所有sql通过addBatch()都添加到批处理中,等待统一执行executeBatch(),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
2、作用范围:
Executor的这些特点,都严格限制在SqlSession生命周期范围内。
3、Mybatis中如何指定使用哪一种Executor执行器?
在mybatis的配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。
十四、char 和 varchar 的区别是什么?
- char的长度是固定的,varchar的长度的可变的;
- char的效率比varchar的效率高;
- char占用空间比varchar大,char在查询时需要使用trim;
十五、float 和 double 的区别是什么?
1、float 和 double 的区别是什么?
(1)内存中占有的字节数不同
单精度浮点数在内存中占有4个字节;
双精度浮点数在内存中占有8个字节;
(2)有效数字位数不同
单精度浮点数有效数字8位;
双精度浮点数有效数字16位;
(3)数值取值范围不同
单精度浮点数的表示范围:-3.40E+38~3.40E+38
双精度浮点数的表示范围:-1.79E+308~-1.79E+308
(4)在程序中处理速度不同
一般来说,CPU处理单精度浮点数的速度比双精度浮点数的速度快
如果不声明,默认小数是double类型,如果想用float,要进行强转;
2、例如
float f = 1.3;会编译报错,正确的写法是float f = (float)1.3;或者float a = 1.3f;(f或F都可以不区分大小写)
3、注意
float是八位有效数字,第七位会四舍五入;
4、面试题
(1)java中3*0.1==0.3将会返回什么?true还是false?
答:返回false,因为浮点数不能完全精确的表示出来,一般会损失精度;
(2)java中float f = 3.4;是否正确?
答:不正确。因为3.4是双精度浮点数,将双精度赋给单精度属于向下转型,会造成精度损失,因此需要强制类型转换float=(float)3.4;或者写成float f = 3.4f;
十六、Redis,什么是缓存穿透?怎么解决?
1、缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对用的value,就应该去后端系统查找(比如DB数据库)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
2、怎么解决?
- 对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert之后清理缓存。
- 对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该Bitmap过滤。
3、缓存雪崩
当缓存服务器重启或者大量缓存集中在某一时间段失效,这样在失效的时候,会给后端系统带来很大的压力,导致系统崩溃。
4、如何解决?
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其它线程等待;
- 做二级缓存;
- 不同的key,设置不同的过期时间,让缓存失效的时间尽量均匀;
十七、说一下 jvm 有哪些垃圾回收器?
说一下 jvm 有哪些垃圾回收器?
前一篇:Java面试题总结(乱序版,2020-08-31)
后一篇:Java面试题总结(附答案)
