Cisco ACI的测试感受
前段时间在公司的测试环境玩了玩cisco ACI,觉得挺有意思的,一直想写点测试的感受,但是一直比较忙,最近抽了几个晚上梳理了一下,分享下这次有趣的测试。
1、关于ACI网络架构介绍
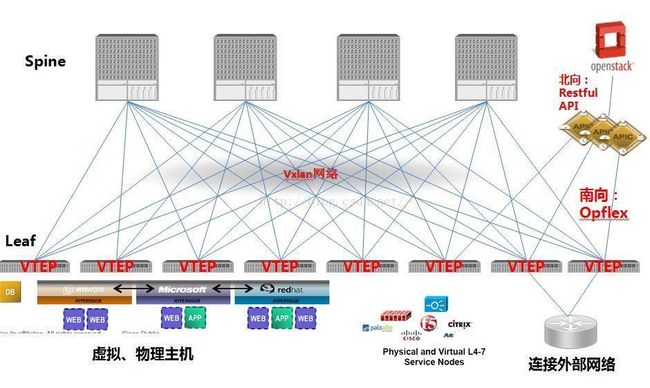
我自己画了一个比较典型ACI的组网,简单说下几个比较重要的组件:
1.1 思科应用策略基础设施控制器(APIC):
APIC是Cisco ACI交换矩阵、策略实施和健康状态监控实现自动化和管理的统一点。主要负责的任务包括交换矩阵激活、交换机固件维护、网络策略配置和实例化。以上这些功能的实现都是依靠着南向的Opflex协议(这个协议cisco已经提交IETF了,但是目前并没有其他厂商愿意跟进,所以这个协议目前基本上可以看成cisco的私有协议)。此外,APIC针对可编程性和集中管理,重新进行了设计。Cisco APIC通过XML和JSON提供北向API,并同时提供使用此API的命令行界面(CLI)和GUI,用以管理交换矩阵。 此系统还提供开源南向API,使第三方网络服务供应商可以通过Cisco APIC对供应的设备实施策略控制。
1.2 VXLAN交换矩阵
ACI的网络分为underlay和overlay两个层面。
先说说underlay网络,underlay网络就是spine和leaf之间的底层ip网络。由于ACI的overlay网络采用了VXLAN技术(关于VXLAN技术我就不多讲了,之前文章中也有提到),这样一来underlay网络相对比较固定,仅仅需要提供ip可达。因此当物理的网络设备之间的线路相互连接后,控制器会自动向各个网络节点自动推送配置,完成underlay网络的搭建。这个过程几乎是自动实现的,当一台新的交换机上线后,只要将接入当前的fabric后,即可完成所有的网络配置。值得一提的是Underlay网络配置完全是黑盒的,登陆到交换机上完全看不明白配置,据cisco工程师说目前还没开放底层网络的Troubleshooting,经过我的研究,感觉上比较像ISIS和BGP组成的一个三层组网,通过ECMP进行负载均衡,由于underlay网络是一个三层网络,所以横向扩展非常容易,适合超大型的数据中心。而ACI网络中物理交换机上线基本做到了即插即用,使得网络扩容变得更加敏捷。
再来说说overlay网络,ACI网络中主机接入的leaf交换机都是vtep,所以应用的网络访问逻辑上都是通过overlay网络来完成的,所以overlay网络实际上是和物理的网络设备解耦的,overlay网络可以完全无视物理网络,根据应用灵活控制。
特别说一下,ACI是典型的硬件overlay的解决方案,Cisco由于是硬件厂商,所以它负责给VXLAN封装的VTEP全是在物理交换机(Leaf节点)上的,所以ACI解决方案中支持任意的虚拟化技术,但是相对的硬件交换机也就被思科的ACI交换机绑死。这恰好和软件overlay的解决方案相反,软件overlay方案中,硬件交换机可以随意选择,只要三层互通即可,而软件交换机必须采用虚拟化厂商的产品,比如Vmware NSX。
1.3 以应用为中心的网络
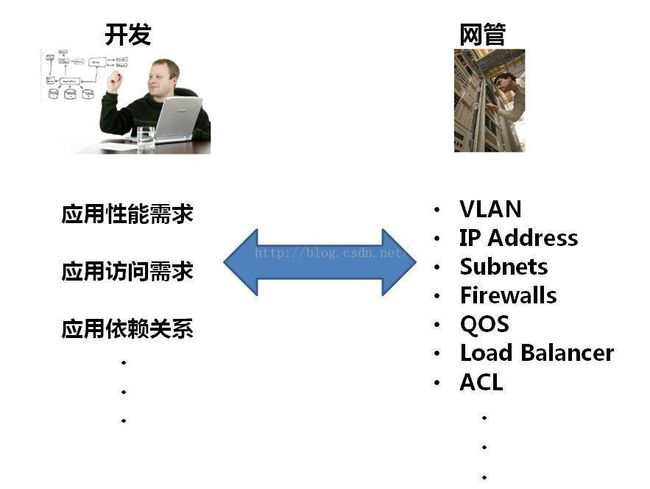
传统网络运维模式,在传统的运维过程中,开发人员先会提出一系列的应用需求,然后由网管转换为具体的网络配置,这个过程中由于开发人员不清楚网络结构、网络运维不清楚应用架构,所以很容易造成沟通障碍,严重影响应用的敏捷、可靠部署。而在Cisco ACI框架中,颠覆旧有的网络运维模式,将网络语言直接转化在应用逻辑之中,由应用指导网络行为,无需再配置任何网络设备,只需要通过控制器或者北向的应用就可以简单的完成应用网络环境的搭建。
2、谈谈对ACI测试的感受
测试环境:
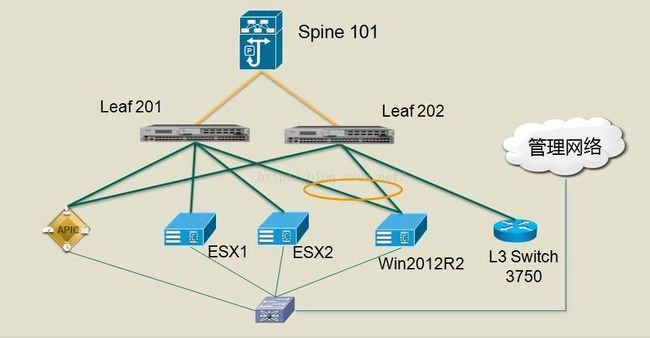
测试设备:
- 1台APIC控制器
- 1台Nexus 9336:ACI Spine
- 2台Nexus 9396:ACI Leaf
- 3台服务器(2台ESXi主机,1台Window2012R2物理机)
- 1台3750交换机(L3)
2.1 Underlay网络即插即用
传统网络:
ACI网络:

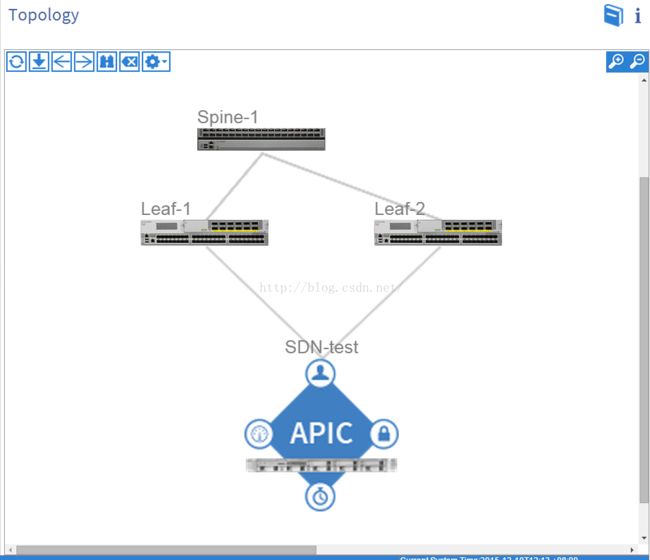
设备上线后自动生成的拓扑图:
设备上线后自动生成的设备信息:

设备上线后自动生成的监控信息:
2.2 overlay网络以应用为中心
APIC的配置页面上有两个最重要的配置单元:一个是TENANTS,一个是FABRIC,FABRIC主要是underlay的一些配置、策略以及信息展示。TENANTS则是负责overlay网络。下面是我画的一个租户网络的建立过程:

1、首先需要在控制器上建立一个租户,比如TENANT-A;
2、然后在租户下创建ANP,一个租户可以对应多个ANP,ANP可以理解成业务条线;
3、创建完ANP后在创建EPG,一个EPG可以理解为一个应用,EPG是整个ACI应用架构中每个EPG下会有N个虚拟机或物理机,EPG内部由于同属一个应用,所以内部是互通的;
4、EPG之间默认是不通的,需要通过创建contract来实现互通,Contract可以理解为两个应用之间的依赖关系,是一个端口的过滤;
5、在创建EPG的过程中需要绑定BD,BD我理解就是一个网段的组,就是这个EPG需要对应网段信息,所以在创建EPG之前将完成BD的创建。一个/多个EPG对应一个BD,每个BD可以包含多个网段,创建BD实际就是创建网关的过程,而一个BD下创建多个subnet,我登到物理交换机上看,实际上就是网关创建了一个secondary地址。
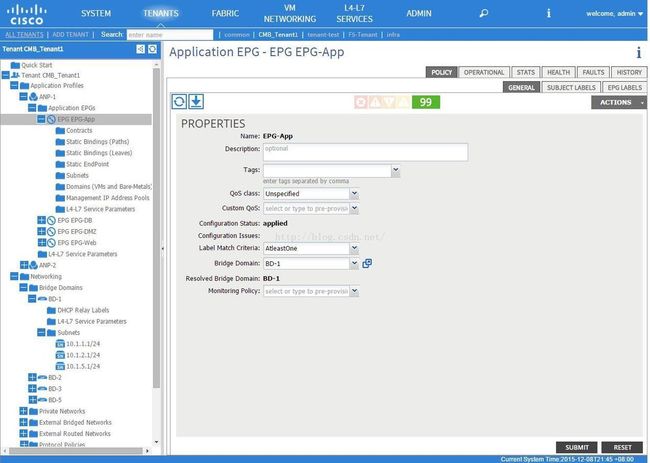
以上整个过程,不需要通过任何的网络命令来实现,仅仅需要在控制器的web页面上进行简单的勾选配置即可,下图是一个我创建好的租户示意图。
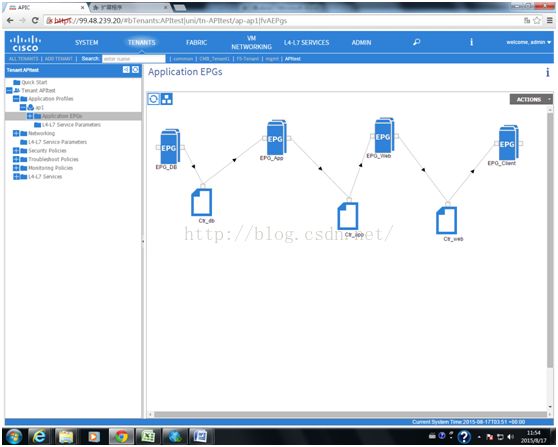
我简单的配置了一个DB、APP、WEB组成的应用,当上面的所有配置完成后,控制器上会得到一张应用之间的依赖关系图:

未来如果有新租户就增加一个新的Tenant,如果一个租户内需要应用扩容,增加EPG和Contract即可,如果某一个应用网段需要扩容,直接在此EPG绑定的BD下增加一个subnet即可,所以overlay的网络扩容也是比较简单的。
最后,这一系列的overlay网络配置完成后,如何运用到主机呢?
前面说了ACI支持各种虚拟化技术以及物理服务器的网络接入,虚拟化以Vmware vSphere为例,物理交换机和ESXI主机是通过trunk互联的,在vcenter上首先需要创建一个VDS(vSphere Distributed Switch),创建完VDS以后需要需要创建portgroups,一般情况下portgroups是按照vlan来创建。每台虚机在创建的时候都会选择一个portgroup,实际就是让这台虚机送到物理交换机的报文上打上一个vlan tag,让报文可以在物理交换网络里面被转发。在ACI架构中,无需在vcenter中创建虚拟交换机,APIC可以向vcenter推送一个DVS,推送后在APIC的管理界面上可以看到vcenter的所有主机信息以及portgroup信息。
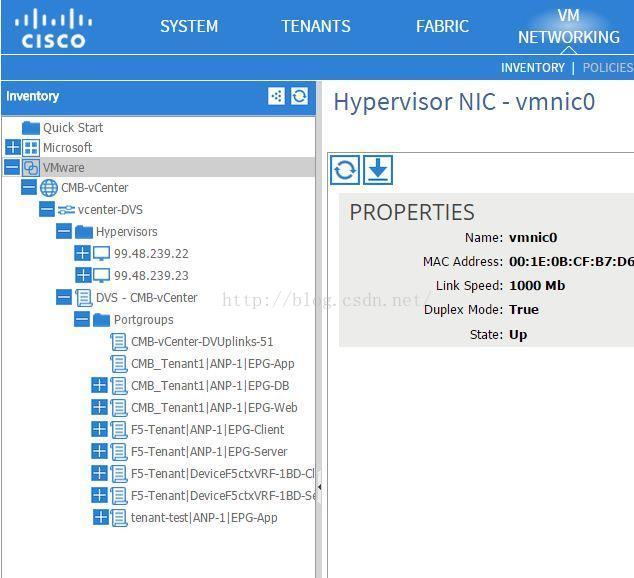
这些portgroups都是EPG创建时候关联VMM domain产生的。除了看到portgroups信息外,甚至还能看到每台主机内有哪些虚机,以及具体的虚机信息。
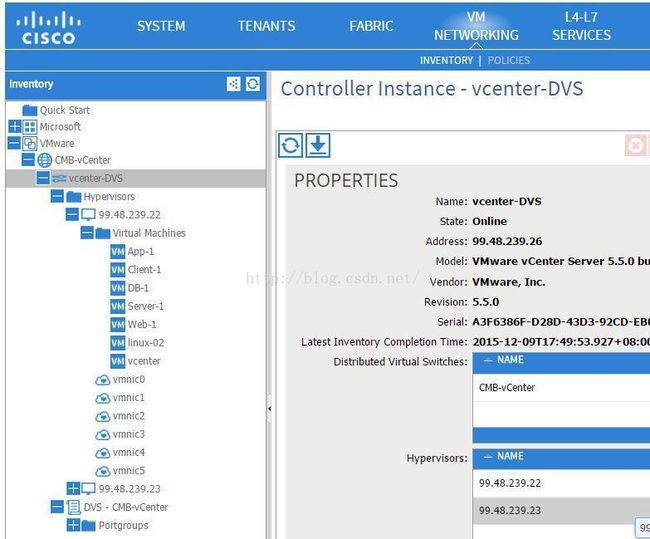
与此同时在vcenter的网络中也出现了刚才推送的DVS。
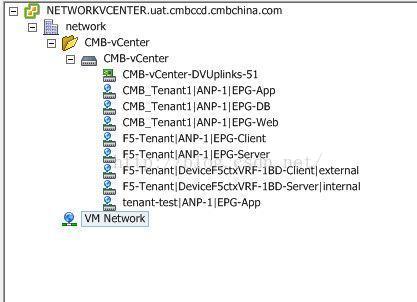
此时vcenter上的portgroups从以vlan为单位变成了以EPG为单位,这样在新建的虚机选择portgroup时,就按照应用需要选择对应的portgroup即可。
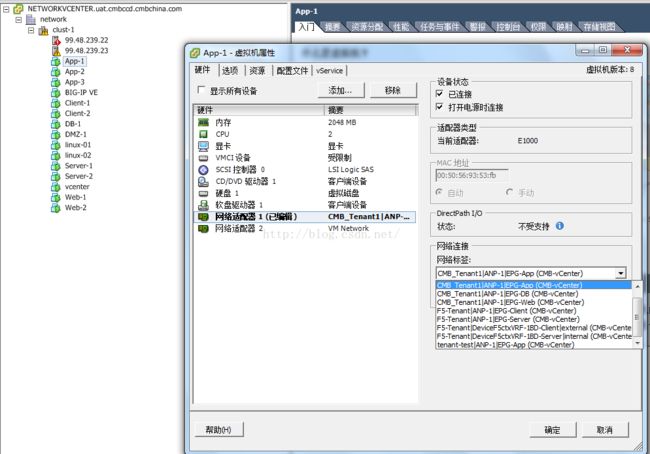
这样一些比较简单的ACI网络配置就完成了。整个过程,几乎不需要网工的参与,只需要懂一点点网络知识的开发人员即可配置一些简单应用的网络。所以作为一名网工在完成这一系列配置后内心是非常崩溃的,一方面感叹cisco的黑科技,另一方面觉得技术这么发展下去传统网工距离卖水果又近了一步。
2.3 网络可视能力强,日常运维更轻松
- 传统网络运维痛点:
1、网络可视能力差,定位问题慢;
2、网络关联性差,由于虚拟化的广泛应用,交换机接口、ip地址、server name、应用等参数关联困难,当对一台物理交换机进行维护时,搞不清楚下面到底接了哪些服务器、对应哪些应用;
ACI由于是控制器集中控制全网,所以网络可视性和关联性很强。
- 定位故障:
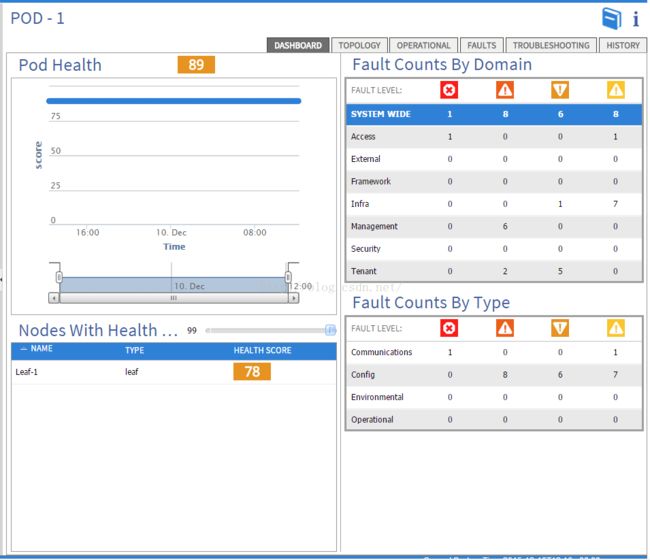
整个system是有个健康检查的DASHBOARD的,可以看到整个Pod Health,以及其中Node的Health,如下图,可以看到整个Pod健康只有89分,再往下看,发现其中Leaf-1这个Node分数是78分,说明是存在问题的。
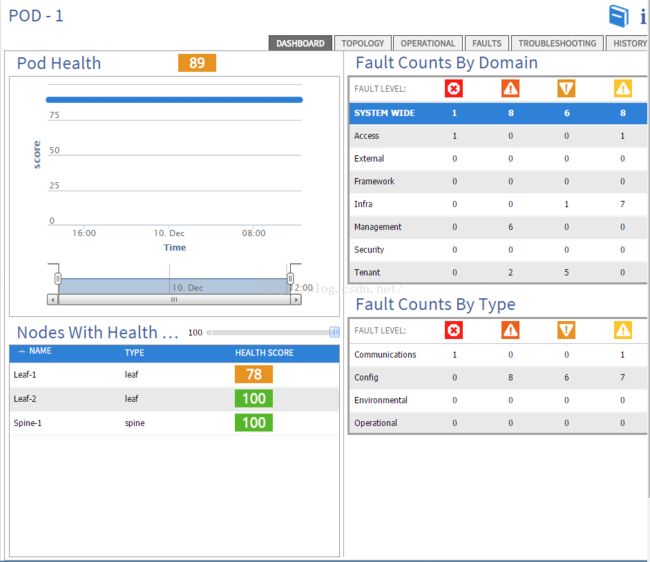
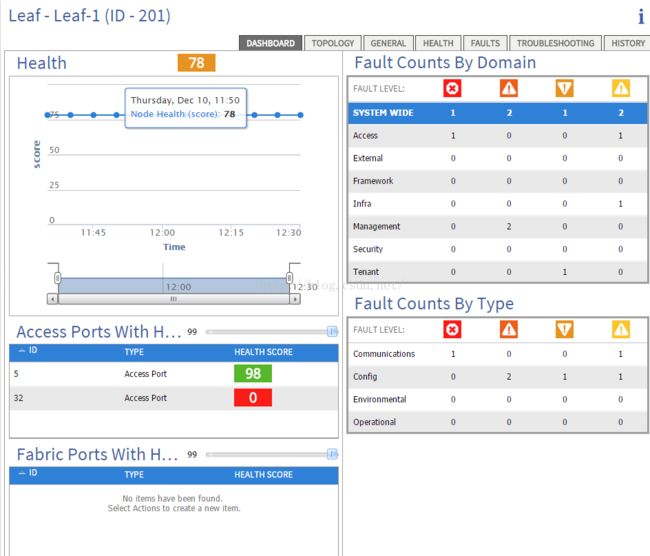
当我们点击Leaf-1的分数,就可以看到Leaf-1具体故障所在,可以看到32口是0分,所以说明32口出现了故障。
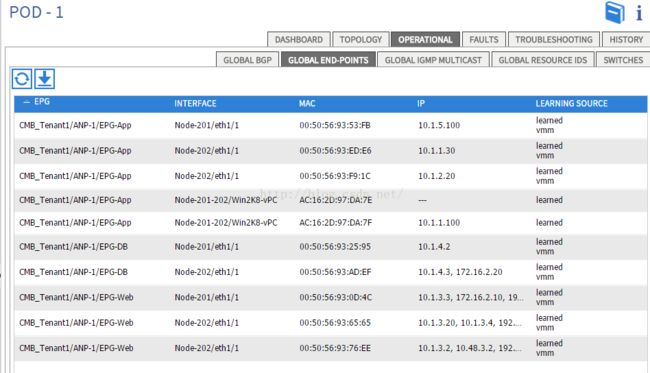
网络关联系:
APIC中可以查看到网络中各个相关元素的对应关系,比如每个应用有哪些虚机,分别ip地址是多少,对应的交换机接口信息又是什么,又或者可以看到某一个交换机下有哪些应用,有哪些虚机,这些关联性可以让我们的日常运维变得简单,而且可以让我们把虚机的网络管理起来。
2.4 分布式网关
每个leaf节点即vtep都有所有网段的网关,所以同一个leaf节点下主机间的流量终结在leaf节点,减少了数据中心东西向的流量。这个是APIC自动实现的,在创建好BD后,每个leaf节点上就会有所有BD的网关,不需要额外去配置。
2.5 物理机和虚拟机网络统一管理
这点是软件overlay解决方案做不到的,ACI支持将VM虚拟化资源和物理机资源统一封装在一个EPG内,实现物理资源和虚拟化资源的统一管理。
2.6 控制器北向接口的编程能力
APIC具有开放的、易于使用的可编程接口API,包括RESTful接口,支持XML、Jason等方式,为云数据中心业务编程平台、IaaS平台等提供网络自动化部署能力。通过Postman工具,推送XML脚本,实现自动化构建一个完整的租户网络,包括Tenant、VRF、BD、Subnet、ANP、EPG和Contract等。
推送一个租户:ACI-test,包含了多个EPG等。
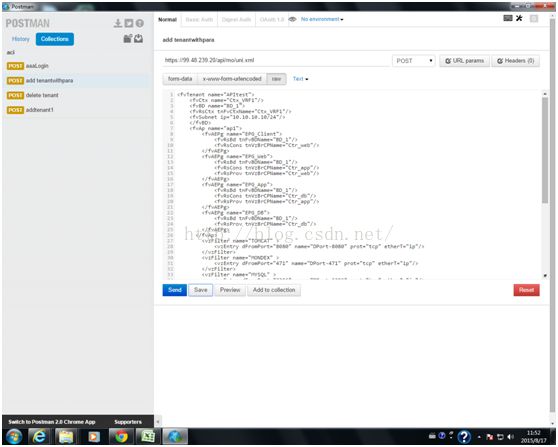
在APIC上查看创建的租户配置:
2.7 L4-L7 services
这个也是ACI炒的一个亮点,但我感觉比较鸡肋,支持的设备比较少。
2.8 ACI的问题
- 更加彻底的黑盒:
网络厂商搞黑盒本来也没什么好奇怪的,所以且不说设备捆绑问题,现在连物理交换机都完全无法去维护了,虽然说APIC统一去管理物理交换机,方便是没错,但作为一个网管完全不知道底层配了什么东西,心里还是很慌的,所以这东西适合开发去用,反正开发也不管网络底层是怎么弄起来的。
当然CISCO除了ACI以外还有一套开放的SDN解决方案叫VTS,这个解决方案和ACI基本差不多,硬件依然是Nexus9K,只是控制层面采用BGP EVPN的方式,然后由一个叫VTC的控制器向物理设备自动推配置。此外VTS和openstack云管平台有比较好的集成,Openstack的Neutron模块利用北向的Restful API和VTC进行对接,VTS这个解决方案并没有ACI知名度高,主要在一些采用openstack的云计算场景下有比较好的使用场景。
- 使用者定位问题:
传统意义上来看网络的东西应该网管去维护,但是ACI这东西明显是开发去维护更方便,重点是overlay的网络,应用逻辑这些东西,但是一般的公司也不会让开发直接去维护一个生产的网络。ACI由于太过于黑盒,一般公有云不大会去用,所以面向对象主要还是一些企业内部的私有云,尤其是金融行业,就我目前在金融行业的经验来看,绝对不会让开发去维护生产网络的。
- 以应用为中心的网络真的实用吗
这个概念还是很美好的,但落地真心不容易啊,以金融行业为例,一个企业内部有很多应用,每个应用的逻辑也都非常复杂,所以去规划租户和EPG是非常难,可能一个ANP要写几百条Contract,反而把网络复杂化了。
- 关于DVS的问题
现在DVS只能打vlan tag不能打vxlan tag,由于一个EPG会对应一个vlan,那么租户多了以后,ACI网络中还是可能会存在vlan不够用的情况。租户之间vlan复用?理论上是可以的,但是不是所有情况下都适用,比如一个物理机里面的两台虚机,分别属于两个租户,这两台虚机对应的vlan恰好是一致的,那么如果这台虚机所配置的ip又恰好在一个子网里面,是不是两个租户网络就互通了?这个问题的根源我觉得是在于硬件overlay方案中vtep是物理交换机,所以在虚机层面没法打vxlan tag。
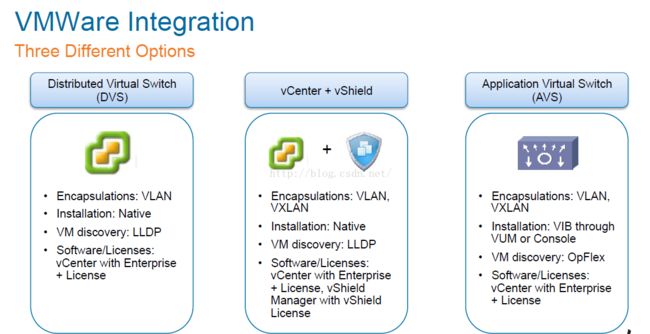
当然ACI中还有另一种virtual switch可以选,就是AVS,类似nexus1000V,是可以支持打vxlan tag的,但是vm discovery用的是OpFlex,感觉ACI这么搞vmware应该是不会同意的,AVS等于就是接管了vmware NSX的一些功能了,两家现在是竞争对手,所以我估计未来vmware一定不会支持AVS的。不过cisco打出AVS这张牌是不是也是默认软件的overlay更加合理呢?