Hadoop平台安全机制Kerberos认证
日前笔者在使用flume采集数据直接入到Hadoop平台HDFS上时,由于Hadoop平台采用了Kerberos认证机制。flume配置上是致辞kerberos认证的,但由于flume要采集的节点并不在集群内,所以需要学习Kerberos在Hadoop上的应用。
1、Kerberos协议
Kerberos协议:
Kerberos协议主要用于计算机网络的身份鉴别(Authentication), 其特点是用户只需输入一次身份验证信息就可以凭借此验证获得的票据(ticket-granting ticket)访问多个服务,即SSO(Single Sign On)。由于在每个Client和Service之间建立了共享密钥,使得该协议具有相当的安全性。
条件
先来看看Kerberos协议的前提条件:
如下图所示,Client与KDC, KDC与Service 在协议工作前已经有了各自的共享密钥,并且由于协议中的消息无法穿透防火墙,这些条件就限制了Kerberos协议往往用于一个组织的内部, 使其应用场景不同于X.509 PKI。
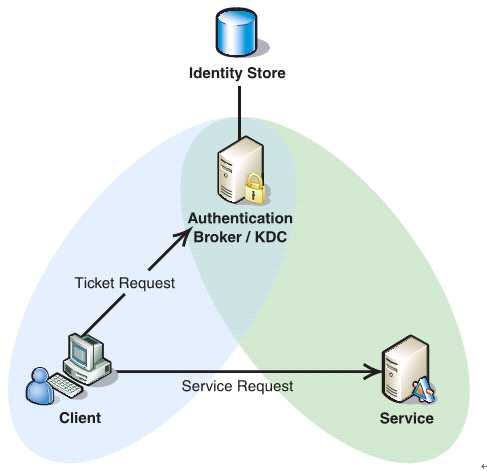
过程
Kerberos协议分为两个部分:
1 . Client向KDC发送自己的身份信息,KDC从Ticket Granting Service得到TGT(ticket-granting ticket), 并用协议开始前Client与KDC之间的密钥将TGT加密回复给Client。
此时只有真正的Client才能利用它与KDC之间的密钥将加密后的TGT解密,从而获得TGT。
(此过程避免了Client直接向KDC发送密码,以求通过验证的不安全方式)
2. Client利用之前获得的TGT向KDC请求其他Service的Ticket,从而通过其他Service的身份鉴别。
Kerberos协议的重点在于第二部分,简介如下:
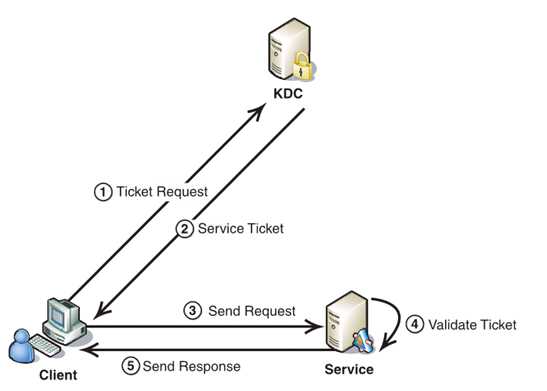
1. Client将之前获得TGT和要请求的服务信息(服务名等)发送给KDC,KDC中的Ticket Granting Service将为Client和Service之间生成一个Session Key用于Service对Client的身份鉴别。然后KDC将这个Session Key和用户名,用户地址(IP),服务名,有效期, 时间戳一起包装成一个Ticket(这些信息最终用于Service对Client的身份鉴别)发送给Service, 不过Kerberos协议并没有直接将Ticket发送给Service,而是通过Client转发给Service.所以有了第二步。
2. 此时KDC将刚才的Ticket转发给Client。由于这个Ticket是要给Service的,不能让Client看到,所以KDC用协议开始前KDC与Service之间的密钥将Ticket加密后再发送给Client。同时为了让Client和Service之间共享那个秘密(KDC在第一步为它们创建的Session Key), KDC用Client与它之间的密钥将Session Key加密随加密的Ticket一起返回给Client。
3. 为了完成Ticket的传递,Client将刚才收到的Ticket转发到Service. 由于Client不知道KDC与Service之间的密钥,所以它无法算改Ticket中的信息。同时Client将收到的Session Key解密出来,然后将自己的用户名,用户地址(IP)打包成Authenticator用Session Key加密也发送给Service。
4. Service 收到Ticket后利用它与KDC之间的密钥将Ticket中的信息解密出来,从而获得Session Key和用户名,用户地址(IP),服务名,有效期。然后再用Session Key将Authenticator解密从而获得用户名,用户地址(IP)将其与之前Ticket中解密出来的用户名,用户地址(IP)做比较从而验证Client的身份。
5. 如果Service有返回结果,将其返回给Client。
总结
概括起来说Kerberos协议主要做了两件事
1. Ticket的安全传递。
2. Session Key的安全发布。
再加上时间戳的使用就很大程度上的保证了用户鉴别的安全性。并且利用Session Key,在通过鉴别之后Client和Service之间传递的消息也可以获得Confidentiality(机密性), Integrity(完整性)的保证。不过由于没有使用非对称密钥自然也就无法具有抗否认性,这也限制了它的应用。不过相对而言它比X.509 PKI的身份鉴别方式实施起来要简单多了。
从kerberos协议的基础原理,在Hadoop上的应用,主要也就是两个过程,KDC为客户端上生成TGT,客户端和服务端通过TGT认证后通信。
2、Hadoop集群内应用kerberos认证
Hadoop集群内部使用Kerberos进行认证
具体的执行过程可以举例如下:
使用kerberos进行验证的原因
如此,维护KDC数据库是应用kerberos协议的基础。下面就看Hadoop上怎么增加Kerberos认证。
- 可靠 Hadoop 本身并没有认证功能和创建用户组功能,使用依靠外围的认证系统
- 高效 Kerberos使用对称钥匙操作,比SSL的公共密钥快
- 操作简单 用户可以方便进行操作,不需要很复杂的指令。比如废除一个用户只需要从Kerbores的KDC数据库中删除即可。
3、Hadoop平台上添加Kerberos认证,首要两步:
1)第一步自然是部署KDC,并配置KDC服务器上的相关文件,其中/etc/krb5.conf要复制到集群内所有机子,并创建principal数据库。2)创建认证规则principals和keytab,这个很重要,就是生成每个客户端相应的秘钥,Keytab是融合主机和Linux上账号而生成的,复制keytab到相应节点。
可参考:http://blog.chinaunix.net/uid-1838361-id-3243243.html
4、Hadoop通过kerberos安全认证的分析
Hadoop加入Kerberos认证机制,使得集群中的节点是信赖的。Kerberos首先通过KDC生成指定节点包含主机和账号信息的密钥,然后将认证的密钥在集群部署时事先放到可靠的节点上。集群运行时,集群内的节点使用密钥得到认证,只有被认证过节点才能正常使用。企图冒充的节点由于没有事先得到的密钥信息,无法与集群内部的节点通信。防止了恶意的使用或篡改Hadoop集群的问题,确保了Hadoop集群的可靠安全。
1)Hadoop的安全问题
——用户到服务器的认证问题
NameNode,,JobTracker上没有用户认证
用户可以伪装成其他用户入侵到一个HDFS 或者MapReduce集群上。
DataNode上没有认证
Datanode对读入输出并没有认证。导致如果一些客户端如果知道block的ID,就可以任意的访问DataNode上block的数据
JobTracker上没有认证
可以任意的杀死或更改用户的jobs,可以更改JobTracker的工作状态
——服务器到服务器的认证问题
没有DataNode, TaskTracker的认证
用户可以伪装成datanode ,tasktracker,去接受JobTracker, Namenode的任务指派。
2)Kerberos解决方案
kerberos实现的是机器级别的安全认证,也就是前面提到的服务到服务的认证问题。事先对集群中确定的机器由管理员手动添加到kerberos数据库中,在KDC上分别产生主机与各个节点的keytab(包含了host和对应节点的名字,还有他们之间的密钥),并将这些keytab分发到对应的节点上。通过这些keytab文件,节点可以从KDC上获得与目标节点通信的密钥,进而被目标节点所认证,提供相应的服务,防止了被冒充的可能性。
——解决服务器到服务器的认证
由于kerberos对集群里的所有机器都分发了keytab,相互之间使用密钥进行通信,确保不会冒充服务器的情况。集群中的机器就是它们所宣称的,是可靠的。
防止了用户伪装成Datanode,Tasktracker,去接受JobTracker,Namenode的任务指派。
——解决client到服务器的认证
Kerberos对可信任的客户端提供认证,确保他们可以执行作业的相关操作。防止用户恶意冒充client提交作业的情况。
用户无法伪装成其他用户入侵到一个HDFS 或者MapReduce集群上
用户即使知道datanode的相关信息,也无法读取HDFS上的数据
用户无法发送对于作业的操作到JobTracker上
——对用户级别上的认证并没有实现
无法控制用户提交作业的操作。不能够实现限制用户提交作业的权限。不能控制哪些用户可以提交该类型的作业,哪些用户不能提交该类型的作业。这个可以通过ACL来控制,对具体文件的读写访问进行有效管理。此前笔者对ACL有一个初步的了解,见博客http://blog.csdn.net/fjssharpsword/article/details/51280335
实际上,Hadoop平台自身也在不断完善,而对其集成的组件和整体机制了解,笔者也在不断加深,此前的一些错误认识也在不断调整。