Linux命令---管道命令(cut、sort、wc、uniq、tee、tr、join、split、xargs、减号-)
本文目录:
-
-
- 1.字符串截取:cut
- 2.排序:sort
- 3.去重:uniq
- 4.计算:wc
- 5.双向重导向:tee
- 6.字符转换命令:tr
- 7.字符转换命令:join
- 8.分区命令:split (即:大文件拆成小文件)
- 9.参数代换:xargs
- 11.减号 -
-
1.字符串截取:cut
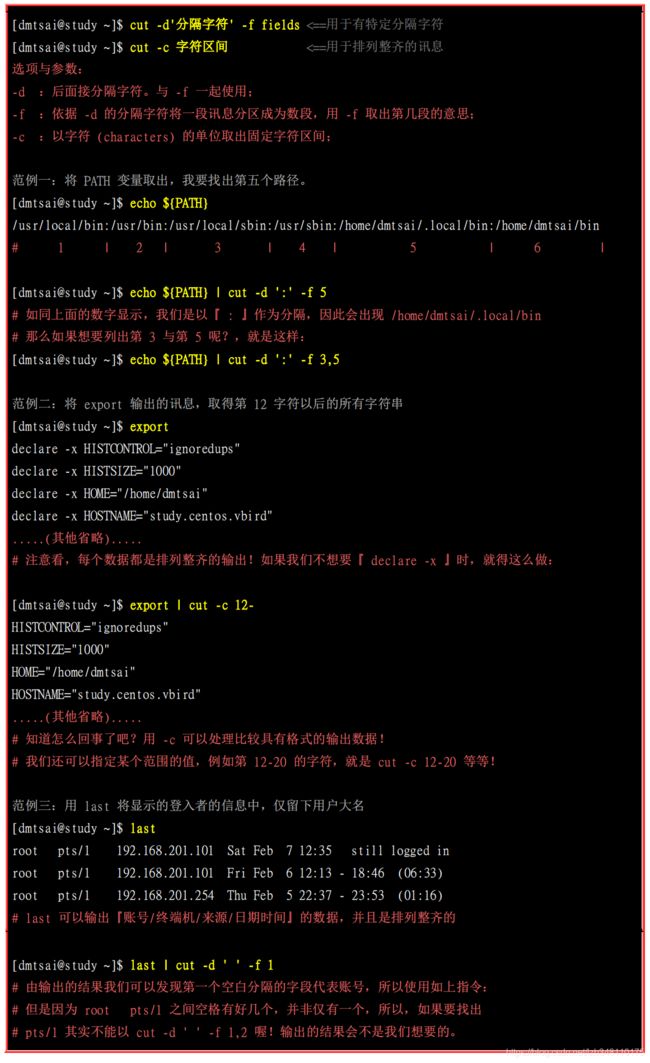
cut 主要的用途在于将『同一行里面的数据进行分解!』。最常使用在分析一些数据或文字数据的时候!要注意的是,一般来说,cut 命令通常是针对『一行』的数据来分析,并不是整篇内容分析的。
2.排序:sort
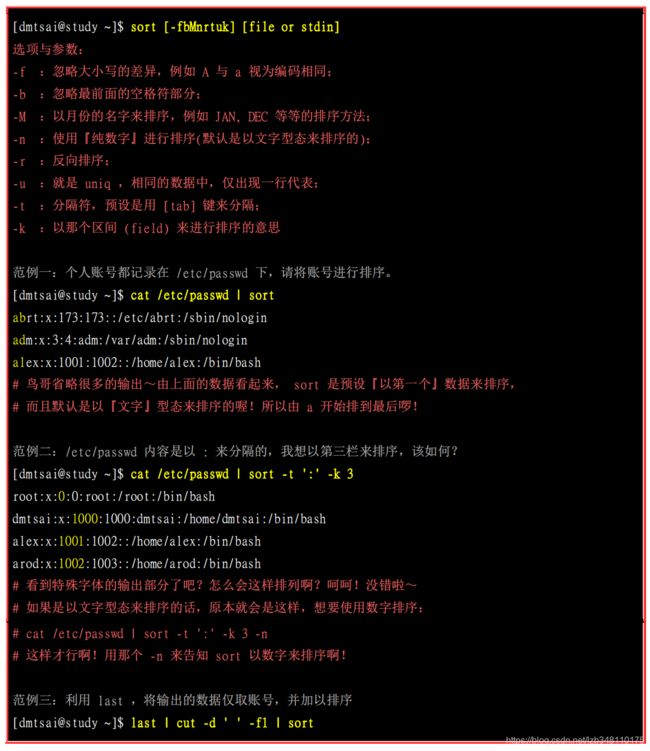
sort 可以帮我们进行排序,而且可以依据不同的数据型态来排序喔! 例如数字与文字的排序就不一样。此外,排序的字符与语系的编码有关
3.去重:uniq
uniq 用于去重 (范例一应该有点问题,排序后取出一位,应该还得加| head -1)
uniq 去重指令,是将重复的东西减少,所以必须『配合排序过的文件』来处理!

4.计算:wc
wc 命令,用来帮我们计算数据有多少字?多少行?多少个字符等。它是相当有用的计算文件内容的一个工具。

5.双向重导向:tee
双向重导向:tee (同>,>>,<,<< 数据流重导向一样)。我们知道 > 会将数据流整个传送给文件或装置,因此我们除非去读取该文件或装置, 否则就无法继续利用这个数据流。
万一我想要将这个数据流的处理过程中将某段内容存下来,应该怎么做? 利用 tee 就可以啰~tee 会同时将数据流分送到文件与屏幕 (screen);而输出到屏幕的,其实就是 stdout ,那就可以让下个指令继续处理喔!
tee 可以让 standard output 转存一份到文件内并将同样的数据继续送到屏幕去处理! 这样除了可以让我们同时分析一份数据并记录下来之外,还可以作为处理一份数据的中间暂存盘记录之用!
我们可以这样简单的看一下:


6.字符转换命令:tr
tr 命令用于转换或删除文件中的字符。
tr 指令从标准输入设备读取数据,经过字符串转译后,将结果输出到标准输出设备。
语法:
tr [OPTION]…SET1[SET2]
参数说明:(还有其他的参数,用上概率不大,此处只介绍能用上的)
-d:删除指令字符
-s:缩减连续重复的字符成指定的单个字符

7.字符转换命令:join
join 看字面上的意义 (加入/参加) 就可以知道,他是在处理两个文件之间的数据, 而且,主要是在处理『两个文件当中,有 "相同数据" 的那一行,才将他加在一起』的意思。
需要特别注意的是,在使用 join 之前,你所需要处理的文件应该要事先经过排序 (sort) 处理!否则有些比对的项目会被略过呢!
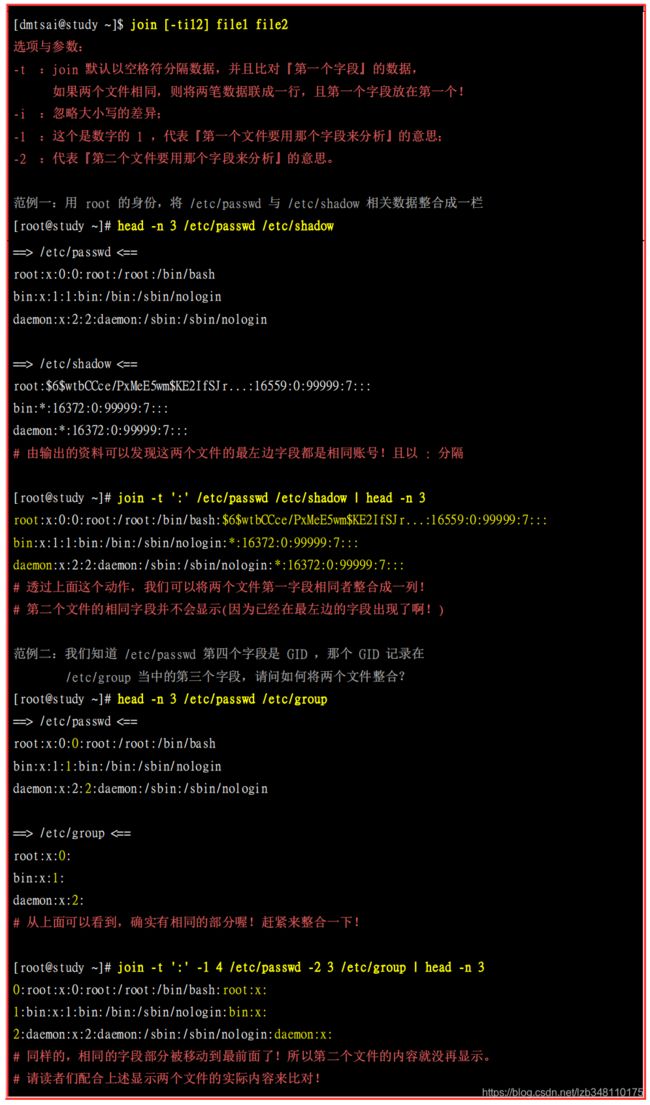
这个 join 在处理两个相关的数据文件时,就真的是很有帮助的啦! 例如上面的案例当中,我的 /etc/passwd, /etc/shadow, /etc/group 都是有相关性的, 其中 /etc/passwd, /etc/shadow 以账号为相关性,至于 /etc/passwd, /etc/group 则以所谓的 GID (账号的数字定义) 来作为他的相关性。根据这个相关性,我们可以将有关系的资料放置在一起!这在处理数据可是相当有帮助的! 但是上面的例子有点难,希望您可以静下心好好的看一看原因喔
此外,需要特别注意的是,在使用 join 之前,你所需要处理的文件应该要事先经过排序 (sort) 处理!否则有些比对的项目会被略过呢!特别注意了!
8.分区命令:split (即:大文件拆成小文件)
如果你有文件太大,导致一些携带式装置无法复制的问题,嘿嘿!找 split 就对了! 他可以帮你将一个大文件,依据文件大小或行数来分区,就可以将大文件分区成为小文件了! 快速又有效啊!真不错~
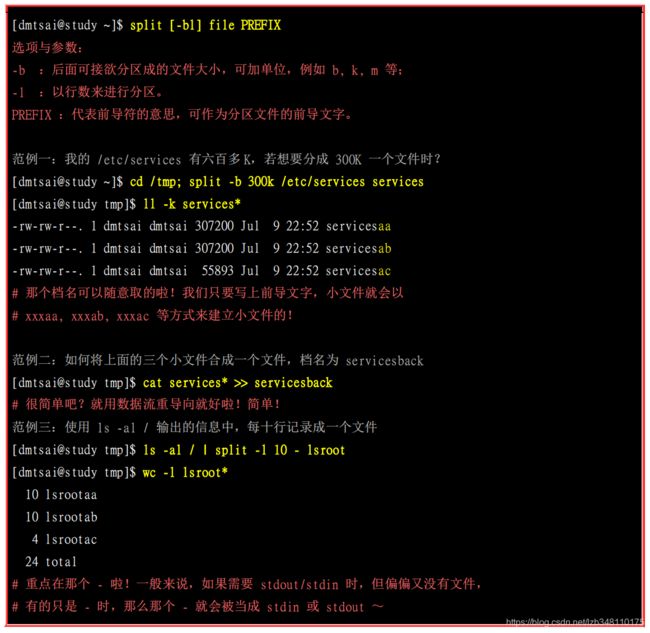
在 Windows 操作系统下,你要将文件分区需要如何作?伤脑筋吧!在 Linux 底下就简单的多了!你要将文件分区的话,那么就使用 -b size 来将一个分区的文件限制其大小,如果是行数的话,那么就使用 -l line 来分区!好用的很!如此一来,你就可以轻易的将你的文件分区成某些软件能够支持的最大容量 (例如 gmail 单一信件 25MB 之类的!),方便你 copy 啰!
注意:
重点在那个 - 啦!一般来说,如果需要 stdout/stdin 时,但偏偏又没有文件,有的只是 - 时,那么那个 - 就会被当成 stdin 或 stdout ~
9.参数代换:xargs
其实,在 man xargs 里面就有三四个小范例,您可以自行参考一下内容。 此外, xargs 真的是很好用的一个玩意儿!您真的需要好好的参详参详!使用 xargs 的原因是, 很多指令其实并不支持管线命令,因此我们可以透过 xargs 来提供该指令引用 standard input 之用!举例来说,我们使用如下的范例来说明:

11.减号 -
管线命令在 bash 的连续的处理程序中是相当重要的!另外,在 log file 的分析当中也是相当重要的一环, 所以请特别留意!另外,在管线命令当中,常常会使用到前一个指令的 stdout 作为这次的 stdin , 某些指令需要用到文件名 (例如 tar) 来进行处理时,该 stdin 与 stdout 可以利用减号 "-" 来替代, 举例来说:
