Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism论文笔记
之前毕设是做微博NER的,无意之中翻到了这篇论文,个人感觉这篇文章还是比较有价值的,在此简单介绍一下。
论文链接:https://www.aclweb.org/anthology/D18-1017(ACL2018)
code:https://github.com/CPF-NLPR/AT4ChineseNER
核心思想
这篇文章做的最核心的事情就是标题中提到的这几个事儿:
- Adversial:对抗
文章本身采用的结构是多任务学习,框架还是熟悉的BiLSTM+CRF,只不过是通过多任务学习共享一个BiLSTM,分词和NER一左一右。这里采用对抗训练解决分词提供的不正确的信息。
- Transfer:迁移
文章做的是中文微博的命名实体识别,数据集巨小。如果不使用迁移学习(也就是常说的多任务学习),单纯的从文本中当前任务进行学习的话,很难有大的提升。
- Self-attention:自注意力
大家最熟悉的NER结构就是BiLSTM+CRF,十分常见,效果也有保障。文章认为,self-attention可以提升前后文依赖关系的发掘程度(说白了就是能刷分高点),而BiLSTM能做到的十分有限。
以上就是个人总结的这篇文章的简要贡献,如果是想水一水逛一逛的话,就可以结束了;下面是详细的笔记。
Motivation
任何一篇文章提出来,一定是有问题需要解决的。问题可能多种多样,比如我觉得当前模型有什么信息没有利用啦,现存研究没有考虑到什么啦blablabla(说白了就是你的模型效果没我好,我分高我说了算),不论是什么理由,他总会有一个(甚至多个)。
那这篇文章的动机是什么呢?
文章是做微博的NER,前人的工作已经从多任务学习开始入手了,所以这篇文章认为:多任务学习中,我们使用的是中文分词和命名实体识别两个任务,目的是为了从分词中学习到词边界的信息,以用来给NER提供支持;然而,分词所提供的信息,并不都一定正确。这涉及到分词任务和NER任务的边界不统一的问题,作者这里给了一个例子:
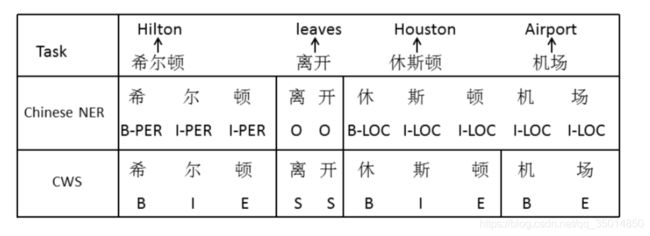
显然,如果我们把分词的信息全部融合进来的话,会在一定程度上影响NER的结果。分词的时候,休斯顿机场会被切开;但是在NER的过程中,这是一个实体,是不能切开的。所以,作者对于这个问题,提出了使用对抗学习来解决。另外,作者认为,任意字符都可以提供信息,所以引入了self-attention机制可以捕获文本中的长距离依赖(熟悉attention机制的同学应该清楚,attention是全连接的,相比BiLSTM来说对于长距离依赖的捕获能力要强得多)。
Model
模型当然要有图,所以先上图:
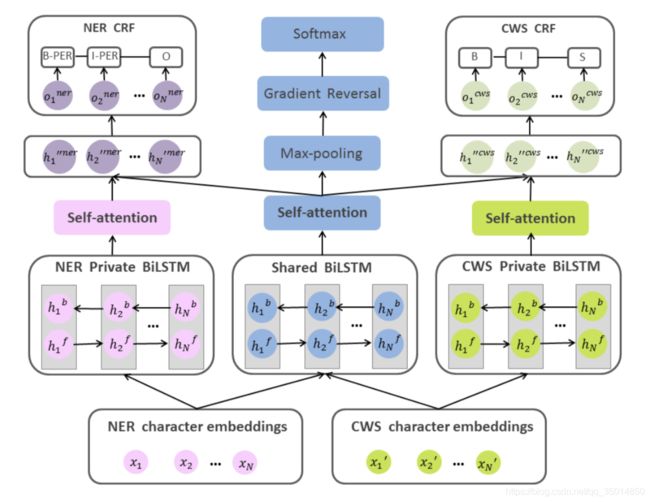
模型看起来花里胡哨,但实际上很好理解:首先是embedding,不同的任务是单独使用的,NER专用或者CWS专用。之后NER的embedding分别送进NER的BiLSTM和共享BiLSTM,分词同理;然后三个BiLSTM分别过一个self-attention。之后,NER和CWS分别解码,使用各自的CRF;共享层因为肩负实现对抗学习的使命,所以之后连接的部分会产出一个adversial loss,用来优化。先经过一个max pooling,之后做一个梯度反转(不了解的可以查一下,这块是为了使鉴别器分不清进入softmax的是哪个任务,以达到实现对抗学习,学习到正确的词边界的目的),然后就是softmax。这里的softmax是用来预测当前进行的是哪一项任务(NER或CWS,因为这两个任务不是同时进行训练的,而是单独的)。
之后我们对每一部分进行介绍。
Embedding
两个分离的embedding,分别应用到各自对应的任务上。相同的character对应到不同的两个embedding,这没什么好说的。
BiLSTM
这里,模型中有三个BiLSTM:分别是NER和CWS的BiLSTM和共享的BiLSTM。熟悉CWS和NER或者序列标注任务的一定知道这个经典的结构。NER和CWS的BiLSTM与往常一样,计算方法如下:
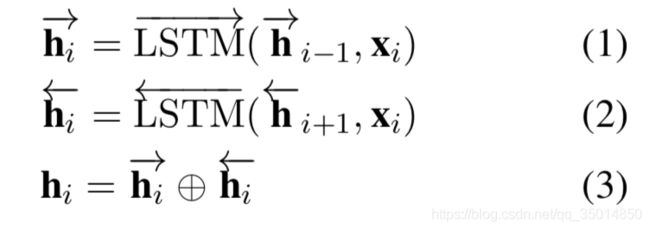
一个前向,一个后向,最后做一个拼接,这也没什么好说的。
值得注意的是共享的BiLSTM,因为这部分两个任务都有涉及,而且在训练过程中,NER和CWS并不是同时进行的,所以使用公式总结的话,就变成这个样子:
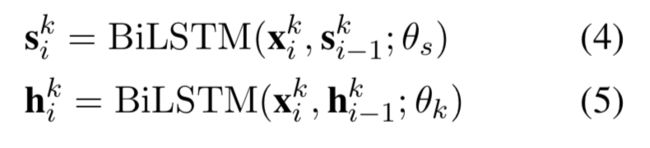
k指代的是当前的任务,范围就是{NER,CWS},最后一项代表当前网络的参数。
Self-attention
出了BiLSTM之后,就要进入到attention层中。前面提到过,attention可以很好的捕获长距离依赖,可以利用到很多信息(RNN类的网络,如BiLSTM等,即便是为了记忆而设计的,但是经过很多的时间步之后,信息丢失的很严重,几乎记不起很久之前发生的事情了),而BiLSTM很难做到这一点。attention的计算公式如下:
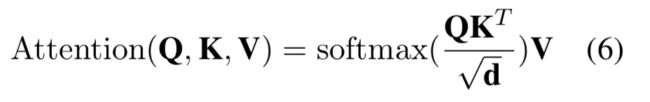
Q,K,V分别是attention机制中的query,key和value,其中Q/K是输入(从BiLSTM层出来之后需要做一个线性变换,也就是乘一个矩阵),V是输出。d是当前的维度。Q*K需要对K做一个转置。这样就获得了attention的输出。
具体到这个网络中,计算公式如下:
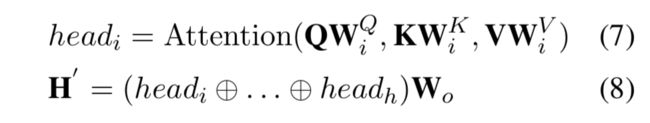
这个就是作者对输入进行的处理。首先Q=K,做线性变换之后计算attention分数(因为这里使用的是多头attention,所以要计算多次);之后将每个头的结果做一个拼接,再做一个线性变换,就获得了结果。
CRF
要做序列标注任务,大概率少不了CRF。这里每个任务一个专属的CRF,用来在该任务训练时进行解码。首先对上一层的结果做一个拼接:
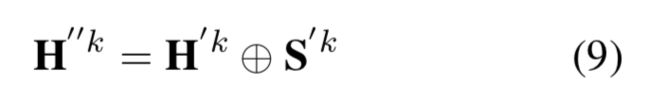
把当前任务的BiLSTM的输出和共享的BiLSTM输出拼接起来。之后就送进CRF中:
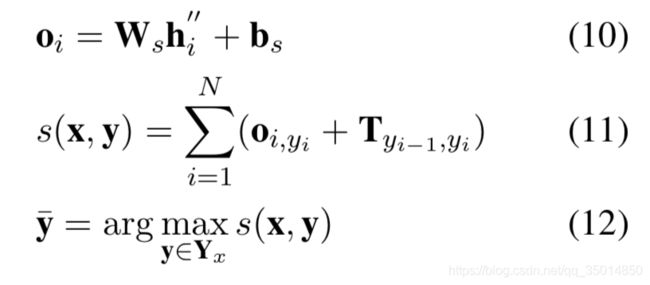
W和b是可训练的变量(也就是矩阵)。o是初始概率矩阵,T是转移概率矩阵,yi代表第i个词的标注结果。之后,取能够使式(11)结果最大的y,也就是得分最高的标注结果,使用viterbi解码,这样就完成了标注过程。
那么,这一部分的loss是怎么计算的呢?这里使用的是负对数似然,公式如下:
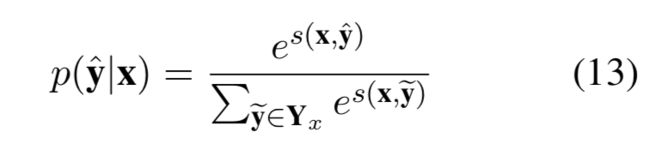
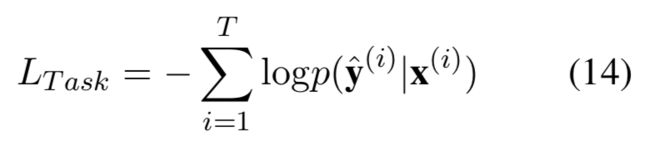
对于正在训练的当前任务(NER或者CWS),x是给定的文本,y是根据文本打出来的标签,loss是对p(y|x)求对数再取负,p(y|x)可以简单理解为,已知文本序列x,求得标注序列y的概率。但是,这么多结果(i从1到T)之中,只会有一个是正确的,所以除非正确的结果概率为1,log之后为0,loss为0,否则loss一定是一个正数,且错误结果的概率越高,概率(0~1之间)取对数为负求和取负数为正,loss也就越大。这里就是NER和CWS的loss计算。
Task discriminator
说了这么多,还是没有提到对抗学习这部分。实际上,对抗学习就是在这一部分实现的。引入对抗学习的意义就是,确保多任务学习时,任务本身的特性不会参与到共享网络中,来影响其他任务的性能。这一部分计算公式如下:
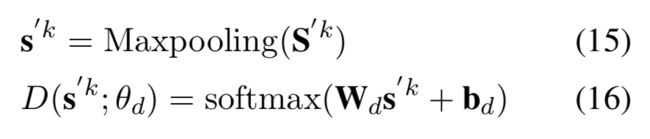
首先将attention出来的结果做一个max pooling,之后送进softmax之中,乘以一个权重,加一个偏置项,做一个分类;这里用来判断当前送进来的句子是来自哪个任务。这一部分的loss计算如下:
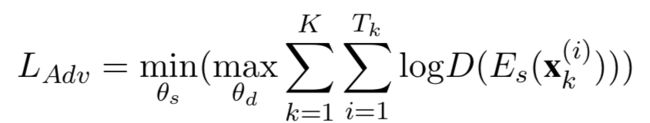
x是当前输入的文本,E是特征提取器(BiLSTM+attention),D是上文提到的softmax操作,max是task discriminator尽可能使每个句子都判对,min是共享参数层(shared BiLSTM+attention)尽量使task discriminator分不清来自于哪个任务。这样就完成了对抗训练的过程。
Training
刚刚介绍的只是NER和CWS的loss,实际上全局的loss是由对抗loss和上文提到的loss一起构成的。

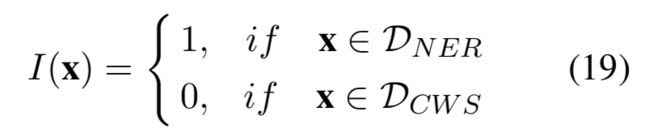
这里I(x)是指示函数,用来确定当前正在训练的任务。训练过程中,两个任务交替进行,不断更新参数。
Experiments
实验数据如下:
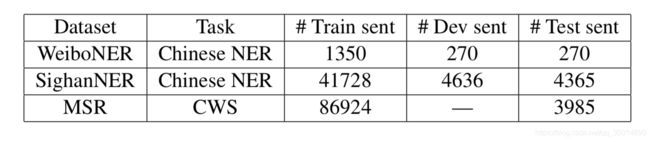
超参设置就不说了,能看懂英文的应该都能明白什么意思。。也没什么可讲的,毕竟是炼丹。。embedidng是百度百科和微博文本的word2vec预训练好的,这也符合当今nlp界的常规做法。
Results
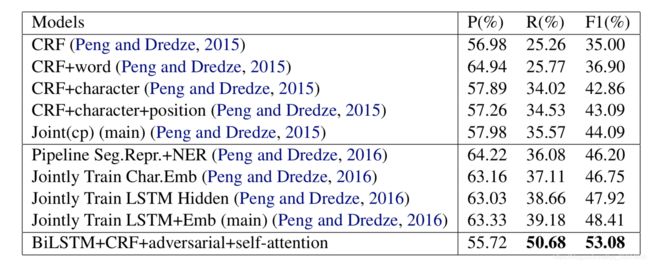
相比于之前weibo数据集上的实验,这篇文章的提升还是非常明显的(4.67%)。
作者也在更新了的weibo数据集上进行了实验,这里效果还是有的,但是不是很好,没有超过前人的记录。
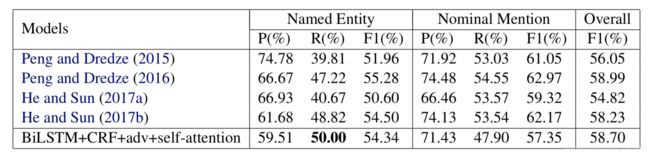
作者也在SighanNER上做了实验,选取了之前一个使用词边界信息(分词)的实验作为对照,也有1个点左右的提升。

之后作者做了一个实验分析,把各个部分都拆开来,用来说明各部分的作用。BiLSTM+CRF用作baseline,还有BiLSTM+CRF+分词,BiLSTM+CRF+对抗+分词,BiLSTM+CRF+self attention。结果如下:
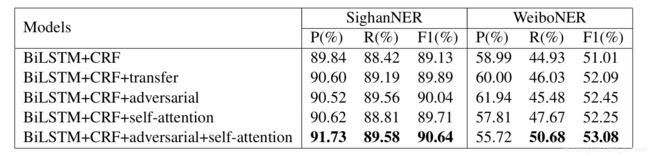
可以看到,实验结果还是很能说明问题的;分词信息对于NER来说还是可以提供很多帮助的,在应用对抗学习之后可以更好的学习边界信息,抛弃一部分噪音;单纯使用self attention也能够有很大提升,当然,最好的结果还是来自全部使用的模型。
样例学习
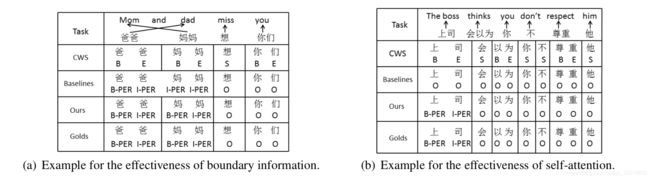
作者这里举了两个例子,一个是词边界信息引入的例子,另一个是self-attention机制引入的例子。当然,这边也没有进行更一步的实验分析来证明(当然也可能是由于神经网络的不可解释性),所以也就见仁见智了。有兴趣的可以进一步探究。