Python基础爬虫练习(深圳房产信息网站)
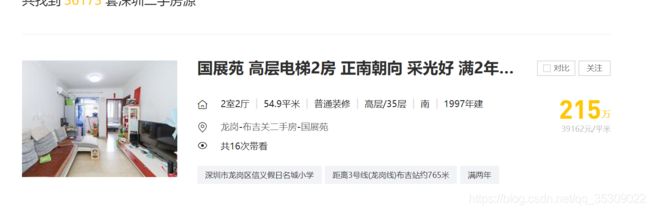
网站url:https://shenzhen.qfang.com/sale/f1
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 25 15:25:34 2018
@author: Belinda
"""
import requests
from lxml import etree
import csv
import time
def spider():
#定义爬虫头部
headers={'User-Agent':'Mozilla/5.0 (Window NT 10.0; WOW64)\ AppleWebKit/537.36 (KTML,like Gecko) Chrome/46.0.2490.80 Safari/537.36'}
pre_url='https://shenzhen.qfang.com/sale/f'
for i in range(1,100):#网页页面数为99,range(1,页面数+1)
html=requests.get(pre_url+str(i),headers=headers)
time.sleep(1)
selector=etree.HTML(html.text)
house_list=selector.xpath('//*[@id="cycleListings"]/ul/li')#用xpath方法定位元素
for house in house_list:
apartment=''.join(house.xpath('div[1]/p[1]/a/text()'))#去除列表两端的引号和括号,提取字段信息
house_layout=''.join(house.xpath('div[1]/p[2]/span[2]/text()'))
area=''.join(house.xpath('div[1]/p[2]/span[4]/text()'))
region=''.join(house.xpath('div[1]/p[3]/span[2]/a[1]/text()'))
total_price=''.join(house.xpath('div[2]/span[1]/text()'))
item=(apartment,house_layout,area,region,total_price)
print(item)#打印出每行的结果方便查看
writer.writerow(item)
if __name__=='__main__':
fp = open('./Qfang.csv', 'a+', encoding='utf-8', newline='')#写入csv文件
writer = csv.writer(fp)
writer.writerow(('apartment', 'house_layout','area','region', 'total_price'))#csv文件的每列的列表名
spider()
fp.close()
print("爬取结束!")
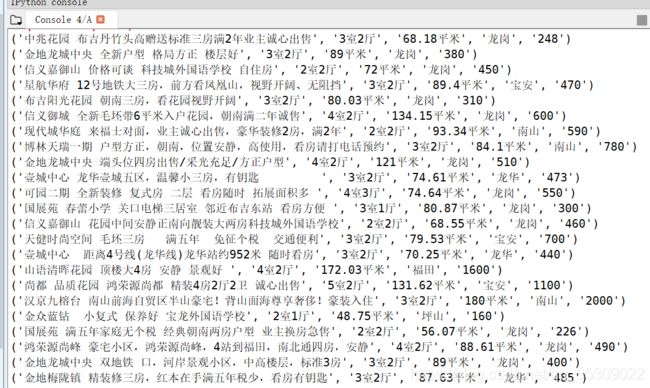
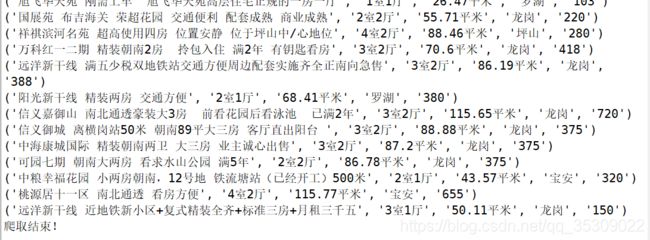
打开.spyder-p3文件下的对应Qfang.csv文件查看爬虫结果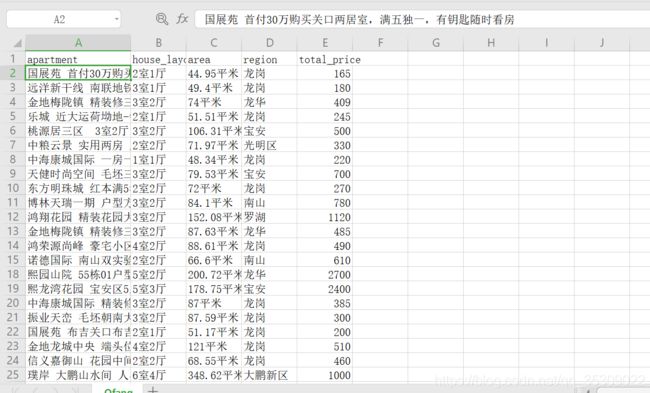
一共2970条数据