IDEA(2019.3)远程调试HADOOP(2.7.1)配置过程:WordCount实例
目的:在Idea上直接调试虚拟机中的HDFS,执行MapReduce,不需要将jar包上传到hadoop目录下再运行
配置环境:
虚拟机 hadoop 2.7.1
本地 hadoop 2.7.1
IDEA 版本 2019.3.3
Maven 3.6.3
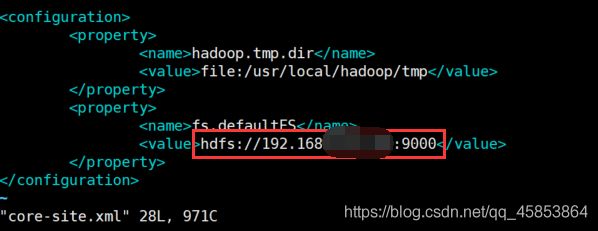
1. 修改虚拟机hadoop的etc/hadoop/core-site.xml
需要修改为hdfs://IP地址:9000 (主机名也可以,如果使用IP地址建议将IP地址设置为静态IP)
2. 使用xftp 等工具将HADOOP etc/hadoop目录下的core-site.xml和hdfs-site.xml 取出虚拟机备用
3. 在idea新建一个maven项目
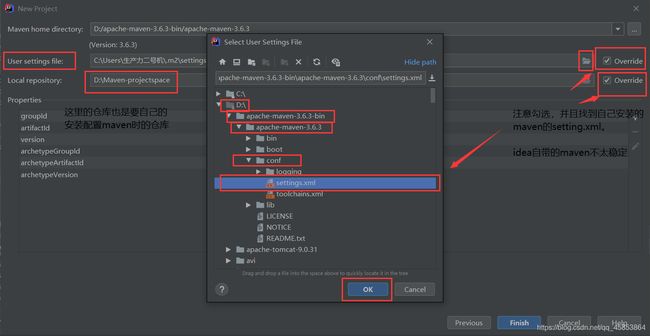
等待加载完成出现SUCCESS与src文件夹
创建文件夹
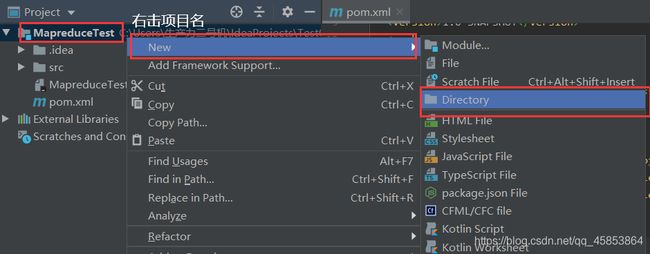
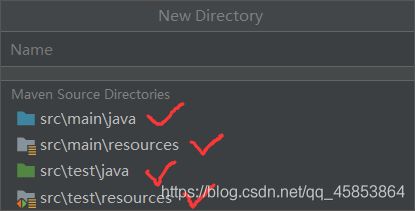
依次点击
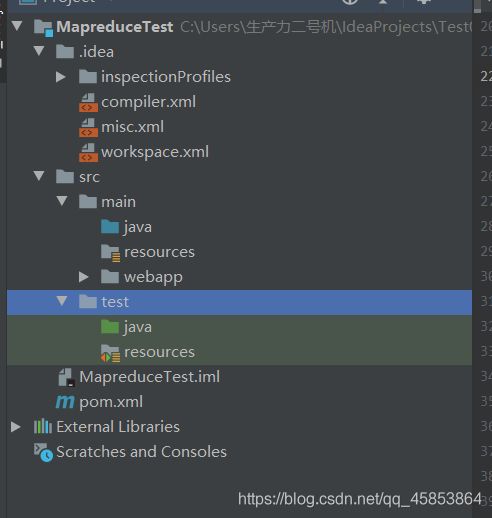
创建完成的目录如下:
4. 配置pom.xml文件
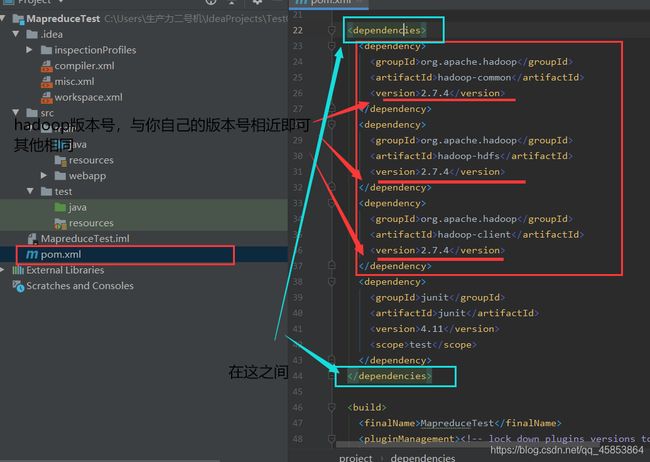
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
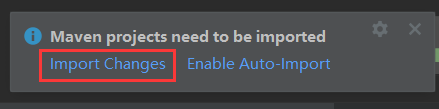
粘贴完毕后,右下角会出现弹窗
点击import Changes,然后等待自动加载
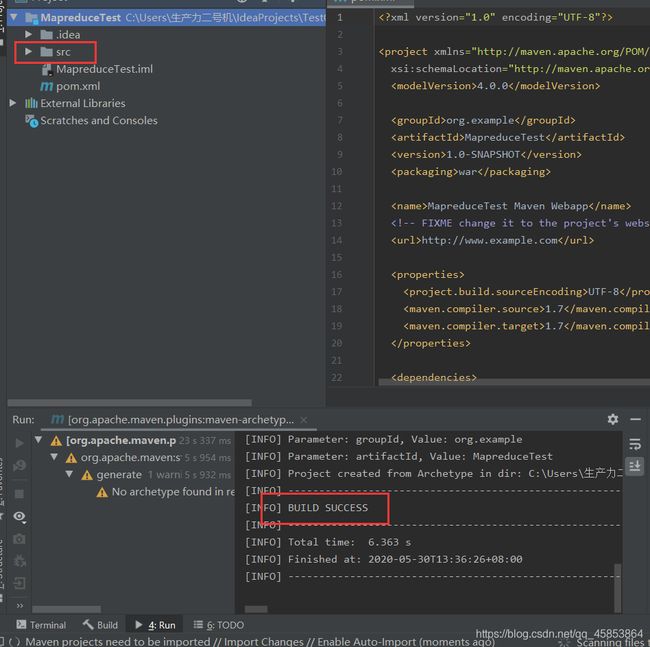
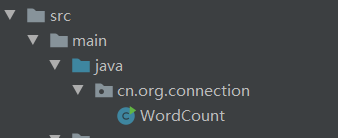
5.在src/main/java目录下新建package,在package下新建WordCount项目
WordCount代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
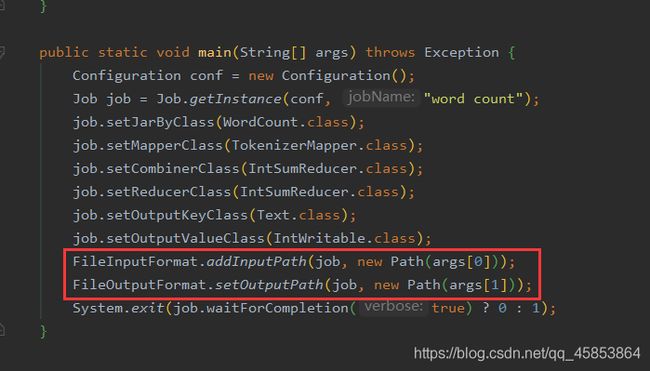
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
6.将之前从虚拟机复制出来的core-site.xml与hdfs-site.xml粘贴到src/main/resources中,并且在该目录创建log4j.properties文件
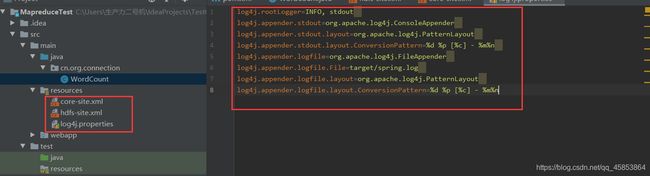
log4j.properties文件内容(复制粘贴即可)
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
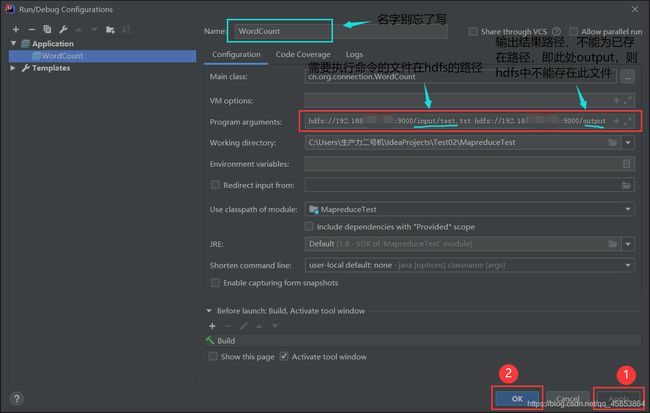
7.在WordCount代码中有两个路径变量,要为其设置变量
InputPath是需要处理文件所在的位置
OutputPath是处理完文件所在的位置
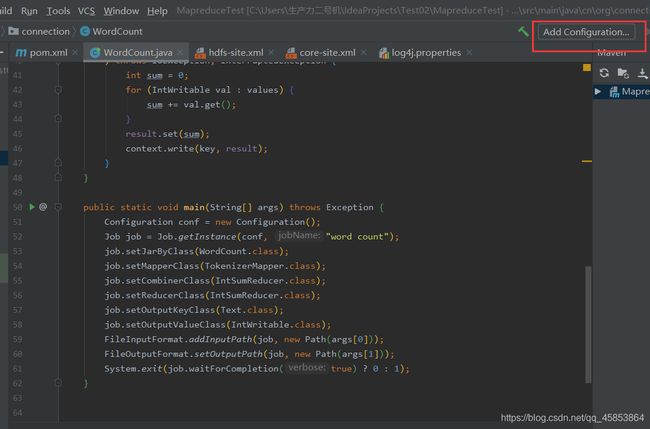
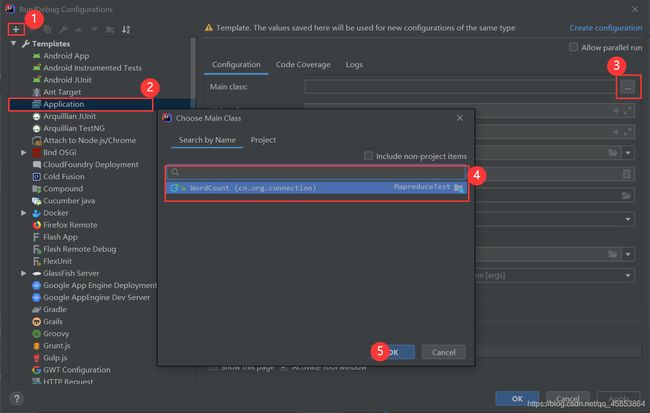
设置步骤如下:
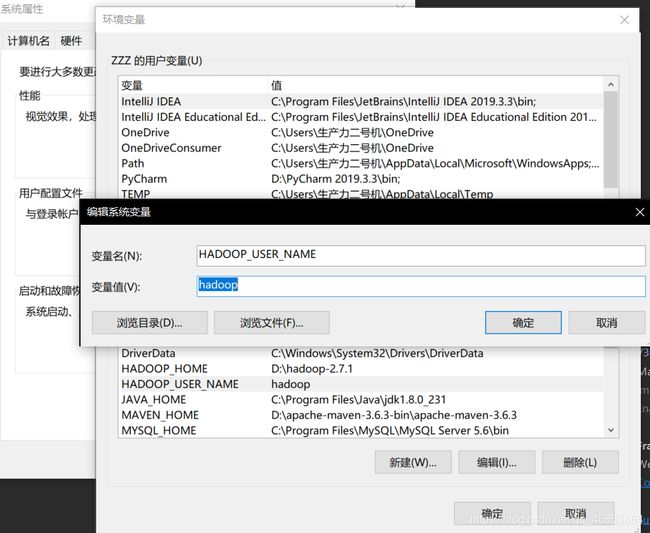
8.重点的一步(这种方法局限性大,建议使用方法二)
在windows系统环境变量中添加HADOOP_USER_NAME变量,防止访问权限问题报错(第二种方法在结尾)
添加后需要将IDEA IDE工具重启
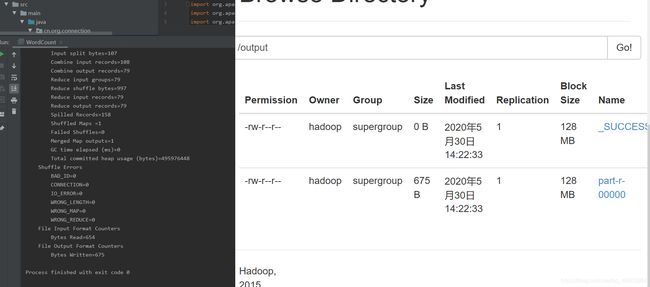
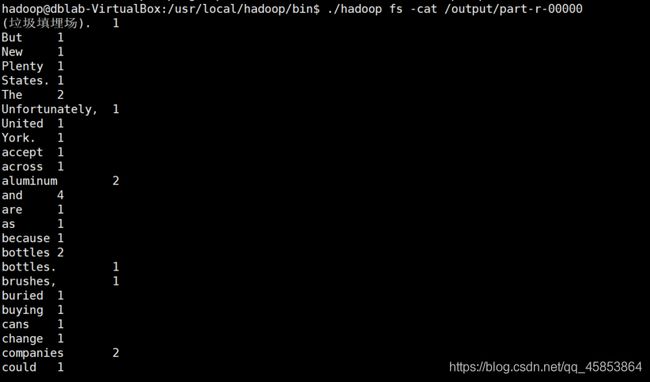
9.执行结果
第二种方式(建议使用)
在方法开头添加
Owner是什么,你就以什么身份访问HDFS,像我这里是hadoop,所以我就写的是System.setProperty(“HADOOP_USER_NAME”,“hadoop”);
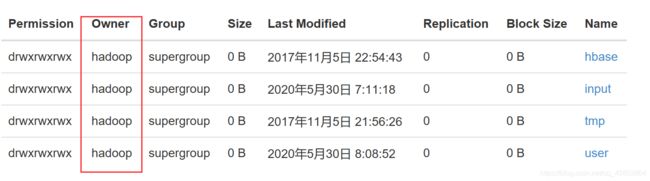
//设置客户端的访问身份,以hadoop身份访问HDFS
System.setProperty("HADOOP_USER_NAME","hadoop");
示例2:
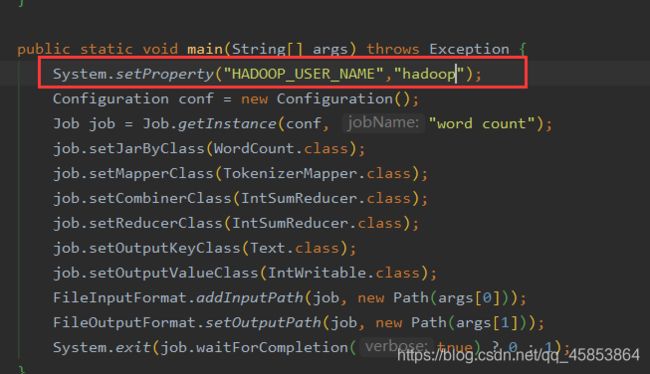
常见错误:
未关闭防火墙
未设置以什么身份访问hdfs
output路径存在