数据竞赛房租预测——赛题分析
“2019未来杯高校AI挑战赛 > 城市-房产租金预测”
目录
“2019未来杯高校AI挑战赛 > 城市-房产租金预测”
一、赛题概述
赛题说明
线上比赛数据发放与结果提交
比赛要求(略)
二、赛题分析
认识数据
对比赛数据做EDA
三、EDA分析
导入包
载入数据
总体情况概览
缺失值分析
单调特征列
-
一、赛题概述
-
赛题说明
线上比赛要求参赛选手根据给定的数据集,建立模型,预测房屋租金。
数据集中的数据类别包括租赁房源、小区、二手房、配套、新房、土地、人口、客户、真实租金等。
平台提供的数据包括训练集、预测试集(Test A)、正式测试集(Test B),详见数据集说明。
参赛选手需要将预测的结果按照测试集ID顺序输出以便平台对提交模型的结果进行验证。每天每个参赛者最多可以提交2次。
-
线上比赛数据发放与结果提交
训练数据Train_data和预测试集Test A将在赛事开始时开放,Train_data供参赛选手训练模型;预测试集Test A只供参赛选手熟悉提交流程,Test A的预测结果不计入正式成绩。
正式测试数据Test B在赛事规定的时间开放,仅供模型验证使用,禁止调整测试数据Test B的顺序及任何其他形式的修改。参赛选手需要在赛事结束前提交模型、代码以及预测结果。平台将及时更新结果排名,取最好成绩作为客观成绩,每人每天有2次提交机会。
-
比赛要求(略)
二、赛题分析
-
认识数据
了解比赛的背景: 房租价格预测
分类问题还是回归问题: 回归
熟悉比赛的评分函数:

-
对比赛数据做EDA
缺失值分析
特征值分析
是否有单调特征列(单调的特征列很大可能是时间)
特征nunique分布
统计特征值出现频次大于100的特征
Label分布
不同的特征值的样本的label的分布
三、EDA分析
-
导入包
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
# GBDT
from sklearn.ensemble import GradientBoostingRegressor
# XGBoost
import xgboost as xgb
# LightGBM
import lightgbm as lgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns-
载入数据
#载入数据
data_train = pd.read_csv('./train_data.csv')
data_train['Type'] = 'Train'
data_test = pd.read_csv('./test_a.csv')
data_test['Type'] = 'Test'
data_all = pd.concat([data_train, data_test], ignore_index=True)-
总体情况概览
# 总体情况
print(data_train.info())
print(data_train.describe())
data_train.head()输出结果:
RangeIndex: 41440 entries, 0 to 41439
Data columns (total 52 columns):
ID 41440 non-null int64
area 41440 non-null float64
rentType 41440 non-null object
houseType 41440 non-null object
houseFloor 41440 non-null object
totalFloor 41440 non-null int64
houseToward 41440 non-null object
houseDecoration 41440 non-null object
communityName 41440 non-null object
city 41440 non-null object
region 41440 non-null object
plate 41440 non-null object
buildYear 41440 non-null object
saleSecHouseNum 41440 non-null int64
subwayStationNum 41440 non-null int64
busStationNum 41440 non-null int64
interSchoolNum 41440 non-null int64
schoolNum 41440 non-null int64
privateSchoolNum 41440 non-null int64
hospitalNum 41440 non-null int64
drugStoreNum 41440 non-null int64
gymNum 41440 non-null int64
bankNum 41440 non-null int64
shopNum 41440 non-null int64
parkNum 41440 non-null int64
mallNum 41440 non-null int64
superMarketNum 41440 non-null int64
totalTradeMoney 41440 non-null int64
totalTradeArea 41440 non-null float64
tradeMeanPrice 41440 non-null float64
tradeSecNum 41440 non-null int64
totalNewTradeMoney 41440 non-null int64
totalNewTradeArea 41440 non-null int64
tradeNewMeanPrice 41440 non-null float64
tradeNewNum 41440 non-null int64
remainNewNum 41440 non-null int64
supplyNewNum 41440 non-null int64
supplyLandNum 41440 non-null int64
supplyLandArea 41440 non-null float64
tradeLandNum 41440 non-null int64
tradeLandArea 41440 non-null float64
landTotalPrice 41440 non-null int64
landMeanPrice 41440 non-null float64
totalWorkers 41440 non-null int64
newWorkers 41440 non-null int64
residentPopulation 41440 non-null int64
pv 41422 non-null float64
uv 41422 non-null float64
lookNum 41440 non-null int64
tradeTime 41440 non-null object
tradeMoney 41440 non-null float64
Type 41440 non-null object
dtypes: float64(10), int64(30), object(12)
memory usage: 16.4+ MB
None
ID area totalFloor saleSecHouseNum \
count 4.144000e+04 41440.000000 41440.000000 41440.000000
mean 1.001221e+08 70.959409 11.413152 1.338538
std 9.376566e+04 88.119569 7.375203 3.180349
min 1.000000e+08 1.000000 0.000000 0.000000
25% 1.000470e+08 42.607500 6.000000 0.000000
50% 1.000960e+08 65.000000 7.000000 0.000000
75% 1.001902e+08 90.000000 16.000000 1.000000
max 1.003218e+08 15055.000000 88.000000 52.000000
subwayStationNum busStationNum interSchoolNum schoolNum \
count 41440.000000 41440.000000 41440.000000 41440.000000
mean 5.741192 187.197153 1.506395 48.228813
std 4.604929 179.674625 1.687631 29.568448
min 0.000000 24.000000 0.000000 9.000000
25% 2.000000 74.000000 0.000000 24.000000
50% 5.000000 128.000000 1.000000 47.000000
75% 7.000000 258.000000 3.000000 61.000000
max 22.000000 824.000000 8.000000 142.000000
privateSchoolNum hospitalNum ... tradeLandArea landTotalPrice \
count 41440.000000 41440.000000 ... 41440.000000 4.144000e+04
mean 6.271911 4.308736 ... 12621.406425 1.045363e+08
std 4.946457 3.359714 ... 49853.120341 5.215216e+08
min 0.000000 0.000000 ... 0.000000 0.000000e+00
25% 2.000000 1.000000 ... 0.000000 0.000000e+00
50% 5.000000 4.000000 ... 0.000000 0.000000e+00
75% 9.000000 6.000000 ... 0.000000 0.000000e+00
max 24.000000 14.000000 ... 555508.010000 6.197570e+09
landMeanPrice totalWorkers newWorkers residentPopulation \
count 41440.000000 41440.000000 41440.000000 41440.000000
mean 724.763918 77250.235497 1137.132095 294514.059459
std 3224.303831 132052.508523 7667.381627 196745.147181
min 0.000000 600.000000 0.000000 49330.000000
25% 0.000000 13983.000000 0.000000 165293.000000
50% 0.000000 38947.000000 0.000000 245872.000000
75% 0.000000 76668.000000 0.000000 330610.000000
max 37513.062490 855400.000000 143700.000000 928198.000000
pv uv lookNum tradeMoney
count 41422.000000 41422.000000 41440.000000 4.144000e+04
mean 26945.663512 3089.077085 0.396260 8.837074e+03
std 32174.637924 2954.706517 1.653932 5.514287e+05
min 17.000000 6.000000 0.000000 0.000000e+00
25% 7928.000000 1053.000000 0.000000 2.800000e+03
50% 20196.000000 2375.000000 0.000000 4.000000e+03
75% 34485.000000 4233.000000 0.000000 5.500000e+03
max 621864.000000 39876.000000 37.000000 1.000000e+08
[8 rows x 40 columns]
ID area rentType houseType houseFloor totalFloor houseToward houseDecoration communityName city ... landMeanPrice totalWorkers newWorkers residentPopulation pv uv lookNum tradeTime tradeMoney Type
0 100309852 68.06 未知方式 2室1厅1卫 低 16 暂无数据 其他 XQ00051 SH ... 0.0000 28248 614 111546 1124.0 284.0 0 2018/11/28 2000.0 Train
1 100307942 125.55 未知方式 3室2厅2卫 中 14 暂无数据 简装 XQ00130 SH ... 0.0000 14823 148 157552 701.0 22.0 1 2018/12/16 2000.0 Train
2 100307764 132.00 未知方式 3室2厅2卫 低 32 暂无数据 其他 XQ00179 SH ... 0.0000 77645 520 131744 57.0 20.0 1 2018/12/22 16000.0 Train
3 100306518 57.00 未知方式 1室1厅1卫 中 17 暂无数据 精装 XQ00313 SH ... 3080.0331 8750 1665 253337 888.0 279.0 9 2018/12/21 1600.0 Train
4 100305262 129.00 未知方式 3室2厅3卫 低 2 暂无数据 毛坯 XQ01257 SH ... 0.0000 800 117 125309 2038.0 480.0 0 2018/11/18 2900.0 Train
5 rows × 52 columns 简要分析
该份训练集包含 41440行×52列数据
目标变量是 真实房租价格- tradeMoney
大多数数据都是int或float型;有部分字段是object型,即文本型中文或英文的,如rentType字段,这些字段在之后需要做处理
-
缺失值分析
# 缺失值分析
def missing_values(df):
alldata_na = pd.DataFrame(df.isnull().sum(), columns={'missingNum'})
alldata_na['existNum'] = len(df) - alldata_na['missingNum']
alldata_na['sum'] = len(df)
alldata_na['missingRatio'] = alldata_na['missingNum']/len(df)*100
alldata_na['dtype'] = df.dtypes
#ascending:默认True升序排列;False降序排列
alldata_na = alldata_na[alldata_na['missingNum']>0].reset_index().sort_values(by=['missingNum','index'],ascending=[False,True])
alldata_na.set_index('index',inplace=True)
return alldata_na
missing_values(data_train)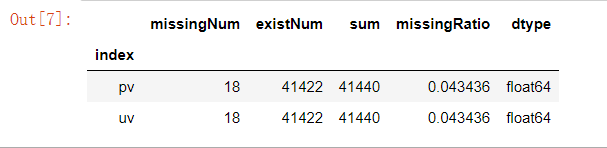
简要分析
结果是,仅有pv、uv存在缺失值,后面再探究会发现缺失的都是属于同一个plate,可能是官方直接删除了该plate的pv、uv
-
单调特征列
#是否有单调特征列(单调的特征列很大可能是时间)
def incresing(vals):
cnt = 0
len_ = len(vals)
for i in range(len_-1):
if vals[i+1] > vals[i]:
cnt += 1
return cnt
fea_cols = [col for col in data_train.columns]
for col in fea_cols:
cnt = incresing(data_train[col].values)
if cnt / data_train.shape[0] >= 0.55:
print('单调特征:',col)
print('单调特征值个数:', cnt)
print('单调特征值比例:', cnt / data_train.shape[0])
简要分析
先编写判断单调的函数 incresing, 然后再应用到每列上;
单调特征是 tradeTime,为时间列。
多说句额外的,时间列在特征工程的时候,不同的情况下能有很多的变种形式,比如按年月日分箱,或者按不同的维度在时间上聚合分组,等等
-
特征nunique分布
# 特征nunique分布
for feature in categorical_feas:
print(feature + "的特征分布如下:")
print(data_train[feature].value_counts())
if feature != 'communityName': # communityName值太多,暂且不看图表
plt.hist(data_all[feature], bins=3)
plt.show()
print(data_train['communityName'].value_counts())
print(data_test['communityName'].value_counts())简要分析
用自带函数value_counts() 来得到每个分类变量的 种类 分布;
并且简单画出柱状图。
rentType:4种,且绝大多数是无用的未知方式;
houseType:104种,绝大多数在3室及以下;
houseFloor:3种,分布较为均匀;
region: 15种;
plate: 66种;
houseToward: 10种;
houseDecoration: 4种,一大半是其他;
buildYear: 80种;
communityName: 4236种,且分布较为稀疏;
此步骤是为之后数据处理和特征工程做准备,先理解每个字段的含义以及分布,之后需要根据实际含义对分类变量做不同的处理。
-
统计特征值频次大于100的特征
# 统计特征值出现频次大于100的特征
for feature in categorical_feas:
df_value_counts = pd.DataFrame(data_train[feature].value_counts())
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = [feature, 'counts'] # change column names
print(df_value_counts[df_value_counts['counts'] >= 100])-
Label分布
# Labe 分布
fig,axes = plt.subplots(2,3,figsize=(20,5))
fig.set_size_inches(20,12)
sns.distplot(data_train['tradeMoney'],ax=axes[0][0])
sns.distplot(data_train[(data_train['tradeMoney']<=20000)]['tradeMoney'],ax=axes[0][1])
sns.distplot(data_train[(data_train['tradeMoney']>20000)&(data_train['tradeMoney']<=50000)]['tradeMoney'],ax=axes[0][2])
sns.distplot(data_train[(data_train['tradeMoney']>50000)&(data_train['tradeMoney']<=100000)]['tradeMoney'],ax=axes[1][0])
sns.distplot(data_train[(data_train['tradeMoney']>100000)]['tradeMoney'],ax=axes[1][1])

print("money<=10000",len(data_train[(data_train['tradeMoney']<=10000)]['tradeMoney']))
print("1000010000)&(data_train['tradeMoney']<=20000)]['tradeMoney']))
print("2000020000)&(data_train['tradeMoney']<=50000)]['tradeMoney']))
print("5000050000)&(data_train['tradeMoney']<=100000)]['tradeMoney']))
print("100000100000)]['tradeMoney'])) 
简要分析
将目标变量tradeMoney分组,并查看每组间的分布;
可以看出绝大多数都是集中在10000元以内的,并且从图中可以看到该分布是右偏的。
这里只是一种实现方式,完全可以将tradeMoney和其他字段一起结合起来查看,比如楼层高低,地区板块。