window下jupyter(anaconda)中使用findspark配置spark
上一篇讲完zeppelin配置spark,zeppelin启动太慢了,经常网页上interpreter改着就卡死,需要后面zeppelin.cmd窗后点击才有反应,而且启动贼慢。
因为本来就安装了Anaconda2,索性给jupyter也配置上spark;
查阅资料有两类:
方法一:给jupyter 安装上jupyter-scala kernerl 和jupyter-spark kernerl ,这个启动据说也慢,自己还未安装尝试。
方法二:仅仅pip install findspark 就行,这个方便简单(如果要学scala还得用第一种),这篇也是将这种方法
一:前提
java 8及以上、scala、jupyter(anaconda python)、spark安装弄好了,环境变量都配置好了,而且python pip的pyspark都已经弄好了,全都可以参考我之前的博文
讲讲简单关系,spark是用scala编写的,scala底层用的java 8及以上,使用python编写spark程序,需要用到pyspark第三方包去转为jvm中调用核心,而findspark可以提供简便的初始化spark环境,后续直接使用pyspark即可。
以下均是window 10下的安装
java 安装:https://mp.csdn.net/postedit/94853438
scala 安装:https://blog.csdn.net/u010720408/article/details/94856482
spark 安装:https://blog.csdn.net/u010720408/article/details/94876941
hadoop 安装:https://blog.csdn.net/u010720408/article/details/94898160 (仅仅玩spark单机,且用不到hdfs就不用装)
anaconda和jupyter的我就懒得搞了,找教程弄吧。
pyspark 也很简单,就是200多M有点大,可下载后离线安装,会有pydoc、py4j依赖,这两也得pip安装,可以看我zeppelin中的配置pyspark部分 https://blog.csdn.net/u010720408/article/details/94969710
二:pip install findspark
(anaconda prompt中)

三:jupyter中验证
没错,前面做好了,直接就上手验证了
启动jupyter,复制里面的连接再浏览其中打开(直接只输入localhsot:8888 是不行的有token验证呢):

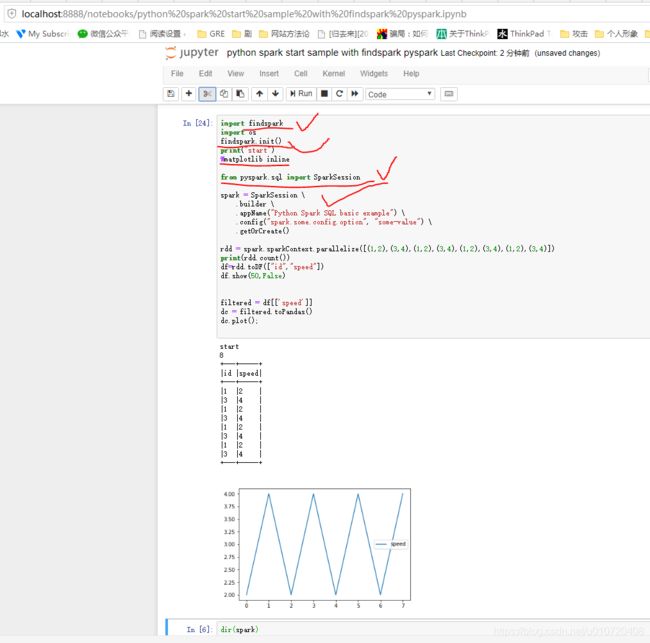
wonderful,好极了,打完收工。