HGAT-用于半监督短文本分类的异构图注意力网络

来源:EMNLP 2019
论文链接
代码及数据集链接
摘要
短文本分类在新闻和推特中找到了丰富和有用的标记,以帮助用户找到相关信息。由于在许多实际应用案例中缺乏有标记的训练数据,因此迫切需要研究半监督短文本分类。现有的研究主要集中在长文本上,并且由于稀疏性和有限的标记数据,而现有的研究应用在短文本上表现令人不满意。本文提出了一种新的基于异构图神经网络的半监督短文本分类方法,该方法充分利用了标记数据少、未标记数据大的特点,通过信息沿图传播实现半监督短文本分类。特别是,我们提出了一种灵活的HIN(异构信息网络)框架来对短文本建模,它可以集成任何类型的附加信息,以及捕捉它们的关系,以解决语义稀疏性。在此基础上,提出一种基于两级注意力机制的异构图注意力网络(HGAT),嵌入HIN 进行文本分类,其中两级注意力包括节点级和类型级注意力机制。注意力机制可以学习不同相邻节点的重要性以及不同节点(信息)类型对当前节点的重要性。大量的实验结果表明,我们提出的模型在六个基准数据集上都显著优于最新的方法。
1、背景
本文提出了一种新的基于异构图神经网络的半监督短文本分类方法,该方法充分利用有限标记数据和大量未标记数据,允许信息通过构建的图传播。特别,我们首先提出了一个灵活的 HIN 框架 ,用于短文本建模,它能够包含任何附加的信息(例如实体和主题),以及捕捉文本和附加信息之间的丰富关系。然后,我们提出一种基于两级注意力机制的异构图注意力网络(HGAT),嵌入HIN 进行文本分类,其中两级注意力包括节点级和类型级注意力机制。我们的 HGAT 方法考虑了不同节点类型的异构性。此外,双层注意机制捕获不同相邻节点的重要性(降低噪声信息的权重)和不同节点(信息)类型对当前节点的重要性。本文的主要贡献概括如下:
- 据我们所知,这是第一次尝试使用 HIN 对短文本和附加信息进行建模,并将 HIN 上的图神经网络用于半监督分类。
- 提出了一种新的基于双层注意机制的异构图注意网络(HGAT),该机制可以学习不同相邻节点的重要性以及不同节点(信息)类型对当前节点的重要性。
- 大量的实验结果表明,我们提出的HGAT模型在6个基准数据集上显著优于7种最新方法。
2、模型
2.1、短文本异构信息网络HIN
我们首先提出了一个用于短文本建模的HIN框架,它能够集成任何附加信息,并捕获文本和附加信息之间的丰富关系。这样就减少了短文本的稀疏性。
以往的研究从知识库中挖掘潜在主题和外部知识,以丰富短文本的语义。然而它们没有考虑语义关系信息,如实体关系。短文本的 HIN 框架是灵活的,它整合任何额外的信息和建模它们丰富的关系。这里,我们考虑两种类型的附加信息,即主题和实体。如图1所示,我们构造图 G = ( V , E ) G=(V,E) G=(V,E) , 它包括短文本集 D = { d 1 , ⋯ , d m } D=\{d_1,\cdots,d_m\} D={ d1,⋯,dm} 、主题集 T = { t 1 , ⋯ , t K } T=\{t_1,\cdots,t_K\} T={ t1,⋯,tK}和实体集 E = { e 1 , ⋯ , e n } E=\{e_1,\cdots,e_n\} E={ e1,⋯,en}做为节点,即 V = D ∪ T ∪ E V=D\cup T\cup E V=D∪T∪E。边集 E E E表示它们之间的关系。网络构建的细节描述如下。
首先,我们利用 LDA 挖掘潜在主题T来丰富短文本的语义。每个主题 t i = ( θ 1 , ⋯ , θ w ) t_i=(\theta_1,\cdots,\theta_w) ti=(θ1,⋯,θw)( w w w表示词汇量)是由单词的概率分布表示。我们把每个文档分配给前前P 个概率最高的主题。因此,如果将文档分配给主题,则会在文档和主题之间建立边。其次,我们识别文档 D 中的实体 E ,并使用实体链接工具 TAGME 将它们映射到 Wikipedia。如果文档包含实体,则在文档和实体之间建立边。我们将一个实体作为一个整体词,使用基于Wikipedia语料库的word2vec 学习实体嵌入。为了进一步丰富短文本的语义,促进信息传播,我们考虑了实体之间的关系。特别是,如果基于嵌入计算的两个实体之间的相似性得分(余弦相似性)高于预定义的阈值δ,则在它们之间建立一条边。通过结合主题、实体和关系,我们丰富了短文本的语义,从而大大有利于后续的分类任务。例如,如图1所示,短文本“the seed of Apple’s Innovation: In an era when most technology…”,被实体“Apple Inc”和“company”,以及主题“technology”,丰富了语义信息。因此,可以很有把握地把该短文本将其正确地归类为“business”类别。

2.2、HGAT模型
然后,我们提出了一种新的双层次注意机制(包括节点级和类型级)的 HGAT 模型(如图2所示),嵌入 HIN 来进行短文本分类。HGAT 利用异构图卷积来考虑不同类型信息的异构性。此外,双层注意机制捕获不同相邻节点的重要性(降低噪声信息的权重)和不同节点(信息)类型对特定节点的重要性。最后,它通过 softmax 层预测文档的标签。

2.2.1、异构图卷积
首先考虑节点(信息)的异构类型,描述 HGAT 中的异构图卷积。众所周知,GCN((Kipf and Welling, 2017) 是一个多层神经网络,它直接在同构图上操作,并根据节点邻域的性质归纳出节点的嵌入向量。具体来说就是,对于图 G = ( V , E ) G=(V,E) G=(V,E), V V V、 E E E是节点集和边集。 X ∈ R ∣ V ∣ × q X\in R^{|V|\times q} X∈R∣V∣×q是包含所有节点特征向量的矩阵。邻接矩阵 A ′ = A + I A'=A+I A′=A+I包含自连接。度矩阵为 对角矩阵 M M M,其中 M i , i = ∑ j A i , j ′ M_{i,i}=\sum_j A'_{i,j} Mi,i=∑jAi,j′。层之间传播规则如下:
H ( l + 1 ) = σ ( A ~ ⋅ H ( l ) ⋅ W ( l ) ) H^{(l+1)}=\sigma(\tilde{A}\cdot H^{(l)}\cdot W^{(l)}) H(l+1)=σ(A~⋅H(l)⋅W(l))其中 A ~ = M − 1 2 A ′ M − 1 2 \tilde{A}=M^{-\frac{1}{2}}A'M^{-\frac{1}{2}} A~=M−21A′M−21 是归一化邻接矩阵。 W ( l ) W^{(l)} W(l)是一个特定层的可训练变换矩阵。σ(·)表示激活函数,如ReLU。 H ( l ) H^{(l)} H(l) 是节点的第 l l l 层隐式表示, H 0 = X H_0=X H0=X。
不幸的是,由于节点异构性问题,GCN 不能直接应用于短文本的 HIN。具体来说,在 HIN中,我们有三种类型的节点:文档、主题和实体。它们具有不同特征空间。对于文档d∈D,我们使用 TF-IDF 向量作为其特征向量 x d x_d xd。对于主题 t∈T,单词分布 x t = ( θ 1 , ⋯ , θ w ) x_t=(\theta_1,\cdots,\theta_w) xt=(θ1,⋯,θw)用于表示主题特征向量。对于每个实体,为了充分利用相关信息,我们将其词向量嵌入和其维基百科文本的TF-IDF向量连接起来表示实体特征向量 x v x_v xv。
对于包含不同类型节点 T = { τ 1 , τ 2 , τ 3 } T=\{τ_1,τ_2,τ_3\} T={ τ1,τ2,τ3} 的 HIN,一种简单的方法是通过将不同类型节点的特征空间连接在一起来构造一个新的大特征空间。例如,每个节点表示为一个特征向量,与该节点类型不相关的维度取值为0。我们将这种使GCN适应 HIN 的基本方法称为 GCN-HIN。但是,由于忽略了不同信息类型的异构性,它的性能会降低。
为了解决这一问题,我们提出了异构图卷积,它考虑了不同类型信息的差异,并用不同类型信息各自的变换矩阵将它们投影到一个隐空间中,变换矩阵W考虑不同特征空间的差异,并将其投影到隐式公共空间 R q ( l + 1 ) \mathbb{R}^{q(l+1)} Rq(l+1)中。 H ( l + 1 ) = σ ( ∑ τ ∈ T A ~ τ ⋅ H τ ( l ) ⋅ W τ ( l ) ) H^{(l+1)}=\sigma(\sum_{\tau\in\Tau }\tilde{A}_{\tau}\cdot H_{\tau}^{(l)}\cdot W_{\tau}^{(l)}) H(l+1)=σ(τ∈T∑A~τ⋅Hτ(l)⋅Wτ(l))其中 A ~ τ ∈ R ∣ V ∣ × ∣ V τ ∣ \tilde{A}_{\tau}\in\mathbb{R}^{|V|\times|V_{\tau}|} A~τ∈R∣V∣×∣Vτ∣是 A ~ τ \tilde{A}_{\tau} A~τ 的子矩阵,它的行表示所有节点,列表示节点的 τ τ τ类型的邻居。节点的表示 H ( l + 1 ) H^{(l+1)} H(l+1)通过用各个类型 τ τ τ 的变换矩阵 W τ ( l ) ∈ R q ( l ) × q ( l + 1 ) W_{\tau}^{(l)}\in \mathbb{R}^{q^{(l)}\times q^{(l+1)}} Wτ(l)∈Rq(l)×q(l+1),对各类型 τ τ τ 下节点的嵌入 H τ ( l ) H_{\tau}^{(l)} Hτ(l)聚合得到。变换矩阵 W W W 考虑不同特征空间的差异,并将其投影到公共空间 R q ( l + 1 ) \mathbb{R}^{q^{(l+1)}} Rq(l+1)中。初始化 H τ ( 0 ) = X τ H_{\tau}^{(0)}=X_{\tau} Hτ(0)=Xτ。
2.2.2、双层注意力
通常,给定一个特定的节点,不同类型下相邻节点可能会对其产生不同的影响。例如,相同类型的相邻节点可以携带更多有用的信息。此外,同类型下各相邻节点也可能具有不同的重要性。为了同时捕捉节点级和类型级的不同重要性,我们设计了一种新的双层注意力机制。
类型级注意力。给定一个特定的节点 v v v ,类型级注意力学习不同类别邻居的权重。特别地,节点 v v v的类型 τ τ τ 下嵌入表示是 h v τ = ∑ u ∈ N v τ A ~ v , u h u h_v^{\tau}=\sum_{u\in N_v^{\tau}}\tilde{A}_{v,u}h_u hvτ=∑u∈NvτA~v,uhu, N v τ N_v^{\tau} Nvτ是 v v v 的类型 τ τ τ 邻居集合。然后,我们基于节点 v v v 当前嵌入 h v h_v hv 和 h v τ h_v^{\tau} hvτ计算节点 v v v关于类型 τ τ τ 领域的注意力得分: a v τ = σ ( μ τ T [ h v ∣ ∣ h v τ ] ) a_v^{\tau}=\sigma(\mu_{\tau}^T[h_v||h_v^{\tau}]) avτ=σ(μτT[hv∣∣hvτ])其中 || 表示连接, μ τ \mu_{\tau} μτ是类型 τ τ τ 注意力向量(参数),对所有节点共享参数。σ(·)表示激活函数,如Leaky ReLU。
然后,我们通过使用 softmax 函数对所有类型的注意得分进行规范化,获得类型级别的注意权重: α τ = e x p ( a τ ) ∑ τ ′ ∈ T e x p ( a τ ′ ) \alpha_{\tau}=\frac{exp(a_{\tau})}{\sum_{\tau'\in \mathcal{T}}exp(a_{\tau'})} ατ=∑τ′∈Texp(aτ′)exp(aτ)
节点级注意力。我们设计了节点级的注意力,以捕捉不同相邻节点的重要性,并降低噪声节点的权重。进一步表述,给一个类型 τ τ τ 的特定节点 v v v,和其类型为 τ ′ \tau' τ′的邻居 v ′ ∈ N v τ ′ v'\in N_v^{\tau'} v′∈Nvτ′。利用嵌入 h v h_v hv和 h v ′ h_{v'} hv′以及类型级注意力得分 α τ \alpha_{\tau} ατ计算节点 v v v关于 v ′ ∈ N v τ ′ v'\in N_v^{\tau'} v′∈Nvτ′的节点级注意力得分: b v v ′ = σ ( V T ⋅ α τ ′ [ h v ∣ ∣ h v ′ ] ) b_{vv'}=\sigma(V^T\cdot\alpha_{\tau'}[h_v||h_{v'}]) bvv′=σ(VT⋅ατ′[hv∣∣hv′])其中 V V V是注意向量(参数)。然后,我们使用softmax函数将节点级的注意力得分标准化: β v v ′ = e x p ( b v v ′ ) ∑ i ∈ N v e x p ( b v i ) \beta_{vv'}=\frac{exp(b_{vv'})}{\sum_{i\in N_v}exp(b_{vi})} βvv′=∑i∈Nvexp(bvi)exp(bvv′)
最后,我们将包括类型级和节点级注意的双层注意机制改进方程2,引入到异构图卷积中。现在每层之间的传播如下: H ( l + 1 ) = σ ( ∑ τ ∈ T B τ ⋅ H τ ( l ) ⋅ W τ ( l ) ) H^{(l+1)}=\sigma(\sum_{\tau\in\mathcal{T} }\mathcal{B}_{\tau}\cdot H_{\tau}^{(l)}\cdot W_{\tau}^{(l)}) H(l+1)=σ(τ∈T∑Bτ⋅Hτ(l)⋅Wτ(l))其中 B τ \mathcal{B}_{\tau} Bτ是注意力矩阵, ( B τ ) i , j = β i , j (\mathcal{B}_{\tau})_{i,j}=\beta_{i,j} (Bτ)i,j=βi,j。
2.3、模型训练
最后,我们将最后一层的节点(短文本)表示取出来并通过交叉熵来进行训练。需要注意的是,HGAT 是半监督算法,这里的 loss 也是在少量标签数据上计算的。 Z = s o f t m a x ( H ( L ) ) Z=softmax(H^{(L)}) Z=softmax(H(L)) L = − ∑ i ∈ D t r a i n ∑ j = 1 C Y i j ⋅ log Z i j + η ∣ ∣ Θ ∣ ∣ 2 \mathcal{L}=-\sum_{i\in D_{train}}\sum_{j=1}^CY_{ij}\cdot\log Z_{ij}+\eta||\Theta||_2 L=−i∈Dtrain∑j=1∑CYij⋅logZij+η∣∣Θ∣∣2
3、实验
本文在 6 个数据集上进行了大量实验。数据集描述见 Table 1。

Baseline 的选择也较为全面,包括同样将文本数据建模为图的 TextGCN 和异质图神经网络 HAN。对比结果见 Table 2,可以看出本文所提出的 HGAT 有明显的优势。经典的 LSTM 和 CNN 在短文本分类上表现并不好。

另外,本文也测试了 HGAT 的多个变种,如 Table 3 所示。其中,GCN-HIN是将GCN应用于异质图中,不属于该类型的维度上为0;HGAT w/o ATT是去掉双层注意力机制;HGAT-Type只考虑类型级注意力;HGAT-Node只考虑节点级注意力。

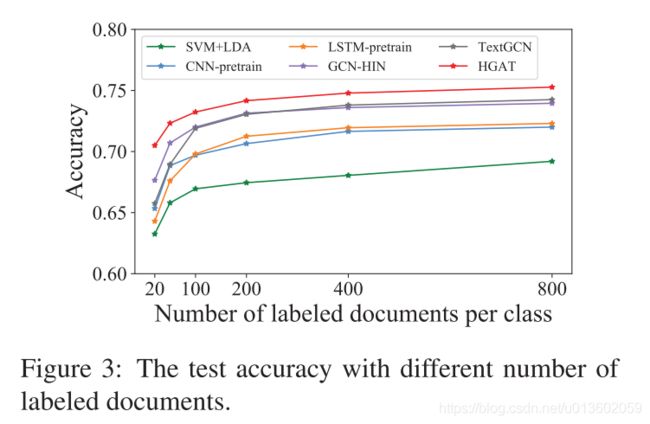
最后,作者也测试标签数量对模型效果的影响,见 Figure 3. 可以看出,随着标签数量的增加,所有模型的表现都有不同程度的提升。
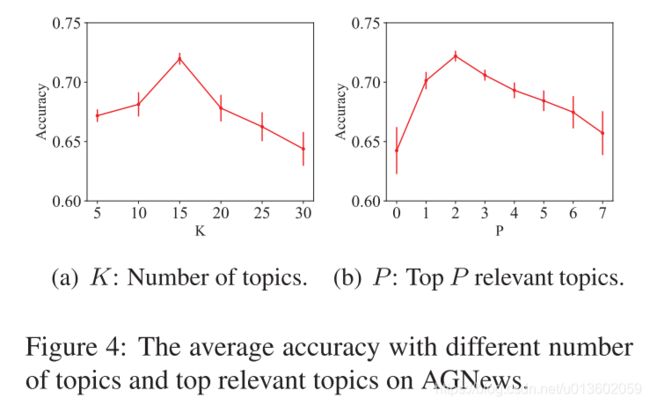
作者也尝试了不同的构图方式对模型的影响,见 Figure 4.
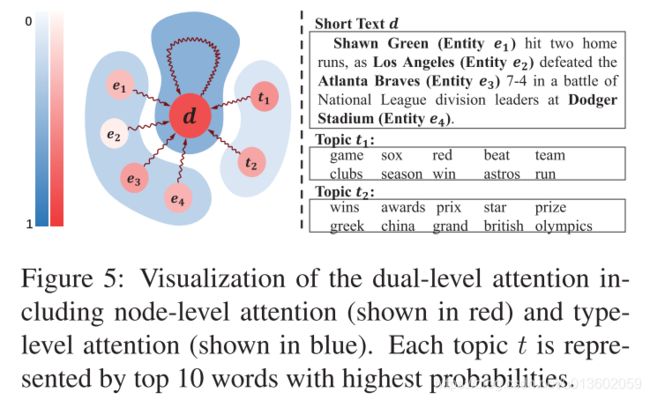
最后,作者通过一个 case study 来说明 attention 的作用,见 Figure 5,颜色越深代表注意力分数越大。受益于注意力机制,HGAT 有较好的可解释性。
4、总结
本文创新地将短文本分类转化为异质图建模来解决数据稀疏和歧义的问题。同时,HGAT 通过层次注意力机制更好的实现了信息聚合,所学习到的短文本的表示更加准确。最后,大量的实验验证了本文所提出算法的有效性。