优秀的python第三方库及安装方法
优秀的python第三方库及安装方法
- 安装第三方库
-
- 用paycharm安装
-
- 方法1
- 方法2
- 用DOS命令安装
-
- 一些DOS命令
- 下载到本地安装
-
- 一些pip指令
- 常用的一些第三方库
-
- 库引用
- pyinstaller库
-
- 常用参数
- jieba库
-
- 常用函数
- wordcloud库
-
- 常用函数
- 配置对象参数
- requests库
-
- HTTP协议
-
- HTTP对协议对资源的操作
- 7个主要方法
-
- requests.request()
- Response对象
- Requests库的异常
- 网页爬取代码
-
- 通用代码框架
- 亚马逊网页爬取
- 爬取百度/360搜索全代码
- 网络图片的爬取和储存
- IP地址归属地判断
- Beautiful Soup库
-
- HTML
- BeautifulSoup类的基本元素
- HTML基本格式
-
- 标签树的下行遍
- 标签树的上行遍历
- 标签树的平行遍历
- bs4库的prettify()方法
安装第三方库
用paycharm安装
方法1
以jieba库为例,如图未安装下面有条红色波浪线,将鼠标移动到jieba上,之后点击Install package jieba,或者使用快捷键Alt+Shift+Enter.

点完后就会在最下方开始默默的下载
![]()
方法2
File—>Settings

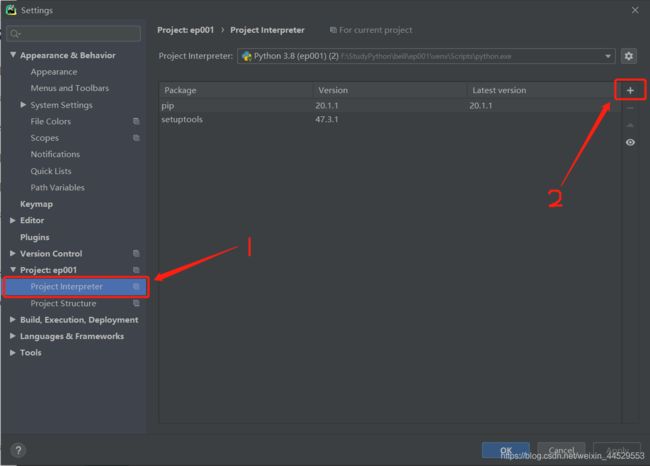
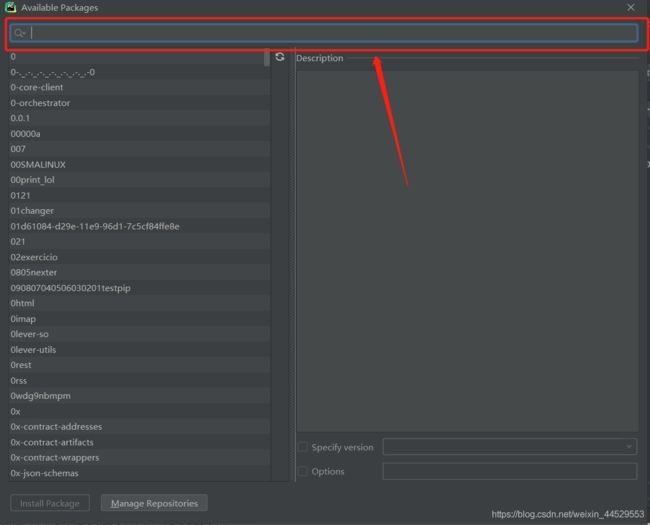
在下图框内搜索相应的库即可
用DOS命令安装
主要方法,适合99%以上情况
windows+r,在跳出窗口输入cmd回车,进入DOS命令窗口,在DOS命令窗口写pip install XXX
DOS命令失败率较高,什么网速不好啊咋的啦就会失败。有时候等半天快好了告诉我失败了……
说到DOS命令,突然想多写一点关于DOS的一些命令
一些DOS命令
| DOS命令 | 描述 |
|---|---|
| ipconfig或ipconfig /all | 可以查看更详细的IP信息,这种查看方式可以看到网卡的物理地址。物理地址具有全球唯一性。是在生产网卡的时候,嵌入的编号。 |
| cls | 清屏 |
| exit | 退出DOS命令窗口 |
| dir(directory) | 查看当前目录下所有的子文件和子目录 |
| cd \ | 直接回到根路径 |
| cd ..(..是一个路径) | 回到上级目录 |
| c: 回车 | 切换盘符 |
| regedit | 打开注册表 |
多说一句相对路径和绝对路径
相对路径:从当前所在的位置作为起点的路径。
绝对路径:从硬盘的根路径(某个磁盘的盘符开始)作为出发点。
下载到本地安装
当以上两种都不行的时候,就只能下载到本地安装了……
去官网https://pypi.org/ (Python Package Index)
搜索完成后点击下载
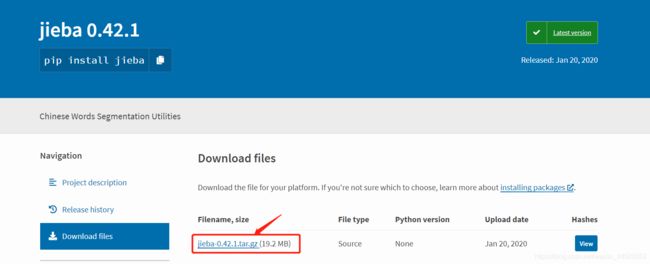
听说都安装到python的安装路径里的site-packages里
![]()
大多数情况得到的源码都是.zip tar.gz tar.zip tar.bz2格式的压缩包。解压这些包,进入文件夹可以看到setup.py的文件,Windows下用Dos命令进行安装。这里以jieba包为例,先到PyPi下载好jieba-0.42.1.tar,这里解压到上述目录后进入该文件夹,在其上输入cmd进入DOS命令窗口。执行:python setup.py install 即可,用此方法安装包时都执行此命令,英文下载的压缩包里有setup.py文件,并且已经进入此包的文件夹中,所以不必写包的名字。
在Python的交互界面送用import 包名,验证是否成功安装,不报错即安装成功。
![]()
若下载的是.whl文件,直接在CMD命令窗口输入pip install然后进入到.whl的所在文件夹,把.whl文件直接拖进去即可,如下面wordcloud库的安装
我安装之后在交互界面可以使用,但是paycharm里面不能使用,经过寻找发现这个博主的文章解决了我的问题:https://blog.csdn.net/mdxiaohu/article/details/82430060
主要是这张图

一些pip指令
| 功能 | 命令 |
|---|---|
| pip自身的升级 | python -m pip install --upgrade pip或py -3 -m pip install --upgrade pip或py -3 -m pip install -U pip |
| pip安装/卸载<第三方库名> | 安装:pip install <第三方库名>卸载: pip uninstall <第三方库名> |
| pip检查哪些软件需要更新 | pip list --outdated |
| pip查看已经安装的<第三方库名> | pip list |
| pip升级软件<第三方库名> | pip install --upgrade <第三方库名>或pip install –U <第三方库名> |
| pip搜索<第三方库名> | pip search <第三方库名> |
| pip查看某个<第三方库名>的详细信息 | pip show <第三方库名> |
| 查看pip版本 | pip.exe -V(V:大写) |
| 查看帮助信息 | pip –h |
| 下载但不安装指定的第三方库 | pip download <第三方库名> |
常用的一些第三方库
库引用
1.import <库名>调用方法:<库名>.<函数名>(<函数参数>)缺点是都是全拼写的很烦
2.from <库名> import <函数名>或from <库名> import *调用方法:<函数名>(<函数参数>),比如turtle.fd()直接就写为fd()优点是简洁,缺点是会出现重名
3.import <库名 > as <库别名 >调用方法:<库别名 >. <函数名 >(< 函数参数>)个人最喜欢这种
pyinstaller库
功能:将.py源代码转换成无需源代码的可执行文件
常用参数
| 参数 | 描述 |
|---|---|
| -h | 查看帮助 |
| –clean | 清理打包过程中的临时文件 |
| -D,–onedir | 默认值,生成dist文件夹 |
| -F,–onefile | 在dist文件夹中只生成独立的打包文件 |
| -i<图标文件名.ico> | 指定打包程序使用的图标(icon)文件 |
一般用:(cmd命令行) pyinstaller-F <文件名.py>
jieba库
jieba是优秀的中文分词第三方库
-精确模式:把文本精确的切分开,不存在冗余单词
-全模式:把文本中所有可能的词语都扫描出来,有冗余
-搜索引擎模式:在精确模式基础上,对长词再次切分
常用函数
| 函数 | 描述 |
|---|---|
| jieba.lcut(s) | 精确模式,返回一个列表类型的分词结果>>>jieba.lcut("中国是一个伟大的国家")['中国', '是', '一个', '伟大', '的', '国家'] |
| jieba.lcut(s, cut_all=True) | 全模式,返回一个列表类型的分词结果,存在冗余>>>jieba.lcut("中国是一个伟大的国家",cut_all=True) ['中国', '国是', '一个', '伟大', '的', '国家'] |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型的分词结果,存在冗余>>>jieba.lcut_for_search(“中华人民共和国是伟大的")['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的'] |
| jieba.add_word(w) | 向分词词典增加新词w>>>jieba.add_word("蟒蛇语言") |
wordcloud库
wordcloud是优秀的词云展示第三方库,可以根据文本中词语出现的频率等参数绘制词云,就是经常看到的下图这个东西

![]()
第一次尝试安装失败,显示还得配置C++环境……学习编程环境配置占了一一半时间这话真没说错。
然后看嵩老师视频发现居然有“可以直接下载编译后的版本用于安装”的方法,当然并不是所有的都行,某些吧。
方法如下,以安装wordcloud库为例。
- (Windows)进入UCI页面http://www.lfd.uci.edu/~gohlke/pythonlibs/

- 按ctrl + F搜索wordcloud

4. 选择对应的版本下载,我用的是python3.8,32位

如何查看python是32位还是64位:
①DOS命令直接输入python

②python交互环境中输入代码,如果是4,说明是32位的;如果是其他的是,64位的。struct.calcsize用于计算格式字符串所对应的结果长度。
来自博客http://blog.csdn.net/waleking/article/details/7566842
>>> import struct
>>> struct.calcsize("P")
- 下载完成后使用
pip install <路径+文件名>安装
可以直接pip install然后就把文件拖到命令框中就行了

安装成功

常用函数
| 方法 | 描述 |
|---|---|
| w.generate(txt) | 向WordCloud对象w中加载文本txt>>>w.generate("Python and WordCloud") |
| w.to_file(filename) | 将词云输出为图像文件,.png或.jpg格式>>>w.to_file("outfile.png") |
配置对象参数
w = wordcloud.WordCloud(<参数>)
| 参数 | 描述 |
|---|---|
| width | 指定词云对象生成图片的宽度,默认400像素>>>w=wordcloud.WordCloud(width=600) |
| height | 指定词云对象生成图片的高度,默认200像素>>>w=wordcloud.WordCloud(height=400) |
| min_font_size | 指定词云中字体的最小字号,默认4号>>>w=wordcloud.WordCloud(min_font_size=10) |
| max_font_size | 指定词云中字体的最大字号,根据高度自动调节>>>w=wordcloud.WordCloud(max_font_size=20) |
| font_step | 指定词云中字体字号的步进间隔,默认为1>>>w=wordcloud.WordCloud(font_step=2) |
| font_path | 指定字体文件的路径,默认None>>>w=wordcloud.WordCloud(font_path="msyh.ttc") |
| max_words | 指定词云显示的最大单词数量,默认200>>>w=wordcloud.WordCloud(max_words=20) |
| stop_words | 指定词云的排除词列表,即不显示的单词列表>>>w=wordcloud.WordCloud(stop_words={"Python"}) |
| mask | 指定词云形状,默认为长方形,需要引用imread()函数from scipy.miscimport imread>>>mk=imread("pic.png")>>>w=wordcloud.WordCloud(mask=mk) |
| background_color | 指定词云图片的背景颜色,默认为黑色>>>w=wordcloud.WordCloud(background_color="white") |
requests库
HTTP协议
HTTP,Hypertext Transfer Protocol,超文本传输协议,HTTP是一个基于“请求与响应”模式的、无状态的应用层协议,HTTP协议采用URL作为定位网络资源的标识,URL格式如下:http://host[:port][path]
host: 合法的Internet主机域名或IP地址
port: 端口号,缺省端口为80
path: 请求资源的路径
HTTP URL实例:
http://www.bit.edu.cn 北京理工大学教育网首页
http://220.181.111.188/duty这样一台IP主机上duty目录下的相关资源
HTTP对协议对资源的操作
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息(若资源很大的话) |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源(注意会全部覆盖) |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容(优点:节省带宽) |
| DELETE | 请求删除URL位置存储的资源 |
7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request(method, url, **kwargs) | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get(url, params=None, **kwargs) | 获取HTML网页的主要方法,对应于HTTP的GET.url : 拟获取页面的url链接,params : url中的额外参数,字典或字节流格式,可选,**kwargs: 12个控制访问的参数 |
| requests.head(url, **kwargs) | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post(url, data=None, json=None, **kwargs) | 向HTML网页提交POST请求的方法,对应于HTTP的POST。url : 拟更新页面的url链接 |
| requests.put(url, data=None, **kwargs) | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch(url, data=None, **kwargs) | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete(url, **kwargs) | 向HTML页面提交删除请求,对应于HTTP的DELETE |
requests.request()
requests.request(method, url, **kwargs)
method : 请求方式,对应get/put/post等7种,第七种是Option用的较少
url : 拟获取页面的url链接
**kwargs: 控制访问的参数,共13个,均为可选项
params : 字典或字节序列,作为参数增加到url中
data : 字典、字节序列或文件对象,作为Request的内容
json : JSON格式的数据,作为Request的内容
headers : 字典,HTTP定制头
cookies : 字典或CookieJar,Request中的cookie
auth : 元组,支持HTTP认证功能
files : 字典类型,传输文件
timeout : 设定超时时间,秒为单位
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects : True/False,默认为True,重定向开关
stream : True/False,默认为True,获取内容立即下载开关
verify : True/False,默认为True,认证SSL证书开关
cert : 本地SSL证书路径
Response对象
Response对象包含服务器返回的所有信息,也包含请求的Request信息
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404(不是200)表示失败 |
| r.text HTTP | 响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式(根据r.encoding显示网页内容) |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content HTTP | 响应内容的二进制形式 |
| r.raise_for_status() | 如果不是200,产生异常requests.HTTPError |
r.raise_for_status()在方法内部判断r.status_code是否等于200,不需要
增加额外的if语句,该语句便于利用try‐except进行异常处理
Requests库的异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
网页爬取代码
通用代码框架
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPEorror异常
r.encoding = r.apparent_encoding #用备用编码代替
return r.text
except:
return "产生异常"
测试:
>>> url = "www.baidu.com"
>>> print(getHTMLText(url))
产生异常
>>> url = "https://www.baidu.com"
>>> print(getHTMLText(url))
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css
......
亚马逊网页爬取
网址:https://www.amazon.cn/gp/product/B01M8L5Z3Y
当使用通用代码框架进行爬取时会发现r_status_code返回是503,说明爬取失败,查看一下发给亚马逊网址的头部信息如下:
>>> r.request.headers
{
'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
我们发现User-Agent是’python-requests/2.24.0’,说明python忠实的告诉亚马逊这是由一个python的requests库的程序产生从而来访问的,亚马逊应该是不支持这个访问的。那么怎么解决呢,修改下头部信息就ok了呗,改成’Mozilla/5.0’。这是一个标准的浏览器身份标识符的字段。总体代码如下
>>> import requests
>>> url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y"
>>> try:
kv={
'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
爬取百度/360搜索全代码
百度的关键词接口:http://www.baidu.com/s?wd=keyword
360的关键词接口:http://www.so.com/s?q=keyword
# 爬取360搜索,关键词为Python,若要百度的话把q改成wd,然后网址换成百度的就可以了,若要返回网址为http://www.baidu.com/s?wd=keyword,还需要更改发送给百度网页的头部信息,让他以为是一个浏览器发送的
#r = requests.get("http://www.baidu.com/s",params=kv,headers = kt) kt={'user-agent':'Mozilla/5.0'}
>>>import requests
>>>keyword = "Python"
>>> try:
kv={
'q':keyword}
r = requests.get("http://www.so.com/s",params=kv)
print(r.request.url)# 注意这里是request不是requests
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
https://www.so.com/s?q=Python
464488
网络图片的爬取和储存
网络图片链接的格式:http://www.example.com/picture.jpg(最后是.+图片格式,png也是),至于如何获得图片链接,点击图片右键->复制图片网址即可
>>>import requests
>>> import os
>>> import os
>>> url = "http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg"
>>> root = "D://xiazai//"#文件根目录
>>> path = root + url.split('/')[-1]#文件路径(根目录+url最后一个斜杠后de bufen ),并将文件命名为最后一个斜杠后的名字
>>> try:
if not os.path.exists(root):#判断根目录是否存在
os.mkdir(root)#若不存在,创造一个
if not os.path.exists(path):#判断文件是否存在
r = requests.get(url)#若不存在,开始爬取
with open(path,'wb') as f:#打开要存储的图片文件,并把它定义为一个文件标识符f
f.write(r.content)#将返回的内容以二进制形式写入文件f中
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
IP地址归属地判断
查询网址:https://www.ip138.com/
小技巧:尝试输入一个ip地址,点击查询,观察浏览器网址变化,比如通过这个网址提交之后是这样的网址:https://www.ip138.com/iplookup.asp?ip=ipaddress&action=2,说明他是通过ip=ipaddress这个参数将ip提交到前面的网页中,这个网页根据这个参数返回一个内容,就是ip地址归属地。
代码如下:(为了防止反爬虫,建议都把headers改一下把,一般访问不了或者返回的很奇葩可能都是这个原因,要让他以为是正常的浏览器访问的)
>>> import requests
>>> url ="https://www.ip138.com/iplookup.asp?ip="
>>> try:
kv = {
'user-agent':'Mozilla/5.0'}
r = requests.get(url+'202.204.80.112'+'&action=2',headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])#若爬取的text太大会导致idle失效,所以建议尽量约束一个返回的范围空间
except:
print("爬取失败")
Beautiful Soup库
Beautiful Soup库,也叫beautifulsoup4 或bs4,执行pip install beautifulsoup4安装
引用方法:from bs4 import BeautifulSoup或import bs4
HTML
超级文本标记语言(Hyper Text Markup Language,HTML),是WWW(World Wide Web)的信息组织方式,能够将声音,图像,信息能超文本的内容嵌入到文本中。HTML通过预定义的<>…标签形式组织不同类型的信息。
BeautifulSoup类的基本元素

| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和标明开头和结尾,当HTML文档中存在多个相同soup.返回第一个 |
| Name | 标签的名字, |
| Attributes | 标签的属性,字典形式组织,格式: |
| NavigableString | 标签内非属性字符串,<>…中字符串,格式: |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
HTML基本格式
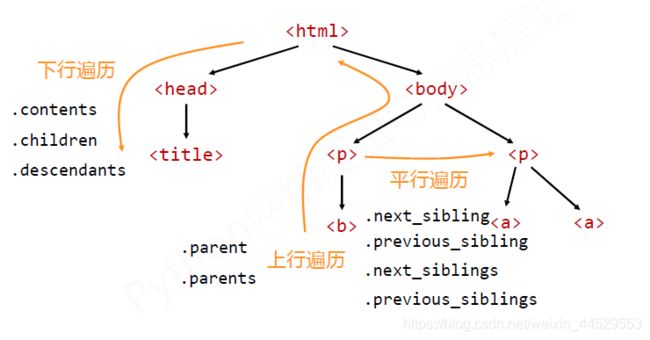
标签树的下行遍
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将< tag>所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
标签树的平行遍历
平行遍历发生在同一个父节点下的各节点间,比如上图head下的title和body下的p就不是平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
bs4库的prettify()方法
.prettify()为HTML文本<>及其内容增加更加’\n’
.prettify()可用于标签,方法: