word2vec模型原理(一):基于哈夫曼树的word2vec
在nlp领域,文本词的向量表示往往是第一步,笔者在做一些推荐相关性的工作中也用到了其中很常见的word2vec模型,因此也具体学习了一下word2vec的具体实现原理,本文主要参考了github开源的c语言版的word2vec源码以及相关的博客。
一、要解决的问题
对于语料中的每一个词,最简单的表达方式就是one-hot,即利用位数编码的方式每个词占据一个“1”位,其余为0,。这样做虽然简单,但由于工业上语料往往非常大,词语很多时候会达到百万甚至更多,对于单个词而言百万级别的维度表达显然是效率不高的,因此,目前往往都会使用word embedding的方式将词降维压缩至可计算的维度。这个降维的过程有很多实现的方式,今天就来探讨一下其中目前最火的神经网络语言模型-word2vec。
二、CBOW与Skip-Gram
在word2vev中,对于数据的训练目标而言有两种方式:CBOW和Skip-Gram。CBOW表示基于上下文来预测目标词,即输入是2c个上下文词(c表示窗口大小),输出是目标词的概率;Skip-Gram则是恰恰相反,输入是当前的目标词,输出则是上下文词的概率。
在确定了输入输出之后,其实训练的方式也就很明显了,(例如CBOW)输入层经过隐藏层最后softmax输出所有词的概率,然后反向传播梯度下降decrease loss。但这其中有一个很大的问题:从隐藏层到输出的softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值。这样的性能显然是对于一个embedding操作来讲是得不偿失的,因此,word2vec对这里做了很精妙的优化,本文首先来介绍基于哈夫曼树的word2vec。
三、基于哈夫曼树的word2vec
在word2vec中,利用哈夫曼树来模拟隐层到输出层的学习过程。word2vec对这个模型做了改进,首先,对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入词向量求和并取平均的方法。比如输入的是窗口为2的4维词向量:(1,2,3),(9,6,11),(5,10,7)(1,2,3)那么我们word2vec映射后的词向量就是(1,5,6)。由于我们把之前所有都要计算的从输出softmax层的概率计算变成了一颗二叉霍夫曼树,那么我们的softmax概率计算只需要沿着树形结构进行就可以了。
和之前的神经网络语言模型相比,我们的哈夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元,其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在这个模型中,隐藏层到输出层的映射就是通过哈夫曼树的向下搜索逐步完成的,接下来我们来讨论具体的算法。
四、基于哈夫曼树的CBOW模型
如下图所示,我们可以沿着霍夫曼树从根节点一直走到我们的叶子节点的目标词,其中,根节点就是简单求和平均后的词向量。

由哈夫曼树的建树规则不难知道,每个叶子节点代表一个目标词,同时每个目标词也有一条路径代表了其编码规则。在word2vec中,我们采用逻辑回归的方法,规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,对于n1-n2-n3-n4这条路径来讲,神经网络训练的目标就是要让走这条路径的可能性最大,这里我们可以先给出似然函数:

这里的似然函数其实就是对每一步的sigmoid求积,而我们的目标就是让这个概率最大,即通过最大似然的方式来优化这个函数。为了给出其一般过程,我们首先做一些定义:
![]() :输入向量求和平均之后的向量;
:输入向量求和平均之后的向量;
![]() :对于目标词w,第i个编码(节点)的模型参数;
:对于目标词w,第i个编码(节点)的模型参数;
![]() :对于目标词w,第i个编码(节点)的哈夫曼取值(0或1);
:对于目标词w,第i个编码(节点)的哈夫曼取值(0或1);
![]() :对于目标词w,哈夫曼编码的最大节点数
:对于目标词w,哈夫曼编码的最大节点数
由逻辑回归及最大似然的定义,对于任意目标词词w而言,其最大似然表示为:

在word2vec中,由于使用的是随机梯度上升法,所以并没有把所有样本的似然乘起来得到真正的训练集最大似然,仅仅每次只用一个样本更新梯度,这样做的目的是减少梯度计算量。这样我们可以得到对数似然函数L如下:

接下来,我们就可以借助梯度上升求解最大似然的参数,详细步骤如下:
首先,对于sigmoid函数有:
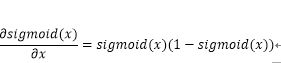
基于此,

在word2vec中,x向量同样可以看作需要优化的模型参数,因此同样对于x:

接下来,我们就给出基于哈夫曼树的CBOW的word2vec的具体步骤:

五、基于哈夫曼树的Skip-Gram模型
之前有提到,Skip-Gram和CBOW最大的区别就是表达模型输入输出的方式,对于Skip-Gram来说,训练的任务则变成了由目标词向量预估上下文的2c个词。明白了过程之后,我们就可以来详细说明训练过程。首先说明一点,按照正常情况,最终的预估结果会是已知目标词,求上下文的条件概率,即P(x[上下文] | x[目标词]),但在word2vec的实现中,认为最终求解P(x[目标词] | x[上下文])的方式是等价的;同时,这样能更新的词语有2c个,有助于模型学习的更加充分。有了CBOW的推导,这里我们就直接给出Skip-Gram的具体训练方式:

本文到此是详细分析了word2Vec的基于哈夫曼树的训练过程,之后笔者将会简要分析基于负采样的word2vec的具体实现。