一 Flink集群搭建部署
1.1本地模式部署
1.1.1 将压缩包解压
[root@master root]# tar -zxvf flink-1.9.1-bin-scala_2.11.tgz -C /usr/local/
积分下载地址:
1.1.2 创建软连接(文件名太长操作不方便,就是改个名)
[root@master local]# ln -s flink-1.9.1/ flink
1.1.3 配置环境变量
[root@master local]# vim /etc/profile
在文件末尾加两行:
export FLINK_HOME=/usr/local/flink
export PATH=$PATH:$FLINK_HOME/bin
使环境变量生效:
source /etc/profile
测试:
[root@master ~]# flink --version
Version: 1.9.1, Commit ID: 4d56de8
1.1.4 启动本地模式
[root@master ~]# start-cluster.sh
测试:
[root@master ~]# jps
15429 Jps
12823 StandaloneSessionClusterEntrypoint
13261 TaskManagerRunner
浏览器访问(http://master:8081)

1.1.5 关闭本地模式
[root@master ~]# stop-cluster.sh
1.2 standalone模式部署(在本地模式部署基础之上搭建)
1.2.1 修改flink/conf目录下的master slaves 文件(ip映射)
[root@master flink]# vim conf/masters
master:8081
[root@master flink]# vim conf/slaves
slave1
slave2
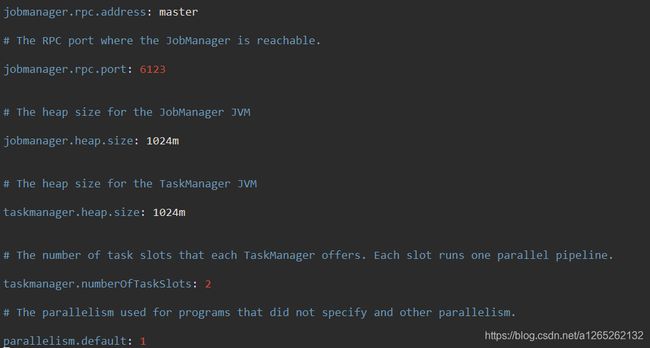
1.2.2修改flink/conf目录下flink-conf.yaml 文件
1.2.3 将配置好的flink文件同步到另外两个节点
[root@master local]# scp -r flink-1.9.1/ root@slave1:/usr/local/
[root@master local]# scp -r flink-1.9.1/ root@slave2:/usr/local/
注意点:没必要在slave上配置环境变量,我把启动脚本debug后发现,当master通过ssh免密登录到slave上启动脚本的时候,寻找的路径不是通过slave上的环境变量,而是通过master获得的路径加上固定的文件名,也就是说分发到slave上flink-1.9.1这个文件名不能改,即使改了配置了环境变量也启动不起来,我就是因为这个把启动过程的脚本debug了一边,而且其他软件的安装好像都遵循这个规则:分发过去的文件名不能改。
1.2.4 启动测试(免密登录前提必须配置好)
[root@master ~]# start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host master.
Starting taskexecutor daemon on host slave1.
Starting taskexecutor daemon on host slave2.
浏览器访问(http://master:8081)

1.3 搭建HA(要求HadoopHA,YarnHA,zookeeper集群部署完成)
1.3.1 修改配置文件flink-conf.yaml,masters,slaves
##### masters
master:8081
slave1:8081
##### slaves
slave1
slave2
##### flink-conf.yaml(增加HA配置)
high-availability: zookeeper
high-availability.storageDir: hdfs:///cluster/flink/ha/ //cluster是你Hadoop高可用hdfs入口
high-availability.zookeeper.quorum: master:2181,slave1:2181,slave2:2181
high-availability.zookeeper.client.acl: open
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_one
1.3.2 同步文件
[root@master local]# scp -r flink-1.9.1/ root@slave1:/usr/local/
[root@master local]# scp -r flink-1.9.1/ root@slave2:/usr/local/
修改slave1上的jobmanager.rpc.address= slave1
1.3.3 测试(先启动Hadoop,zookeeper集群)
[root@master ~]# start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host master.
Starting standalonesession daemon on host slave1.
Starting taskexecutor daemon on host slave1.
Starting taskexecutor daemon on host slave2.
1.4 Flink on Yarn(yarn session 和 flink run 两种模式)
这只是两种启动模式,不需要进行配置,直接执行命令即可。
1.4.1 yarn session
1.4.1.1 介绍
这种方式需要先向yarn申请一块空间后,再提交作业,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交,这种方式资源被限制在session中,不能超过,比较适合特定的运行环境或者测试环境。
1.4.1.2 启动 yarn session
1.启动开启yarn的Hadoop集群和zookeeper
2.向yarn申请一块资源:
[root@master conf]# yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test
其中:
-n(–container):TaskManager的数量。
-s(–slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个 taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。
我在运行的时候查看日志文件发现三个问题,都是Hadoop中yarn-site.xml缺省配置参数:
yarn.log-aggregation-enable
true
yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds
3600
yarn.nodemanager.remote-app-log-dir
/tmp/logs
yarn.nodemanager.resource.memory-mb
16384
yarn.scheduler.minimum-allocation-mb
1024
yarn.scheduler.maximum-allocation-mb
16384
yarn.nodemanager.vmem-check-enabled
false
注意点:如果配置完还出现问题,你的yarn-site.xml中resourcemanager可能设置在了主节点,新开的服务都在这个节点运行,内存爆了,把resourcemanager设置在其他节点,或者增大主节点的内存。
启动后的进程:
---------{ master }----------------------------------------
6564 NameNode
98756 FlinkYarnSessionCli
8005 DFSZKFailoverController
99655 Jps
9289 ResourceManager
6937 JournalNode
7631 QuorumPeerMain
---------{ slave1 }----------------------------------------
79955 YarnSessionClusterEntrypoint
5669 DFSZKFailoverController
4438 JournalNode
4264 DataNode
4665 NodeManager
80381 Jps
5054 QuorumPeerMain
4143 NameNode
5903 ResourceManager
---------{ slave2 }----------------------------------------
74833 Jps
4819 QuorumPeerMain
4230 JournalNode
4428 NodeManager
4060 DataNode
注意点:FlinkYarnSessionCli只有在前台运行的时候不会关闭,加了-d后台启动完成后这个进程就会关闭。YarnSessionClusterEntrypoint会和ResourceManager在同一个节点启动,如果这些服务在一个节点启动,内存得2.5g以上。
浏览器访问http://master:8088
1.4.2 flink run
1.4.2.1 介绍
这种方式的好处是一个任务会对应一个job,即没提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。一般生产环境是采用此种方式运行。这种方式就需要确保集群资源足够。
flink run的HA运用的是standalone里的配置信息,所以不需要再配
1.4.2.2 启动 flink run
flink run -m yarn-cluster -yn 2 -c 类名 -d 包名 参数
常用的配置有:
● -yn,--yarncontainer Number of Task Managers
● -yqu,--yarnqueue Specify YARN queue.
● -ys,--yarnslots Number of slots per TaskManager
1.5 Yarn session HA(前提: Yarn HA)
1.5.1 修改yarn-site.xml
yarn.resourcemanager.am.max-attempts
4
配置提交的应用程序最大的尝试的次数
1.5.2 修改flink-conf.yaml
high-availability: zookeeper high-availability.zookeeper.quorum: master:2181, slave1:2181, slave2:2181
high-availability.storageDir: hdfs://cluster/flink/ha-yarn
high-availability.zookeeper.path.root: /flink-yarn
yarn.application-attempts: 4
1.5.3 同步文件
[root@master local]# scp -r flink-1.9.1/ root@slave1:/usr/local/
[root@master local]# scp -r flink-1.9.1/ root@slave2:/usr/local/
修改slave1上的jobmanager.rpc.address= slave1